AWS Startups Blog
Sparta Science: Predicting Musculoskeletal Injury Risk with Force Plate Machine Learning™ on AWS
Guest post by Greg Olsen – Chief Technology Officer, Sparta Science and Dhawal Patel, Sr. Startup Solutions Architect, AWS
Sparta Science delivers a movement health solution to organizations who want to protect their most valuable resource – people. Elite sports teams, military units, performance and rehabilitation businesses, occupational health providers, and employers use Sparta Science’s Movement Health Platform (SMHP) to assess injury risk and performance, and to guide improvements in musculoskeletal health. In a nutshell, the Sparta System is based on following elements:
- Scanning: Users execute simple movement tests in a few minutes on a high-fidelity force plate that captures real-time ground reaction forces.
- Assessment: Through a combination of machine learning models and bio-mechanical analyses, the time series data is transformed into a set of movement health metrics, and injury risk and performance scores.
- Guidance: Individualized activity and exercise recommendations are generated based on the movement metrics and risk and performance scores.
- Information Management: Scanned data and results are uploaded to a cloud application where individuals manage their MSK health over time and where organizations can manage the health of their workforce.
Sparta Science has been collecting and assessing ground reaction force time series data for over a decade from 80k+ unique individuals and from a variety of different population groups (e.g., sport & position, military function etc.). In conjunction with this time series data, we’ve also been collecting injury event, performance measurement, exposure, and exercise activity data. Through the combination of accumulated data, advance machine learning techniques, and domain knowledge brought from a team that includes professional training and medical expertise, Sparta Science is able to deliver a uniquely powerful system for movement health. Delivering this system, however, presented a daunting set challenges for a small company that led us to AWS.

Web & mobile based access to personalized machine learning exercise recommendations
Challenges Sparta Science Had to Solve
As a growing startup, we had a few key challenges that needed to be solved in order for us to stand out in the competitive health data landscape:
- We wanted to leverage a cloud-based architecture to readily deploy and easily update customer instances of the Sparta Science software.
- We needed to be able to rapidly scale to support existing and new customers, in a variety of physical environments, both domestic and overseas.
- We needed a system that could support the complex machine learning metrics that are constantly evolving within our products.
- Most importantly, we needed to ensure the safety and security of our customers’ data.
- Last but not least, as a startup, we needed to accelerate the time to market and needed to focus on developing core business features in our product at a rapid pace. We needed to serve our government customers and their partners and wanted the flexibility to architect secure cloud solutions that comply with the FedRAMP High baseline.
AWS came to the rescue
While startups are known for pioneering rapid innovation, they are not known for having extremely robust departments nor large number of staff. Sparta Science is no exception! By leveraging AWS, we were not only able to scale in a rapid, cost-effective manner, but with the confidence of a secure platform that is robust enough to support our dynamically innovative Force Plate Machine Learning™ environment. AWS has become a trusted partner and extension of our internal team. AWS’s support team has provided us with both a breadth and a depth of experience whenever we’ve needed it, allowing us to focus on our core strengths. That, in turn, has enabled us to provide a better product, at scale, for our customers. We would not be where we are today without AWS.
