AWS Media Blog
How to Set Up a Resilient End-to-End Live Workflow Using AWS Elemental Products and Services: Part 3
Multi-regions reference architecture deployment walkthrough: Advanced Workflows
In part two of this blog series, we covered advanced practices for single-region deployments with AWS Elemental Live, AWS Elemental MediaLive, and AWS Elemental MediaPackage combined with AWS Elemental Conductor and AWS Elemental MediaConnect. Each workflow referenced in the previous posts leverages multiple availability zones in the AWS Region in which they are deployed. This means these workflows could fail only if the entire AWS Region were to go down. While this is a highly unlikely scenario, there are situations in which customers may want to add yet another layer of resilience to their live video services that protects against such an issue. In those cases, you have the option to deploy AWS Media Services in multiple AWS Regions, with failover that can span across regions.
Multi-regions for 24/7 streaming
If your use case is 24/7 streaming, the egress bandwidth from your contribution sites is probably not a bottleneck when it comes to sending each contribution stream to two AWS Elemental MediaLive ingest endpoints. Starting from this assumption, we can build a multi-region variant of the “Disaster recovery with multiple contribution sites and MediaLive input switching” workflow we described in the previous blog post. Each contribution site will send its mezzanine streams to the MediaLive service deployed in each of two regions, and we still take advantage of the ability to switch between two input groups in MediaLive through the AWS Command Line Interface (CLI) or the API for maintenance or disaster recovery. Each MediaLive service will send its ABR HLS output to one MediaPackage channel’s ingest endpoints in the same region. An AWS Elemental MediaTailor service in each region can complement the setup to provide server-side ad insertion.
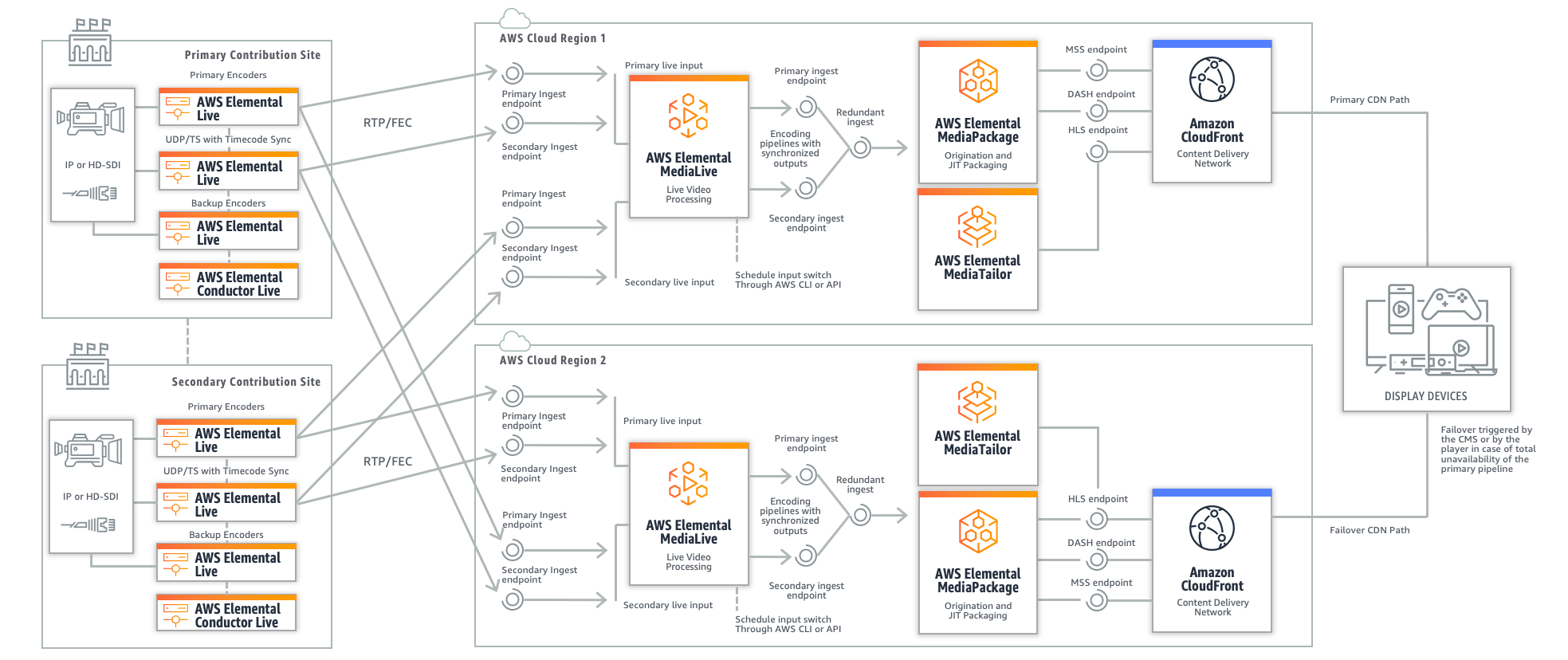
When delivering content across multiple regions, the most notable difference is that the two endpoints-per-format generated by MediaPackage will not be in sync across AWS Regions (i.e., they won’t use the same segment names for a given time slice), and they won’t share the same URL path. So, you cannot expect a single playback URL on the CDN side, as the origin failover will not be seamless. To address this, you can deploy one CDN distribution per MediaPackage channel and ask your CMS to tell the video player, at start of playback or during the playback session, which URL it needs to use, based on QoS/QoE data analysis. This is called a “hard switch,” as most video players will use the same CDN endpoint, or switch to the same CDN endpoint in a short interval, depending on the propagation latency of your URL switching system.
