Artificial Intelligence
Running multiple HPO jobs in parallel on Amazon SageMaker
The ability to rapidly iterate and train machine learning (ML) models is key to deriving business value from ML workloads. Because ML models often have many tunable parameters (known as hyperparameters) that can influence the model’s ability to effectively learn, data scientists often use a technique known as hyperparameter optimization (HPO) to achieve the best-performing model against a certain predefined metric. Depending on the number of hyperparameters and the size of the search space, finding the best model can require thousands or even tens of thousands of training runs. Real-world problems that often require extensive HPO include image segmentation for modeling vehicular traffic for autonomous driving, developing algorithmic trading strategies based on historical financial data, or building fraud detection models on transaction data. Amazon SageMaker provides a built-in HPO algorithm that removes the undifferentiated heavy lifting required to build your own HPO algorithm. This post shows how to batch your HPO jobs to maximize the number of jobs you can run in parallel, thereby reducing the total time it takes to effectively cover the desired parameter space and obtain the best-performing models.
Before diving into the batching approach on Amazon SageMaker, let’s briefly review the state-of-the-art [1]. There are a large number of HPO algorithms, ranging from random or grid search, Bayesian search, and hand tuning, where researchers use their domain knowledge to tune parameters to population-based training inspired from genetic algorithms. For deep learning models, however, even training a single training run can be time consuming. In that case, it becomes important to have an aggressive early stopping strategy, which ends trials in search spaces that are unlikely to produce good results. Several strategies like successive halving or asynchronous successive halving use multi-arm bandits to trade-off between exploration (trying out different parameter combinations) versus exploitation (allowing a training run to converge). Finally, to help developers quickly iterate with these approaches, there are a number of tools, such as SageMaker HPO, Ray, HyperOpt, and more. In this post, you also see how you can bring one of the most popular HPO tools, Ray Tune, to SageMaker.
Use case: Predicting credit card loan defaults
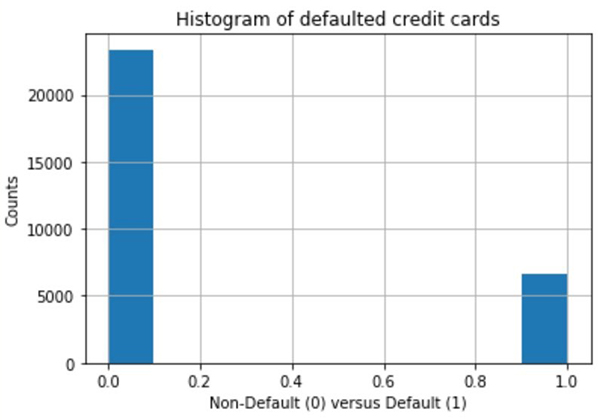
To demonstrate this on a concrete example, imagine that you’re an ML engineer working for a bank, and you want to predict the likelihood of a customer defaulting on their credit card payments. To train a model, you use historical data available from the UCI repository. All the code developed in this post is made available on GitHub. The notebook covers the data preprocessing required to prep the raw data for training. Because the number of defaults is quite small (as shown in the following graph), we split the dataset into train and test, and upsample the training data to 50/50 default versus non-defaulted loans.
Then we upload the datasets to Amazon Simple Storage Service (Amazon S3). See the following code:
Although SageMaker provides many built-in algorithms, such as XGBoost, in this post we demonstrate how to apply HPO to a custom PyTorch model using the SageMaker PyTorch training container using script mode. You can then adapt this to your own custom deep learning code. Furthermore, we will demonstrate how you can bring custom metrics to SageMaker HPO.
When dealing with tabular data, it’s helpful to shard your dataset into smaller files to avoid long data loading times, which can starve your compute resources and lead to inefficient CPU/GPU usage. We create a custom Dataset class to fetch our data and wrap this in the DataLoader class to iterate over the dataset. We set the batch size to 1, because each batch consists of 10,000 rows, and load it using Pandas.