The Sparta Science Movement Health Platform
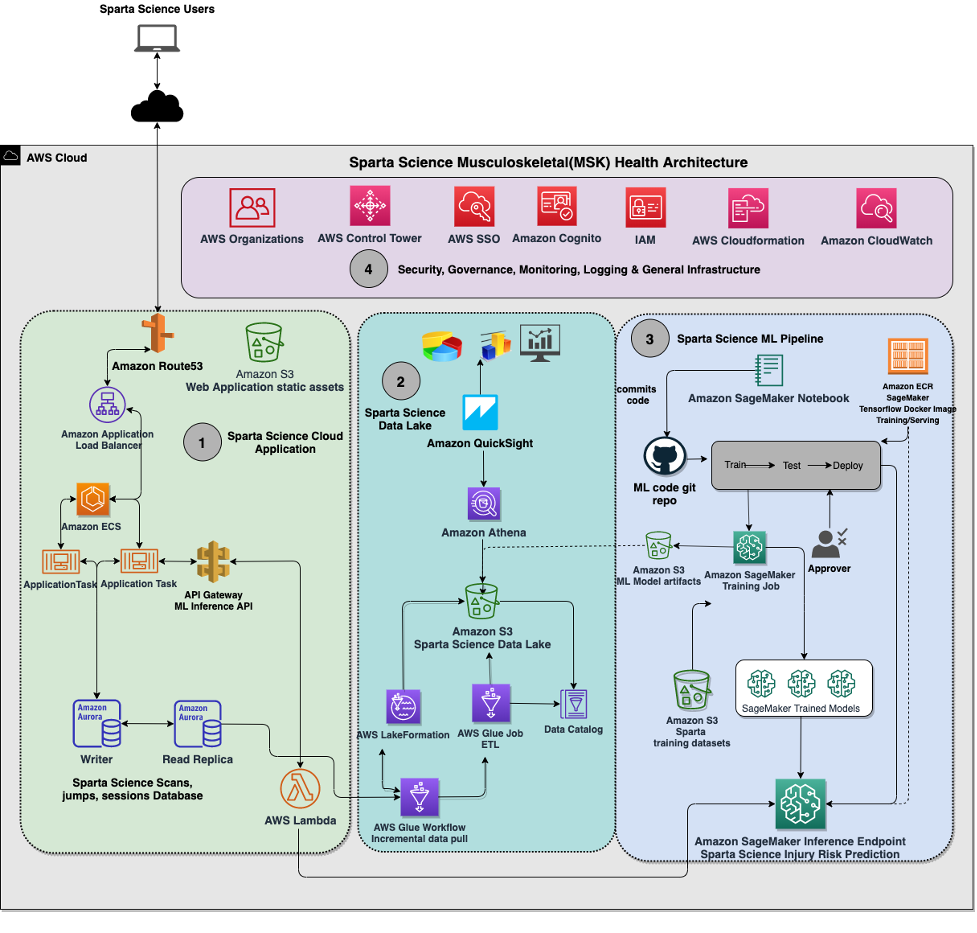
The figure below shows a very high-level conceptual layout of the SMHP.

The SMHP has two key parts:
- Edge: The Sparta Force Plate connected to a laptop running the Sparta Scan app (a MacOS application). The app guides users through simple movement tests (e.g., tests that involve periods of balance and a counter movement jump), captures time series data and processes it in real time to produce a set of movement health metrics (that act as a movement health signature) and injury risk & performance scores that are displayed to the user. The results, then are pushed to Sparta Cloud.
- Cloud: The Sparta Cloud SaaS application and supporting data lake and ML pipeline constitutes the Cloud part of the SMHP. Sparta Cloud supports multiple different user personas, complex hierarchical organizational structures, and role-based access control to support diverse customer needs. Capabilities include rich comparative analysis reports, and a full-featured set of administrative functions for organizational leaders.
The SMHP, then, shares many cloud service requirements with any secure, scalable, multi-org commercial SaaS application provider.
The capabilities that it provides are dependent on its ability to continuously adapt as new data is ingested. From thousands of sites around the world, data is collected as users execute Sparta scans. Though these scans individually take only a few minutes, they constitute a significant volume of time series data. Even though results were immediately produced at the time of scanning, the life of this time series data is not over. Sparta is continuously searching for new and better features (movement health metrics) through exploitation of bio-mechanical research findings as well as through machine learning based extraction of patterns in the time series data – requiring frequent reprocessing of time series data that has entered the data lake.
In concert with the extraction of features from the time series data, the Sparta data science team is continuously enriching the set of models used for injury risk and performance prediction. Some of this enrichment is simply updating the models as more feature and label data is accumulated. In addition, the set of models is continuously growing as population-specific, injury type-specific, and other granularity of models are added.
The only way we were able to deliver this system was to highly leverage a long list of AWS services. To help in understanding our approach, we break the discussion below into the following categories:
1. Sparta Cloud Application
2. Sparta Data Lake
3. Machine Learning Pipeline
4. Security, Governance, Monitoring, Logging and General Infrastructure
This architectural system consists of the following components.
1. Sparta Cloud Application
As was mentioned previously, the Sparta Cloud Application (referred in #1 in the architecture diagram below) uses an architectural approach common to many multi-user, multi-organization enterprise SaaS applications. The Sparta Cloud application uses load balancers, VPC-level tenant isolation, multiple AWS Availability Zones, application servers for GraphQL API engine and logic, and database clusters.
