Artificial Intelligence
Recommend and dynamically filter items based on user context in Amazon Personalize
Organizations are continuously investing time and effort in developing intelligent recommendation solutions to serve customized and relevant content to their users. The goals can be many: transform the user experience, generate meaningful interaction, and drive content consumption. Some of these solutions use common machine learning (ML) models built on historical interaction patterns, user demographic attributes, product similarities, and group behavior. Besides these attributes, context (such as weather, location, and so on) at the time of interaction can influence users’ decisions while navigating content.
In this post, we show how to use the user’s current device type as context to enhance the effectiveness of your Amazon Personalize-based recommendations. In addition, we show how to use such context to dynamically filter recommendations. Although this post shows how Amazon Personalize can be used for a video on demand (VOD) use case, it’s worth noting that Amazon Personalize can be used across multiple industries.
What is Amazon Personalize?
Amazon Personalize enables developers to build applications powered by the same type of ML technology used by Amazon.com for real-time personalized recommendations. Amazon Personalize is capable of delivering a wide array of personalization experiences, including specific product recommendations, personalized product reranking, and customized direct marketing. Additionally, as a fully managed AI service, Amazon Personalize accelerates customer digital transformations with ML, making it easier to integrate personalized recommendations into existing websites, applications, email marketing systems, and more.
Why is context important?
Using a user’s contextual metadata such as location, time of day, device type, and weather provides personalized experiences for existing users and helps improve the cold-start phase for new or unidentified users. The cold-start phase refers to the period when your recommendation engine provides non-personalized recommendations due to the lack of historical information regarding that user. In situations where there are other requirements to filter and promote items (say in news and weather), adding a user’s current context (season or time of day) helps improve accuracy by including and excluding recommendations.
Let’s take the example of a VOD platform recommending shows, documentaries, and movies to the user. Based on behavior analysis, we know VOD users tend to consume shorter-length content like sitcoms on mobile devices and longer-form content like movies on their TV or desktop.
Solution overview
Expanding on the example of considering a user’s device type, we show how to provide this information as context so that Amazon Personalize can automatically learn the influence of a user’s device on their preferred types of content.
We follow the architecture pattern shown in the following diagram to illustrate how context can automatically be passed to Amazon Personalize. Automatically deriving context is achieved through Amazon CloudFront headers that are included in requests such as a REST API in Amazon API Gateway that calls an AWS Lambda function to retrieve recommendations. Refer to the full code example available at our GitHub repository. We provide a AWS CloudFormation template to create the necessary resources.
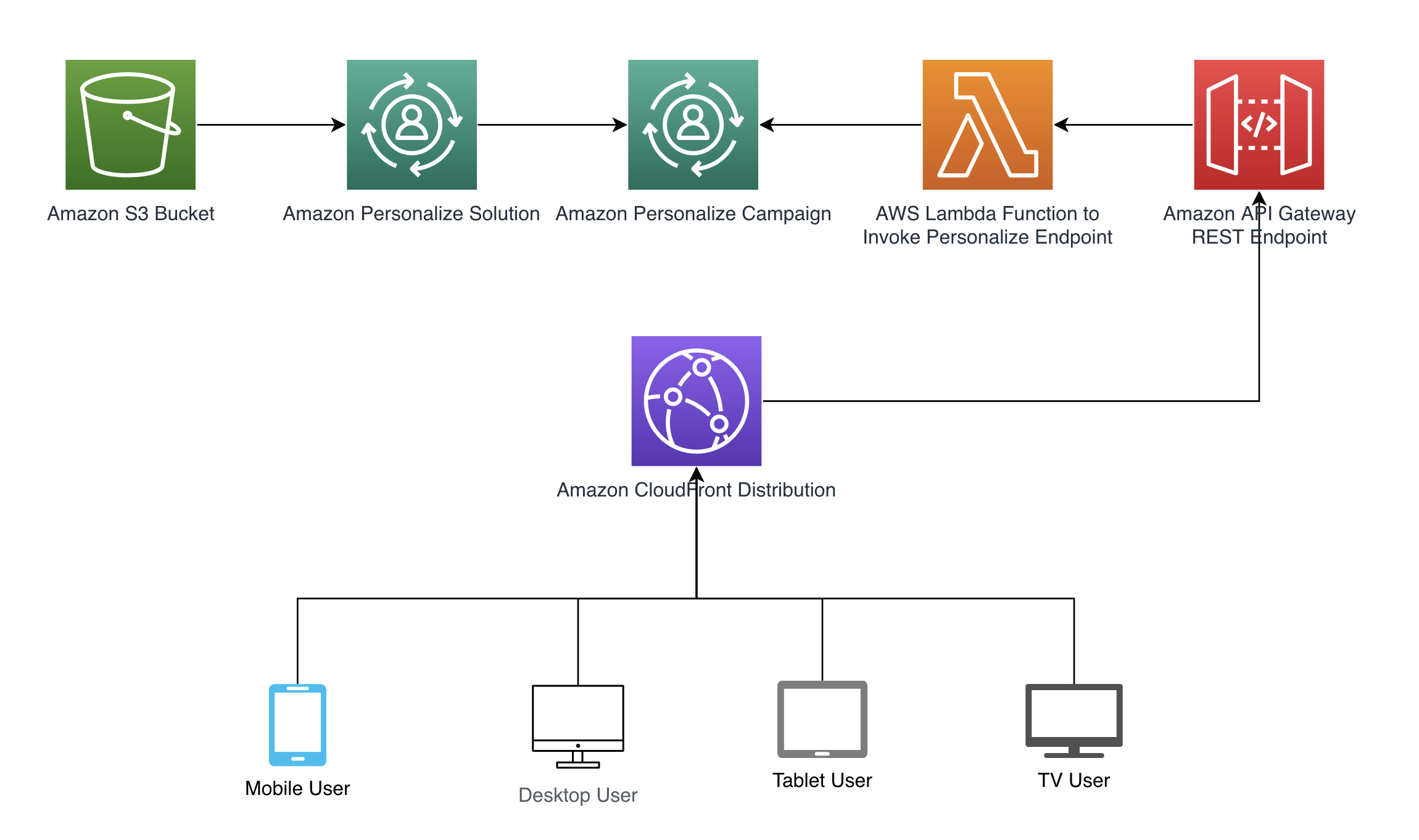
In following sections, we walk through how to set up each step of the sample architecture pattern.
Choose a recipe
Recipes are Amazon Personalize algorithms that are prepared for specific use cases. Amazon Personalize provides recipes based on common use cases for training models. For our use case, we build a simple Amazon Personalize custom recommender using the User-Personalization recipe. It predicts the items that a user will interact with based on the interactions dataset. Additionally, this recipe also uses items and users datasets to influence recommendations, if provided. To learn more about how this recipe works, refer to User-Personalization recipe.