Our model is a simple feed-forward neural net, as shown in the following code snippet:
As shown in the Figure above, the dataset is highly imbalanced and as such, model accuracy isn’t the most useful evaluation metric, because a baseline model that predicts all customers won’t default on their payments will have high accuracy. A more useful metric is the AUC, which is the area under the receiver operator characteristic (ROC) curve that aims to minimize the number of false positives while maximizing the number of true positives. A false positive (model incorrectly predicting a good customer will default on their payment) can cause the bank to lose revenue by denying credit cards to customers. To make sure that your HPO algorithm can optimize on a custom metric such as the AUC or F1-score, you need to log those metrics into STDOUT, as shown in the following code:
Now we’re ready to define our SageMaker estimator and define the parameters for the HPO job:
We pass in the paths to the training and test data in Amazon S3.
With the setup in place, let’s now turn to running multiple HPO jobs.
Parallelizing HPO jobs
To run multiple hyperparameter tuning jobs in parallel, we must first determine the tuning strategy. SageMaker currently provides a random and Bayesian optimization strategy. For random strategy, different HPO jobs are completely independent of one another, whereas Bayesian optimization treats the HPO problem as a regression problem and makes intelligent guesses about the next set of parameters to pick based on the prior set of trials.
First, let’s review some terminology:
- Trials – A trial corresponds to a single training job with a set of fixed values for the hyperparameters
- max_jobs – The total number of training trials to run for that given HPO job
- max_parallel_jobs – The maximum concurrent running trials per HPO job
Suppose you want to run 10,000 total trials. To minimize the total HPO time, you want to run as many trials as possible in parallel. This is limited by the availability of a particular Amazon Elastic Compute Cloud (Amazon EC2) instance type in your Region and account. If you want to modify or increase those limits, speak to your AWS account representatives.
For this example, let’s suppose that you have 20 ml.m5.xlarge instances available. This means that you can simultaneously run 20 trials of one instance each. Currently, without increasing any limits, SageMaker limits max_jobs to 500 and max_parallel_jobs to 10. This means that you need to run a total of 10,000/500 = 20 HPO jobs. Because you can run 20 trials and max_parallel_jobs is 10, you can maximize the number of simultaneous HPO jobs running by running 20/10 = 2 HPO jobs in parallel. So one approach to batch your code is to always have two jobs running, until you meet your total required jobs of 20.
In the following code snippet, we show two ways in which you can poll the number of running jobs to achieve this. The first approach uses boto3, which is the AWS SDK for Python to poll running HPO jobs, and can be run in your notebook and is illustrated pictorially in the following diagram. This approach can primarily be used by data scientists. Whenever the number of running HPO jobs falls below a fixed number, indicated by the blue arrows in the dashed box on the left, the polling code will launch new jobs (shown in orange arrows). The second approach uses Amazon Simple Queue Service (Amazon SQS) and AWS Lambda to queue and poll SageMaker HPO jobs, allowing you to build an operational pipeline for repeatability.
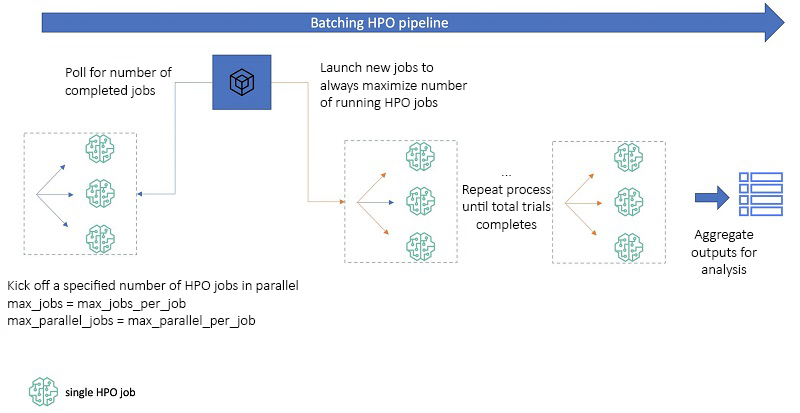
Sounds complicated? No problem, the following code snippet allows you to determine the optimal strategy to minimize your overall HPO time by running as many HPO jobs in parallel as allowed. After you determine the instance type you want to use and your respective account limits for that instance, replace max_parallel_across_jobs with your value.