The Amazon Application Load Balancer (Amazon ALB) functions at the application layer of OSI model, is used to serve as the single point of contact for clients. The load balancer distributes incoming Sparta Cloud application traffic across multiple targets in multiple Availability Zones. Sparta Cloud application uses Amazon ECS to host the application/business logic to ingest and serve the end user requests. The Amazon ALB target group is set to ECS cluster running in its private VPC subnet. When you associate a target group to an ECS service, ECS automatically registers and deregisters containers with your target group. Because ECS handles target registration, Sparta Science did not need to add targets to your target group. This native integration of ECS with Amazon ELB allowed Sparta Science to quickly set up the ingestion and consumption layer without needing much heavy lifting. Furthermore, the application containers hosted in this ECS cluster integrates with Sparta Science Injury Risk prediction API via a Private Amazon API Gateway and a AWS Lambda Function. The Injury Risk prediction API endpoint is hosted on Amazon SageMaker.
The Sparta Cloud application data is stored in Amazon Aurora PostgreSQL. Aurora PostgreSQL-compatible relational database is built for the cloud, that combines the performance and availability of traditional enterprise databases with the simplicity and cost-effectiveness of open-source databases. Sparta Science was quickly able to store millions of scans of data per day and meet the scaling requirements. In addition, Aurora is up to three times faster than standard PostgreSQL databases. Sparta Science was able to meet the high availability requirements as Aurora’s replicates 6 copies of the data across 3 availability zones.
2. Sparta Data Lake
As shown in architecture diagram below in #2, Sparta Science uses AWS Lake Formation to manage a secure data lake. Setting up a data lake using Lake Formation is as simple as defining data sources and what data access and security policies you want to apply. The Sparta data lake uses Amazon S3 with an indexing scheme that supports efficient querying for our data. In addition, the data lake is partitioned to isolate and separate customer sensitive data from de-identified data.
There are two primary sources of inflow to the data lake – scan data and cloud application data. Sparta Science scan data is pushed from the Scan app through the Sparta Cloud application API directly into Amazon S3. Application data accumulated in the Aurora cluster makes its way into the lake via ETL (extract, transform, and load) using AWS Glue which is a serverless data integration service. In order to systematically and incrementally pull the data from Aurora to hydrate the data lake, Sparta Science uses a Lake Formation Workflow from pre-built Lake Formation blueprints. In order to incrementally pull the data, we use the incremental database Lake Formation blueprint. Creating workflows is much simpler and more automated in Lake Formation.
Metadata stored in the data lake facilitates multiple use cases. Amazon Athena provides a convenient SQL interface layer for queries to support both Business Intelligence (BI) and Machine Learning (ML) use cases. The data lake also manages storage of data sets and models to support ML pipeline needs.
While the newly deployed Sparta Cloud application includes integrated analytics and reporting, we leveraged the data lake in combination with Amazon QuickSight to support some important analytical needs in the transition from our legacy application. The data lake was configured to hold legacy application data, and QuickSight, a scalable, serverless BI service built for the cloud, was used to quickly set up a dashboarding capability that our customer success team could use to give direct access to customers in a controlled and secure manner. As legacy application use is retired, QuickSight remains as a useful tool for internal ad hoc report needs as well as for exploring new reporting prototypes.
3. Machine Learning Pipeline
A key component of the SMHP is the Sparta ML pipeline (#3 shown in architecture diagram below). This pipeline is used to create, test, and serve two types of models used in SMHP:
- Metric models: These models extract distinguishing features from the ground reaction force time series data.
- Prediction models: These models prediction Injury Risk or Performance scores for individuals based on a given set of extracted metrics.
Sparta Science uses SageMaker for its cloud-based Machine Learning needs. SageMaker is a fully managed machine learning service. SageMaker helps data scientists and developers to prepare, build, train, test and deploy high-quality machine learning (ML) models quickly by bringing together a broad set of capabilities purpose-built for ML. Since the training and serving are billed by minutes of usage, with no minimum fees and no upfront commitments, Sparta Science was quickly able to lower costs and increase velocity for the use of machine learning.