Create and import a dataset
Taking advantage of context requires specifying context values with interactions so recommenders can use context as features when training models. We also have to provide the user’s current context at inference time. The interactions schema (see the following code) defines the structure of historical and real-time users-to-items interaction data. The USER_ID, ITEM_ID, and TIMESTAMP fields are required by Amazon Personalize for this dataset. DEVICE_TYPE is a custom categorical field that we are adding for this example to capture the user’s current context and include it in model training. Amazon Personalize uses this interactions dataset to train models and create recommendation campaigns.
Similarly, the items schema (see the following code) defines the structure of product and video catalog data. The ITEM_ID is required by Amazon Personalize for this dataset. CREATION_TIMESTAMP is a reserved column name but it is not required. GENRE and ALLOWED_COUNTRIES are custom fields that we are adding for this example to capture the video’s genre and countries where the videos are allowed to be played. Amazon Personalize uses this items dataset to train models and create recommendation campaigns.
In our context, historical data refers to end-user interaction history with videos and items on the VOD platform. This data is usually gathered and stored in application’s database.
For demo purposes, we use Python’s Faker library to generate some test data mocking the interactions dataset with different items, users, and device types over a 3-month period. After the schema and input interactions file location are defined, the next steps are to create a dataset group, include the interactions dataset within the dataset group, and finally import the training data into the dataset, as illustrated in the following code snippets:
Gather historical data and train the model
In this step, we define the chosen recipe and create a solution and solution version referring to the previously defined dataset group. When you create a custom solution, you specify a recipe and configure training parameters. When you create a solution version for the solution, Amazon Personalize trains the model backing the solution version based on the recipe and training configuration. See the following code:
Create a campaign endpoint
After you train your model, you deploy it into a campaign. A campaign creates and manages an auto-scaling endpoint for your trained model that you can use to get personalized recommendations using the GetRecommendations API. In a later step, we use this campaign endpoint to automatically pass the device type as a context as a parameter and receive personalized recommendations. See the following code:
Create a dynamic filter
When getting recommendations from the created campaign, you can filter results based on custom criteria. For our example, we create a filter to satisfy the requirement of recommending videos that are only allowed to be played from user’s current country. The country information is passed dynamically from the CloudFront HTTP header.
Create a Lambda function
The next step in our architecture is to create a Lambda function to process API requests coming from the CloudFront distribution and respond by invoking the Amazon Personalize campaign endpoint. In this Lambda function, we define logic to analyze the following CloudFront request’s HTTP headers and query string parameters to determine the user’s device type and user ID, respectively:
CloudFront-Is-Desktop-ViewerCloudFront-Is-Mobile-ViewerCloudFront-Is-SmartTV-ViewerCloudFront-Is-Tablet-ViewerCloudFront-Viewer-Country
The code to create this function is deployed through the CloudFormation template.
