AWS Storage Blog
How Bristol Myers Squibb uses Amazon S3 and AWS Storage Gateway to manage scientific data
Bristol Myers Squibb develops and discovers innovative medicines to help treat, manage, and cure serious diseases. We use many AWS services to help us manage our scientific data, lab workflows, and large computations for analyzing molecular, cellular, and clinical datasets. Genomics and clinical data, generated in Bristol Myers Squibb labs, is growing at an exponential pace. Moreover, Bristol Myers Squibb collects a variety of clinical data from external sources, such as academic medical centers, healthcare providers, and other collaborations. The wide assortment of sources for data results in broad variations in data formats.
Naturally, the cloud is the most convenient place for Bristol Myers Squibb to integrate and analyze the huge, often petabyte-scale datasets. Unlike accessing siloed data from on-premises data centers, the cloud helps Bristol Myers Squibb speed up scientific innovations by giving internal stakeholders on-demand access to growing sets of data. Of the many cloud storage services offered by AWS today, Amazon Simple Storage Service (Amazon S3) and AWS Storage Gateway play central roles at Bristol Myers Squibb. These services help us move scientific data into clinical data lakes and also help us perform countless life science data analysis processes using different techniques and methods.
Amazon S3 is an object storage service that offers industry-leading scalability, data availability, security, and performance. Storage Gateway is a hybrid cloud storage service that provides on-premises access to virtually unlimited cloud storage.
In this blog post, we focus on how Bristol Myers Squibb, where I work as Sr. Cloud Architect, uses Amazon S3 and Storage Gateway in life science applications. To some extent, this post follows along with our AWS re:Invent 2019 presentation: STG305 “Build hybrid storage architectures with AWS Storage Gateway,” which I presented along with my manager, Mr. Mohamad Shaikh a few months ago. I hope to shed some light on additional Amazon S3 and Storage Gateway use cases at Bristol Myers Squibb that we weren’t able to cover during that session.
The following video is a short 9 minute version of my re:Invent session:
How Bristol Myers Squibb uses Amazon S3
We maintain petabytes of scientific data in Amazon S3, coming from multiple and varied data pipelines. Bristol Myers Squibb leverages Amazon Athena, Amazon EMR, and AWS Glue to integrate, query, and analyze the data. By doing so, we are able to derive key scientific insights from various studies and data sources.
One of the key reasons Amazon S3 has become so successful and widely adopted at Bristol Myers Squibb is AWS’s focus on access management and security. That focus helps our organization keep millions of files well protected from unauthorized users, yet we can still share them with multiple legitimate applications and teams. We can maintain data encryption in a transparent fashion for authorized parties along the way. Using Amazon S3, we facilitate active data exchange in a highly secure manner between different internal teams distributed geographically, external scientific institutes, and global collaborations.
Employing Amazon S3’s flat, non-hierarchical structure, we organize our data in many S3 buckets based on a variety of criteria such as sources, sensitivity, visibility, and more. In some cases, such buckets can end-up holding hundreds of millions objects, including genomic datasets and life science images that come from scientific instruments. Often, these buckets reach petabytes in size. However, thanks to a flexible tagging system, well-thought out naming conventions, indexing capabilities, and data management systems, our scientists can quickly search through this enormous volume of data.
Since Amazon S3 is highly scalable, not only horizontally but vertically too, it can serve high volumes of transactions concurrently. Bristol Myers Squibb has found this functionality especially useful in multiple Big Data and cluster solutions, which are used to support our high performance computing (HPC) needs. As in other areas, these needs are salient throughout our genetics data research, complex chemical compound visualization, capturing data streams from scientific lab equipment, and data enrichment.
Still, maintaining petabytes of scientific data in the cloud comes with responsibilities. Here at Bristol Myers Squibb we take data lifecycles, encryption, compliance, and cost optimization seriously. Amazon S3’s default “Standard” storage class is designed for 99.999999999% (11 9’s) of durability, a high SLA, low latency access, and cost-effective storage per gigabyte. Moreover, you might achieve significant savings by employing other S3 storage classes for less active, or even archival, datasets.
Most of our Amazon S3 buckets live in Amazon S3 Standard, which allows us to access data immediately whenever we need it for research purposes. Idle data, however, must be archived for long-term storage, for industry compliance reasons. As a result, we chose Amazon S3 Glacier as our cost-effective solution to store data that we may no longer use. We spent much time and effort monitoring buckets, fine-tuning lifecycle rules, and moving data between the storage classes. We later found out that for a small fee, S3 Intelligent-Tiering could relieve us from spending time to manage moving data between classes. Once we transitioned our data into S3 Intelligent-Tiering and established new lifecycle policies, S3 Intelligent-Tiering began taking care of moving our data based on our usage patterns.