The Sparta Science data scientists uses SageMaker provided pre-built TensorFlow Docker container images. The SageMaker pre-built container images allow easy and simple method to bring additional training/inference code specific to Sparta Science. Once code is committed into GitHub repositories, the ML CI/CD pipeline gets triggered and does training, testing and deploying the ML models on SageMaker. Once the ML model has achieved the required level of accuracy and precision, that specific version of ML model is then deployed to SageMaker Hosting Services by spinning up persistent SageMaker inference endpoints. This same CI/CD pipeline also generates companion core ML models that are deployed to the Sparta Scan app at the Edge.
In order to scale dynamically in response to the increase in rate of the incoming requests, Sparta Science uses Amazon SageMaker automatic scaling (Autoscaling) for the hosted models. Autoscaling dynamically adjusts the number of instances provisioned for a model in response to changes in your workload. When the workload increases, autoscaling brings more instances online. When the workload decreases, autoscaling removes unnecessary instances so that you don’t pay for provisioned instances that you aren’t using.
In order to serve the Inference requests along with performing preprocessing, and post-processing data science tasks, Sparta Science leverages SageMaker Inference Pipelines. Additionally, whenever a new ML Model version is available to deploy, Sparta Science uses the SageMaker Production Variant feature, which allows you to deploy multiple model versions on the same endpoint. This allows Sparta Science to tell SageMaker how to distribute traffic among the models by specifying variant weights.
4. Security, Governance, Monitoring, Logging & General infrastructure
When we started development on Sparta Science’s SMHP, we realized our future requirements for scale and regulatory compliance required a different approach to infrastructure than what we’d used in the past. The components are shown in #4 in the architecture diagram below.
Though Sparta Science is still a relatively small organization, the cloud usage patterns that SMHP needs to support warrant a thoughtful multi-account strategy. Key drivers for the approach include following:
● Independent application development, data science, and DevOps teams and responsibilities with different operational workflow and security requirements.
● Rigorous security requirements driven by FedRAMP, HIPAA, SOC and other regional compliance standards.
● The need to support multi-instance deployments that include GovCloud and country specific instances.
● Federated identity provider including Multi-factor Authentication (MFA), Single Sign-on (SSO) and Attributes based Access Control (ABAC).
● Granular and consistent permission control across the whole environment.
The basis of a well-architected multi-account AWS environment is AWS Organizations, an AWS service that enables you to centrally manage and govern multiple accounts. We rapidly innovated with various requirements, simplified billing, isolated workloads or applications that have specific security requirements, and easily organized multiple AWS accounts in a way that best reflects the diverse needs of the company’s business processes, such as different operational, regulatory, and budgetary requirements.
Additionally, AWS Control Tower provided us the easiest way to set up and govern out secure, multi-account AWS environment based on best practices established through AWS’ experience. Control Tower provided us mandatory and strongly recommended high-level rules, called guardrails, that helped enforce our policies using service control policies (SCPs), or detect policy violations using AWS Config rules. AWS SSO provided federated access to AWS accounts for Sparta Science teams. We also leveraged AWS CloudFormation and Terraform for practicing infrastructure as code that would ensure to apply the same rigor of application code development to infrastructure provisioning.
For wholistic monitoring and logging including monitoring Infrastructure and application, we use Amazon CloudWatch. CloudWatch collects monitoring and operational data in the form of logs, metrics, and events, providing you with a unified view of AWS resources, applications, and services that run on AWS. We use CloudWatch to detect anomalous behavior in our environments, set alarms, visualize logs and metrics side by side, take automated actions, troubleshoot issues, and discover insights to keep our applications running smoothly. In addition, for auditability, we use centralize logging from AWS CloudTrail.
Following is the architectural diagram of our system:
Conclusion
Delivery of service like the SMHP by a company as small as Sparta Science would have been unimaginable only a short number of years ago. AWS and the scope of services it offers provided the leverage we required to deliver a market changing product. Our investment in the AWS platform has brought us both differentiating capabilities and cost savings and enabled our entry into markets that would otherwise be inaccessible. Without AWS, we could not have reached where we are today. We are very much excited about the future. We look forward to AWS support along our journey.
Interested in ML on AWS? Contact us today!