After you determine how to run your jobs, consider the following code for launching a given sequence of jobs. The helper function _parallel_hpo_no_polling runs the group of parallel HPO jobs indicated by the dashed box in the preceding figure. It’s important to set the wait parameter to False when calling the tuner, because this releases the API call to allow the loop to run. The orchestration code poll_and_run polls for the number of jobs that are running at any given time. If the number of jobs falls below the user-specified maximum number of trials they want to run in parallel (max_parallel_across_jobs), the function automatically launches new jobs. Now you might be thinking, “But these jobs can take days to run, what if I want to turn off my laptop or if I lose my session?” No problem, the code picks up where it left off and runs the remaining number of jobs by counting how many HPO jobs are remaining prefixed by the job_name_prefix you provide.
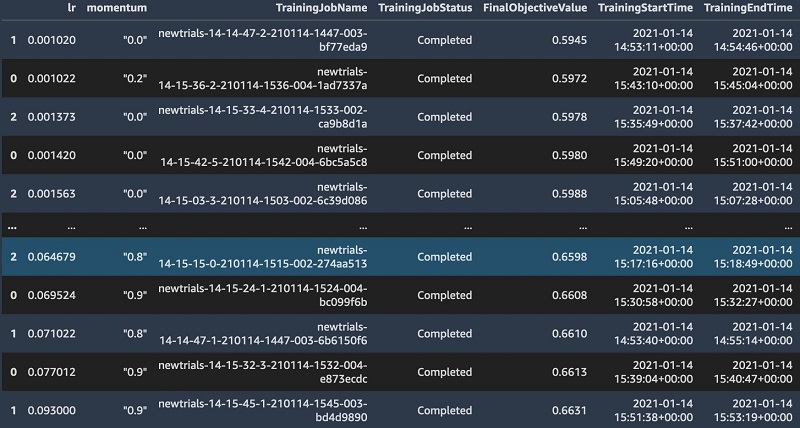
Finally, the get_best_job function aggregates the outputs in a Pandas DataFrame in ascending order of the objective metric for visualization.
Now, we can test this out by running a total of 260 trials, and request that the code run 20 trials in parallel at all times:
After the jobs are complete, we can look at all the outputs (see the following screenshot).
The above code will allow you to run HPO jobs in parallel up to the allowed limit of 100 concurrent HPO jobs.
Parallelizing HPO jobs with warm start
Now suppose you want to run a warm start job, where the result of a prior job is used as input to the next job. Warm start is particularly useful if you have already determined a set of hyperparameters that produce a good model but now have new data. Another use case for warm start is when a single HPO job can take a long time, particularly for deep learning workloads. In that case, you may want to use the outputs of the prior job to launch the next one. For our use case, that could occur when you get a batch of new monthly or quarterly default data. For more information about SageMaker HPO with warm start, see Run a Warm Start Hyperparameter Tuning Job.
The crucial difference between warm and cold start is the naturally sequential nature of warm start. Again, suppose we want to launch 10,000 jobs with warm start. This time, we only launch a single HPO job with the maximally allowed max_jobs parameter, wait for its completion, and launch the next job with this job as parent. We repeat the process until the total desired number of jobs is reached. We can achieve this with the following code:
After the jobs run, again use the get_best_job function to aggregate the findings.
Using other HPO tools with SageMaker
SageMaker offers the flexibility to use other HPO tools such as the ones discussed earlier to run your HPO jobs by removing the undifferentiated heavy lifting of managing the underlying infrastructure. For example, a popular open-source HPO tool is Ray Tune [2], which is a Python library for large-scale HPO that supports most of the popular frameworks such as XGBoost, MXNet, PyTorch, and TensorFlow. Ray integrates with popular search algorithms such as Bayesian, HyperOpt, and SigOpt, combined with state-of-the-art schedulers such as Hyperband or ASHA.