Another strategy involves automating the failover between primary and alternate URLs on the player side, for example, based on the total unavailability of the primary stream on the CDN endpoint. This is called a “granular switch” as there is no centralized command system that tells the video players which CDN endpoint to use. In a hard switch – when everything goes well on both pipelines – you will still need your CMS to send a small portion of you traffic to the alternate CDN endpoint. This avoids a “cold cache” effect on the alternate CDN distribution, especially if you use long DVR windows.
With either approach, by causing the player to reload the HLS master playlist or DASH manifest from the alternate URL, you will trigger a potentially visible judder on the player side as the two streams won’t be perfectly synced. The player will jump slightly in the future or in the past; however, your viewers will benefit from a continuous playback session after the initial glitch.
In both approaches, it is mandatory to ensure URL path stickiness on the player side after a switch, as the manifest and the media segments from a given MediaPackage endpoint must be consumed together. In other words, you cannot deliver manifests from one MediaPackage endpoint and media segments from another, and provide a proper playback experience. This is especially true if you incorporate server-side ad insertion with MediaTailor: the MediaTailor service will create individual sessions (translated into URL redirections) that cannot be shared across regions. Repeatedly switching back and forth between two MediaTailor endpoints will continuously recreate sessions and cause 404 errors.
Multi-regions for event-based streaming
This scenario aims to provide the same level of resilience as the architecture described above, but with lower egress bandwidth requirements at the event site, and shares the same downstream workflow, starting from MediaLive. Using MediaConnect’s flow cloning feature, we can reach the same level of availability for the contribution stream as the architecture described above by sending only four mezzanine streams instead of eight. Each pair of contribution encoders uses a MediaConnect flow as ingest target, and each flow sends a copy of the stream to another MediaConnect flow in the second AWS Region, so that all four contribution streams are available as sources for MediaLive in each Region. This enables you to switch between two input groups for each MediaLive deployment: If one MediaLive deployment becomes unavailable, the other will access all of the four contribution streams and ensure the availability of the intermediary ABR streams in HLS. MediaPackage’s auto-scaling architecture will provide the necessary level of resilience level in each region, guaranteeing availability of the streams exposed to end users.

This final reference architecture concludes our journey through resilient live workflows options. In a future blog post, we will explain how to set up an end-to-end monitoring system using the Media Services Application Mapper (MSAM) solution, which allows users to bring AWS Elemental on-premises encoders, AWS Elemental Media Services, and other related AWS services together in a single monitoring view.