Moving data to the cloud with AWS Storage Gateway
Another AWS service that Bristol Myers Squibb uses is Storage Gateway, a hybrid cloud storage service. You can use Storage Gateway to move tape backups to the cloud, reduce on-premises storage with cloud-backed file shares, or provide low latency access to data in AWS for on-premises applications. You can also use Storage Gateway in various migration, archiving, processing, and disaster recovery use cases.
At Bristol Myers Squibb, we move data to the cloud using various methods, where data processing then occurs according to the well-known 3Vs data concept:
- Data variety (the data takes lots of different forms)
- Data velocity (the data changes or is updated frequently)
- Data veracity (the data may be of poor/unknown quality)
Often, in these hybrid file storage use cases, our pipelines depend on Storage Gateway’s ability to effectively transfer data to Amazon S3. They also rely on Storage Gateway’s capability to present a view of the S3 bucket as a file system, as shown in the following diagram. This allows us to continue to use legacy applications on-premises while moving to the cloud, without having to re-engineer the applications:
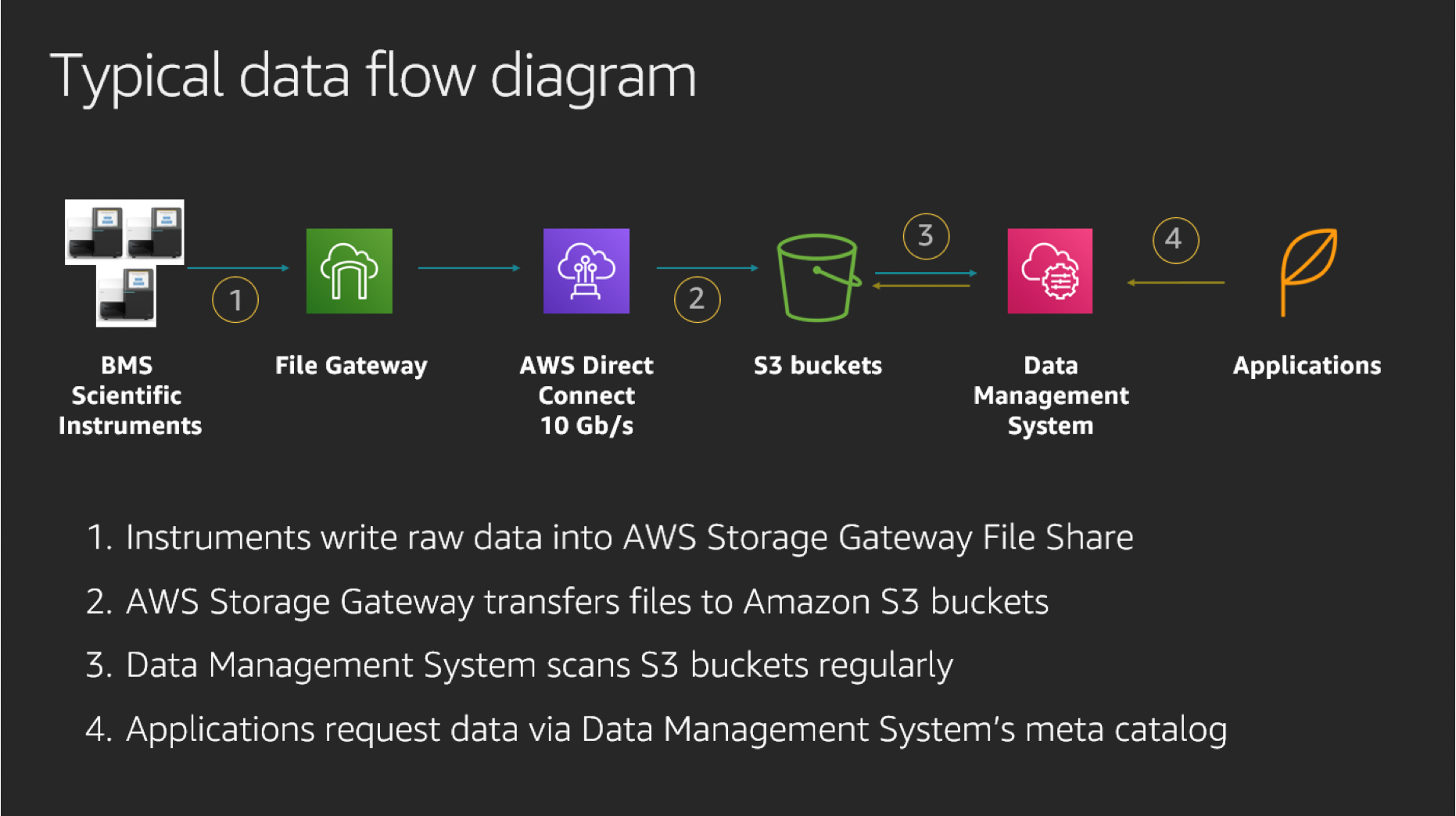
This diagram shows how raw data from scientific instruments, transferred to a Storage Gateway file share, is pushed to corresponding buckets in S3. This data is moved to Amazon S3 through AWS Direct Connect (DX), with a 10-GB/s bandwidth. Upon arrival to S3, data is indexed, registered, and enriched with metadata tags by our data management system. Afterwards, data becomes available for processing by various in-house HPC and scientific applications.