To use Ray with PyTorch, you first need to include ray[tune] and tabulate to your requirements.txt file in your code folder containing your training script. Provide the code folder into the SageMaker PyTorch estimator as follows:
Your training script needs to be modified to output your custom metrics to the Ray report generator, as shown in the following code. This allows your training job to communicate with Ray. Here we use the ASHA scheduler to implement early stopping:
You also need to checkpoint your model at regular intervals:
Finally, you need to wrap the training script in a custom main function that sets up the hyperparameters such as the learning rate, the size of the first and second hidden layers, and any additional hyperparameters you want to iterate over. You also need to use a scheduler, such as the ASHA scheduler we use here, for single- and multi-node GPU training. We use the default tuning algorithm Variant Generation, which supports both random (shown in the following code) and grid search, depending on the config parameter used.
The output of the job looks like the following screenshot.
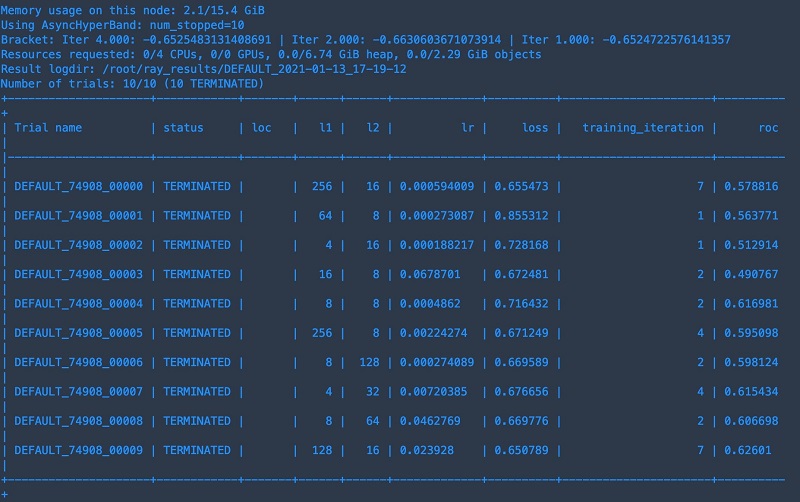
Ray Tune automatically ends poorly performing jobs while letting the better-performing jobs run longer, optimizing your total HPO times. In this case, the best-performing job ran all full 7 epochs, whereas other hyperparameter choices were stopped early. To learn more about how early stopping works with SageMaker HPO see here.
Queuing HPO jobs with Amazon SQS
When multiple data scientists create HPO jobs in the same account at the same time, the limit of 100 concurrent HPO jobs per account might be reached. In this case, we can use Amazon SQS to create an HPO job queue. Each HPO job request is represented as a message and submitted to an SQS queue. Each message contains hyperparameters and tunable hyperparameter ranges in the message body. A Lambda function is also created. The function first checks the number of HPO jobs in progress. If the 100 concurrent HPO jobs limit isn’t reached, it retrieves messages from the SQS queue and creates HPO jobs as stipulated in the message. The function is triggered by Amazon EventBridge events at a regular interval (for example, every 10 minutes). The simple architecture is shown as follows.
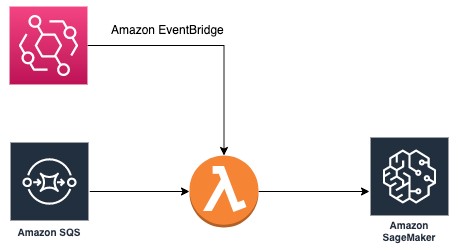
To build this architecture, we first create an SQS queue and note the URL. In the Lambda function, we use the following code to return the number of HPO jobs in progress:
If the number of HPO jobs in progress is greater than or equal to the limit of 100 concurrent HPO jobs (for current limits, see Amazon SageMaker endpoints and quotas), the Lambda function returns 200 status and exits. If the limit isn’t reached, the function calculates the number of HPO jobs available for creation and retrieves the same number of messages from the SQS queue. Then the Lambda function extracts hyperparameter ranges and other data fields for creating HPO jobs. If the HPO job is created successfully, the corresponding message is deleted from the SQS queue. See the following code:
After your Lambda function is created, you can add triggers with the following steps:
- On the Lambda console, choose your function.
