Artificial Intelligence
Unlock information in unstructured text to personalize product and content recommendations with Amazon Personalize
This post was last reviewed and updated June, 2022. When this blog post was initially published, English was the only language supported for the textual field in the items dataset. Now Amazon Personalize supports textual field values in Chinese (simplified and traditional), French, German, Japanese, Portuguese, and Spanish; removes HTML and XML markup and whitespace formatting characters from text before it is processed; and supports textual fields across more recipes including Similar-Items, Item-Affinity, and Item-Attribute-Affinity. This blog post has been updated to reflect these improvements.
Amazon Personalize now enables you to tap into the information trapped in product descriptions, product reviews, movie synopses, or other unstructured text and use it when generating personalized recommendations. Product descriptions provide important information about the features and benefits of products. Amazon Personalize can use the investments made to create these narratives to increase the relevance of recommendations for products, movies, TV shows, news articles, and more. You can now automatically extract key information from the unstructured text about your product or content to use with Amazon Personalize.
This post shows you how to include unstructured text when using Amazon Personalize and the impact it can have on the relevance of the recommendations you generate with the service.
Amazon Personalize enables developers to build applications with the same machine learning (ML) technology used by Amazon.com for real-time personalized recommendations with no ML expertise required. We make it easy for developers to build applications capable of delivering a wide array of personalization experiences. Amazon Personalize is a fully managed ML service that goes beyond rigid static rule-based recommendation systems and allows customers across industries to create custom recommenders that provide highly personalized user experiences. You receive results via an Application Programming Interface (API) and only pay for what you use, with no minimum fees or upfront commitments. All data is encrypted to be private and secure, and is only used to create recommendations for your users.
The relevance of the recommendations you deliver with Amazon Personalize depends on the data available when the recommendations are generated. Amazon Personalize uses your users’ historical interactions, the attributes of your items, and your users’ metadata to learn what items are most relevant for each user. The primary data required by Amazon Personalize is user-item interactions. The interactions users have with items in your catalog, such as clicking on a product, reading an article, watching a video, or purchasing a product, are an important signal of what they have found relevant in the past. Including item and user attributes, also known as metadata, can enhance the relevance of recommendations, especially for new items that are similar to what your users have found relevant.
However, structured metadata such as an item’s category, style, or genre may not always be readily available or may not provide all the information that you have in your narrative descriptions. Amazon Personalize now allows you to add unstructured metadata such as product descriptions, video transcripts, or article text with your other item attributes. Amazon Personalize hosts, manages, and automatically uses natural language processing (NLP) models to process your text and use it to improve the performance of your Amazon Personalize solutions.
Use unstructured text in recommendations
To use text as unstructured data, just add a column in your items dataset with a type of string and set the field’s textual attribute to true. This data should be included in your items datasets via dataset import jobs and your incremental item imports using the PutItems API. Amazon Personalize removes HTML/XML markup and truncates the resulting values that exceed the character limit to 7,000 characters for Chinese and Japanese text and 20,000 characters for all other supported languages before they’re processed. In the following example of an items dataset schema, the DESCRIPTION field declares an unstructured text column:
For recipes that use item metadata (such as user personalization and personalized ranking), Amazon Personalize automatically extracts the features from your unstructured text. All you need to do is provide the data.
When you’re considering including text in your items dataset, keep the following best practices in mind:
- Text that is editorially validated to be concise, relevant, and informative to each item is preferred over user-generated content that may be less relevant or consistent.
- Place the most pertinent details earlier in the text for each item, particularly if concatenating multiple text values in the textual field.
- A sparsely populated text column diminishes the positive impact of including text in the items dataset.
- Chinese (simplified and traditional), English, French, German, Japanese, Portuguese, and Spanish are currently the only supported languages for the text field.
- Multiple languages can be included in the textual column in the items dataset but each item’s text should be represented in a single supported language.
- Text fields are currently only considered for the user personalization, personalized ranking, similar items, item affinity, and item attribute affinity recipes.
Overview of solution
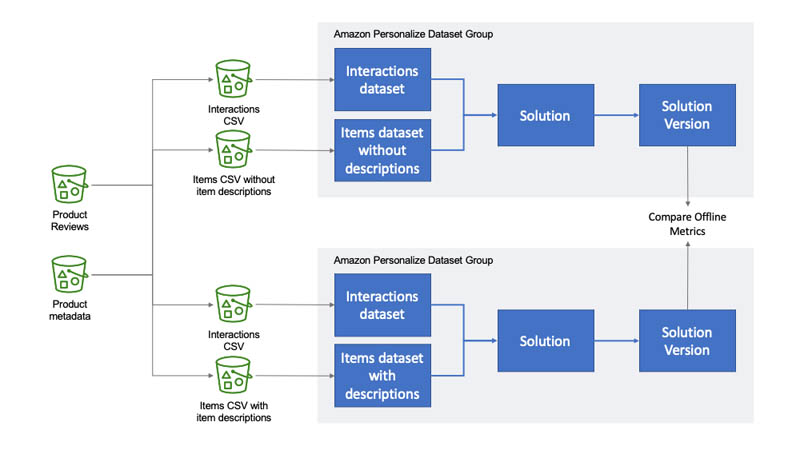
The notebook that accompanies this post demonstrates how the introduction of product descriptions for a product ratings dataset improves offline metrics by as much as 35%. We use two Amazon Personalize dataset groups that include the same interaction data but have different item datasets. One dataset group excludes product descriptions, and the other has an items dataset that includes them. We create a solution and solution version in each dataset group using the aws-user-personalization recipe. This recipe uses each user’s interaction history, combined with item and user metadata, to learn a user’s interests. We then use these learnings to recommend other products a user may be interested in.