The next architectural diagram illustrates how Bristol Myers Squibb incorporates this typical architectural pattern for the needs of complex projects that deal with managing large imaging datasets. In this project, Storage Gateway is central to the data flow to S3, and along with a few other AWS services, provides a complete solution for Bristol Myers Squibb:

The scientific datasets produced in labs are temporarily written to local NAS storage using common storage protocols. This is because many of them are not able to write data directly to S3, often because of licensing considerations. As initial data ingests, we move legacy datasets using AWS Snowball, which is an effective approach when seeking to upload hundreds of terabytes of data at once. Other data continues integration over a DX line as well. Multiple Storage Gateway appliances (virtual and hardware) at each geographical location copy new data in automated and asynchronous flows to Amazon S3.
Next, Amazon S3 buckets are scanned by internal data management systems and are enriched with technical metadata before integrating within data lakes. Since these images arrive in different formats, we involve third-party API calls to convert them into standard JPEG or TIFF formats. We also get additional tagging, analysis, and insights derived from domain-specific applications. Often visualization of this data requires ML-based algorithms, which are done with GPU-based EC2 instances.
Storage Gateway can be deployed either as a virtual machine in a customer’s data center, in Amazon EC2, or as a hardware appliance installed on-premises. The implementation of the gateway on-premises offers low latency access to data stored in Amazon S3.
We found that complete ownership and low latency with the Storage Gateway Hardware Appliance is especially useful at Bristol Myers Squibb. There is a delay in retrieving data when you access data from Amazon S3 for the first time. However, subsequent retrievals for that data are quicker as long as the files still reside in and are served from the storage cache. The hardware appliance comes in two sizes, either 5 TB or 12 TB of usable all-flash cache. During the appliance activation process, the provisioning software automatically configures the appropriate RAID protection for the cache SSDs, providing an easy and seamless setup process for the customer. If you start off with a 5-TB appliance, you can later expand to a 12-TB appliance if needed.
Lessons learned using Storage Gateway
The three biggest lessons we learned while working with Storage Gateway were:
- Pay close attention to network configuration, proxy, and firewall settings.
- Test the performance from actual scientific instruments before going in production.
- Exercise caution while sharing the same Amazon S3 bucket between multiple Storage Gateways.
In many cases, proprietary network settings might be responsible for slow data transfer by Storage Gateway. It may take some time and a system administrator’s expertise to tweak them in the most optimal way. Since many scientific instruments have different I/O patterns, it is also highly advisable to conduct tests with actual laboratory equipment. This helps you ensure your new data flow pipeline can withstand high writes or prolonged usage, often measured in days. Based on our experience, we recommend using DX with a Storage Gateway hardware appliance. Efficient data transfer by Storage Gateway and the consistent network connectivity of DX delivers a positive user experience. Last but not least, extra caution is needed while sharing datasets between multiple Storage Gateways.
Sharing the same Amazon S3 bucket between multiple Storage Gateways
Why must you take precaution when sharing the same Amazon S3 bucket between multiple Storage Gateways? Well, imagine Storage Gateway “A” remains unaware of Amazon S3 changes made through Storage Gateway “B,” and RefreshCache API calls are required to update Storage Gateway “A.” The RefreshCache process then takes many minutes or hours depending on the size of your dataset. The simple, but effective, solution for preventing multiple Storage Gateways from writing into the same S3 bucket is using an S3 access policy like this one:

In this policy example, we deny DeleteObject and PutObject actions for all users except the one with UserID “TestUser.”
Summary
Bristol Myers Squibb has been using Amazon S3 and Storage Gateway for years, moving hundreds of terabytes of scientific data from our local premises to the AWS Cloud, daily. We have found AWS services to be efficient, reliable, and cost-effective, often bringing in more flexibility and scalability while reducing our dependency on hardware infrastructure.
The AWS Storage portfolio consists of many other great products, which we also use extensively at Bristol Myers Squibb. In my next blog post, coming soon, I will measure Storage Gateway I/O performance with different EBS volume types, discussing some cost saving techniques. We hope sharing our experience helps you to manage scientific data in your next life science project. Thanks for reading, and please comment with any questions you may have.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.