- On the Configuration page, choose Add trigger.
- Select EventBridge (CloudWatch Events).
- Choose Create a new rule.
- Enter a name for your rule.
- Select Schedule expression.
- Set the rate to 10 minutes.
- Choose Add.
This rule triggers our Lambda function every 10 minutes.
When this is complete, you can test it out by sending messages to the SQS queue with your HPO job configuration in the message body. The code and notebook for this architecture is on our GitHub repo. See the following code:
Conclusions
ML engineers often need to search through a large hyperparameter space to find the best-performing model for their use case. For complex deep learning models, where individual training jobs can be quite time consuming, this can be a cumbersome process that can often take weeks or months of developer time.
In this post, we discussed how you can maximize the number of tuning jobs you can launch in parallel with SageMaker, which reduces the total time it takes to run HPO with custom user-specified objective metrics. We first discussed a Jupyter notebook based approach that can be used by individual data scientists for research and experimentation workflows. We also demonstrated how to use an SQS queue to allow teams of data scientists to submit more jobs. SageMaker is a highly flexible platform, allowing you to bring your own HPO tool, which we illustrated using the popular open-source tool Ray Tune.
To learn more about bringing other algorithms such as genetic algorithms to SageMaker HPO, see Bring your own hyperparameter optimization algorithm on Amazon SageMaker.
References
[1] Hyper-Parameter Optimization: A Review of Algorithms and Applications, Yu, T. and Zhu, H., https://arxiv.org/pdf/2003.05689.pdf.
[2] Tune: A research platform for distributed model selection and training, https://arxiv.org/abs/1807.05118.
About the Authors
 Iaroslav Shcherbatyi is a Machine Learning Engineer at Amazon Web Services. His work is centered around improvements to the Amazon SageMaker platform and helping customers best use its features. In his spare time, he likes to catch up on recent research in ML and do outdoor sports such as ice skating or hiking.
Iaroslav Shcherbatyi is a Machine Learning Engineer at Amazon Web Services. His work is centered around improvements to the Amazon SageMaker platform and helping customers best use its features. In his spare time, he likes to catch up on recent research in ML and do outdoor sports such as ice skating or hiking.
 Enrico Sartorello is a Sr. Software Development Engineer at Amazon Web Services. He helps customers adopt machine learning solutions that fit their needs by developing new functionalities for Amazon SageMaker. In his spare time, he passionately follows his soccer team and likes to improve his cooking skills.
Enrico Sartorello is a Sr. Software Development Engineer at Amazon Web Services. He helps customers adopt machine learning solutions that fit their needs by developing new functionalities for Amazon SageMaker. In his spare time, he passionately follows his soccer team and likes to improve his cooking skills.
 Tushar Saxena is a Principal Product Manager at Amazon, with the mission to grow AWS’ file storage business. Prior to Amazon, he led telecom infrastructure business units at two companies, and played a central role in launching Verizon’s fiber broadband service. He started his career as a researcher at GE R&D and BBN, working in computer vision, Internet networks, and video streaming.
Tushar Saxena is a Principal Product Manager at Amazon, with the mission to grow AWS’ file storage business. Prior to Amazon, he led telecom infrastructure business units at two companies, and played a central role in launching Verizon’s fiber broadband service. He started his career as a researcher at GE R&D and BBN, working in computer vision, Internet networks, and video streaming.
 Stefan Natu is a Sr. Machine Learning Specialist at Amazon Web Services. He is focused on helping financial services customers build end-to-end machine learning solutions on AWS. In his spare time, he enjoys reading machine learning blogs, playing the guitar, and exploring the food scene in New York City.
Stefan Natu is a Sr. Machine Learning Specialist at Amazon Web Services. He is focused on helping financial services customers build end-to-end machine learning solutions on AWS. In his spare time, he enjoys reading machine learning blogs, playing the guitar, and exploring the food scene in New York City.
 Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his PhD in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently, he helps customers in the financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his PhD in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently, he helps customers in the financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.