To measure the difference in recommendations from the two solution versions, you can compare each solution version’s offline metrics. Offline metrics are the metrics that Amazon Personalize generates when you train a solution version. They’re created by measuring the accuracy of recommendations provided by the solution version against data held out for evaluation from the interactions dataset. By comparing the metrics between the two solution versions, we can assess how the inclusion of the text field impacts the recommender.
The following diagram illustrates the architecture of these two groups.
Compare solution version offline metrics
When Amazon Personalize trains a solution version, it also calculates offline metrics. You can use offline metrics to provide a directional sense of recommendation accuracy changing over time from one solution version to the next against held out data from the interactions dataset. Comparing the offline metrics of the two solution versions gives us a sense of the impact of introducing product descriptions in the items dataset. You can retrieve the offline metrics for a solution version by calling the DescribeSolutionVersion API or via the Amazon Personalize console.
The following table lists metrics Amazon Personalize provides for both solution versions from the accompanying notebook and the percentage difference. All values will fall within 0.0–1.0, where a larger value is preferred.
| Metric | Without Descriptions | With Descriptions | % Change |
| Coverage | 0.1222 | 0.1540 | 26.02% |
| MRR-25 | 0.0309 | 0.0371 | 20.06% |
| NDCG-5 | 0.0332 | 0.0426 | 28.31% |
| NDCG-10 | 0.0400 | 0.0513 | 28.25% |
| NDCG-25 | 0.0498 | 0.0624 | 25.30% |
| Precision-5 | 0.0079 | 0.0107 | 35.44% |
| Precision-10 | 0.0059 | 0.0078 | 32.20% |
| Precision-25 | 0.0039 | 0.0049 | 25.64% |
Every metric improves when the product description is introduced. The coverage metric is a measure of the proportion of unique items that Amazon Personalize might recommend using the model out of the total number of unique items in the interactions and items datasets. The mean reciprocal rank (MRR) metric is useful if you’re interested in the single highest-ranked recommendation. The normalized discounted cumulative gain (NDCG) metrics reward relevant items that appear near the top of the list, because the top of a list usually draws more attention. The precision metrics tell you how relevant the model’s recommendations are based on a sample size of K (5, 10, or 25) recommendations; it rewards precise recommendations of the relevant items.
The relative lift in offline metrics varies across datasets based on the quality of the unstructured text and the sparseness of your interactions dataset. For example, datasets with fewer interactions per item and user or without structured item metadata benefit from the features extracted from unstructured text.
Evaluate real-time recommendations
Ultimately, the best measure of a recommender is online testing using a technique such as A/B testing. This tells you how users respond to recommendations in the context of a user interface and in a production environment.
You can choose from two approaches to retrieve recommendations from an Amazon Personalize solution version:
- An Amazon Personalize campaign provides an auto scaling endpoint that you can use to retrieve recommendations in real time. Campaigns are ideal for integrating Amazon Personalize into the request flow of website or mobile application where you want to surface the most up-to-date recommendations for your users.
- You can generate recommendations in bulk using a batch inference job. Batch recommendations are designed to be paired with downstream batch processes such as email marketing campaigns.
Conclusion
The quality of recommendations provided by Amazon Personalize is only as good as the data made available. Amazon Personalize can learn user interest across your catalog of items by examining what items users have interacted with in the past as well as considering item and user metadata. Item metadata is particularly useful in situations such as cold starting recommendations for new items where historical interactions aren’t available. In some cases, structured metadata for items is limited or not available, but rich textual fields such as product descriptions or article text are available instead. Amazon Personalize is now able to take in unstructured metadata and apply NLP to extract features that improve the quality of your recommendations. Including text fields in Amazon Personalize solutions is simply a matter of adding a textual field to your schema and adding the text to your items dataset.
To learn more about Amazon Personalize, visit the product page.
About the Authors
 James Jory is a Principal Solutions Architect in Applied AI with AWS. He has a special interest in personalization and recommender systems and a background in ecommerce, marketing technology, and customer data analytics. In his spare time, he enjoys camping and auto racing simulations.
James Jory is a Principal Solutions Architect in Applied AI with AWS. He has a special interest in personalization and recommender systems and a background in ecommerce, marketing technology, and customer data analytics. In his spare time, he enjoys camping and auto racing simulations.
 Matt Chwastek is a Senior Product Manager for Amazon Personalize. He focuses on delivering products that make it easier to build and use machine learning solutions. In his spare time, he enjoys reading and photography.
Matt Chwastek is a Senior Product Manager for Amazon Personalize. He focuses on delivering products that make it easier to build and use machine learning solutions. In his spare time, he enjoys reading and photography.
 Gaurav Singh Chauhan is a Senior Software Engineer for Amazon Personalize and works on architecting software systems to serve customers at scale. He’s an avid runner and can often be found hanging out at r/running in his spare time. He tweets about startups, technology, and India at @bazingaurav.
Gaurav Singh Chauhan is a Senior Software Engineer for Amazon Personalize and works on architecting software systems to serve customers at scale. He’s an avid runner and can often be found hanging out at r/running in his spare time. He tweets about startups, technology, and India at @bazingaurav.
 Hao Ding is an Applied Scientist at AWS AI Labs and is working on developing next generation recommender system for Amazon Personalize. His research interests include Recommender System, Deep Learning, and Graph Mining.
Hao Ding is an Applied Scientist at AWS AI Labs and is working on developing next generation recommender system for Amazon Personalize. His research interests include Recommender System, Deep Learning, and Graph Mining.