Create a REST API
To make the Lambda function and Amazon Personalize campaign endpoint accessible to the CloudFront distribution, we create a REST API endpoint set up as a Lambda proxy. API Gateway provides tools for creating and documenting APIs that route HTTP requests to Lambda functions. The Lambda proxy integration feature allows CloudFront to call a single Lambda function abstracting requests to the Amazon Personalize campaign endpoint. The code to create this function is deployed through the CloudFormation template.
Create a CloudFront distribution
When creating a CloudFront distribution, because this is a demo setup, we disable caching using a custom caching policy, ensuring the request goes to the origin every time. Additionally, we use an origin request policy specifying the required HTTP headers and query string parameters that are included in an origin request. The code to create this function is deployed through the CloudFormation template.
Test recommendations
When the CloudFront distribution’s URL is accessed from different devices (desktop, tablet, phone, and so on), we can see personalized video recommendations that are most relevant to their device. Also, if a cold user is presented, the recommendations tailored for user’s device are presented. In the following sample outputs, names of videos are only used for representation of their genre and runtime to make it relatable.
In the following code, a known user who loves comedy based on past interactions and is accessing from a phone device is presented with shorter sitcoms:
The following known user is presented with feature films when accessing from a smart TV device based on past interactions:
A cold (unknown) user accessing from a phone is presented with shorter but popular shows:
Recommendations for user: 666 ITEM_ID GENRE ALLOWED_COUNTRIES 940 Satire US|FI|CN|ES|HK|AE 760 Satire US|FI|CN|ES|HK|AE 160 Sitcom US|FI|CN|ES|HK|AE 880 Comedy US|FI|CN|ES|HK|AE 360 Satire US|PK|NI|JM|IN|DK 840 Satire US|PK|NI|JM|IN|DK 420 Satire US|PK|NI|JM|IN|DK
A cold (unknown) user accessing from a desktop is presented with top science fiction films and documentaries:
The following known user accessing from a phone is returning filtered recommendations based on location (US):
Conclusion
In this post, we described how to use user device type as contextual data to make your recommendations more relevant. Using contextual metadata to train Amazon Personalize models will help you recommend products that are relevant to both new and existing users, not just from the profile data but also from a browsing device platform. Not only that, context like location (country, city, region, postal code) and time (day of the week, weekend, weekday, season) opens up the opportunity to make recommendations relatable to the user. You can run the full code example by using the CloudFormation template provided in our GitHub repository and cloning the notebooks into Amazon SageMaker Studio.
About the Authors
 Gilles-Kuessan Satchivi
is an AWS Enterprise Solutions Architect with a background in networking, infrastructure, security, and IT operations. He is passionate about helping customers build Well-Architected systems on AWS. Before joining AWS, he worked in ecommerce for 17 years. Outside of work, he likes to spend time with his family and cheer on his children’s soccer team.
Gilles-Kuessan Satchivi
is an AWS Enterprise Solutions Architect with a background in networking, infrastructure, security, and IT operations. He is passionate about helping customers build Well-Architected systems on AWS. Before joining AWS, he worked in ecommerce for 17 years. Outside of work, he likes to spend time with his family and cheer on his children’s soccer team.
 Aditya Pendyala is a Senior Solutions Architect at AWS based out of NYC. He has extensive experience in architecting cloud-based applications. He is currently working with large enterprises to help them craft highly scalable, flexible, and resilient cloud architectures, and guides them on all things cloud. He has a Master of Science degree in Computer Science from Shippensburg University and believes in the quote “When you cease to learn, you cease to grow.”
Aditya Pendyala is a Senior Solutions Architect at AWS based out of NYC. He has extensive experience in architecting cloud-based applications. He is currently working with large enterprises to help them craft highly scalable, flexible, and resilient cloud architectures, and guides them on all things cloud. He has a Master of Science degree in Computer Science from Shippensburg University and believes in the quote “When you cease to learn, you cease to grow.”
 Prabhakar Chandrasekaran is a Senior Technical Account Manager with AWS Enterprise Support. Prabhakar enjoys helping customers build cutting-edge AI/ML solutions on the cloud. He also works with enterprise customers providing proactive guidance and operational assistance, helping them improve the value of their solutions when using AWS. Prabhakar holds six AWS and six other professional certifications. With over 20 years of professional experience, Prabhakar was a data engineer and a program leader in the financial services space prior to joining AWS.
Prabhakar Chandrasekaran is a Senior Technical Account Manager with AWS Enterprise Support. Prabhakar enjoys helping customers build cutting-edge AI/ML solutions on the cloud. He also works with enterprise customers providing proactive guidance and operational assistance, helping them improve the value of their solutions when using AWS. Prabhakar holds six AWS and six other professional certifications. With over 20 years of professional experience, Prabhakar was a data engineer and a program leader in the financial services space prior to joining AWS.