AWS Storage Blog
How to securely share application log files with third parties
What do we do when our applications fail, and we must provide instance-level log data to external entities for troubleshooting purposes? It’s best to limit direct human interaction with our production resources, so we often see temporary access provided for a fixed period. For highly regulated industries, the approval process for production access can be challenging and not permitted. In these cases, having users connect to our Amazon Elastic Compute Cloud (Amazon EC2) instances to retrieve them is out of the question.
An Amazon CloudWatch Agent can improve this situation with its log file collection feature, which automates ingesting files into CloudWatch Logs. However, this solution is not appropriate for every scenario, such as sharing them with third parties (e.g., partners and ISV support teams). Customers must grant those third parties’ access with specific permission to their AWS account, which can be a non-starter for many Security Operations (SecOps) teams. Furthermore, many external entities prefer to receive log files as traditional ZIP archives.
We find that our customers need a process that continuously collects the application logs and stores them on secure, cost-optimized storage. These collected log files need to be securely made available to external parties in a manner that is easy to manage and auditable by the SecOps team.
In this blog post, we provide you a managed solution to centralize, efficiently store, and securely access application logs running on internal systems. AWS Managed Services make it easy to implement application log sharing pipelines without requiring custom code and undifferentiated heavy lifting. The implementation we review in this blog covers:
- Centralizing log files using Amazon FSx for Windows File Server
- Synchronizes those files to an Amazon S3 bucket with AWS DataSync
- Providing secure access to external parties using AWS Transfer Family
Architecture from end-to-end
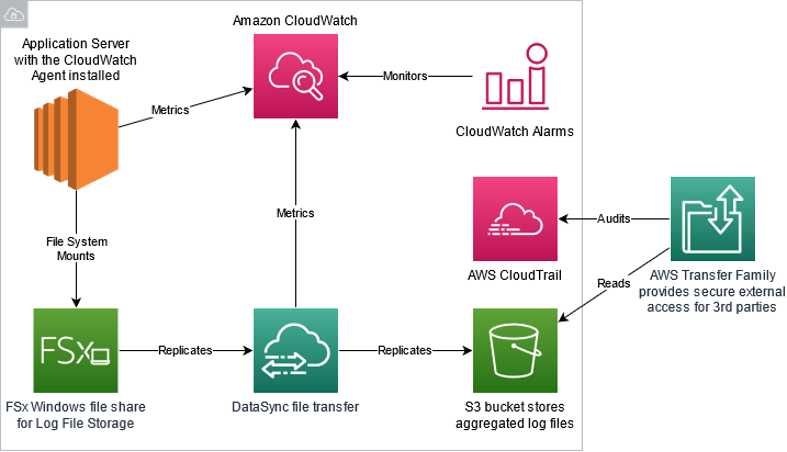
Figure 1: System architecture
Figure 1 highlights the solution architecture from a shared central log store through external entity access. The steps for configuration are as follows:
- Configure an Amazon EC2 instances to mount Server Message Block (SMB) shares provided by Amazon FSx and configure applications to store log files in that location.
- Use DataSync to replicate log files stored on Amazon FSx to an Amazon S3 bucket.
- Configure AWS Transfer Family to provide named user access to the appropriate log files in the Amazon S3 bucket with an SFTP protocol.
We used AWS Cloud Development Kit (CDK) to generate the template for deploying an environment for testing this pattern. The template takes about two hours to launch all resources, such as Amazon FSx along with the remaining Windows and Linux EC2 infrastructure to synchronize files to Amazon S3 and make them available via AWS Transfer Family using SFTP. See the home page of this repository for more information regarding any customizations.
We briefly cover each component and detail how to build out the solution independently. We also provide links to the applicable documentation if you are interested in customizing this to suit your use case.
Step 1: Centralize application files into Amazon FSx for Windows File Server
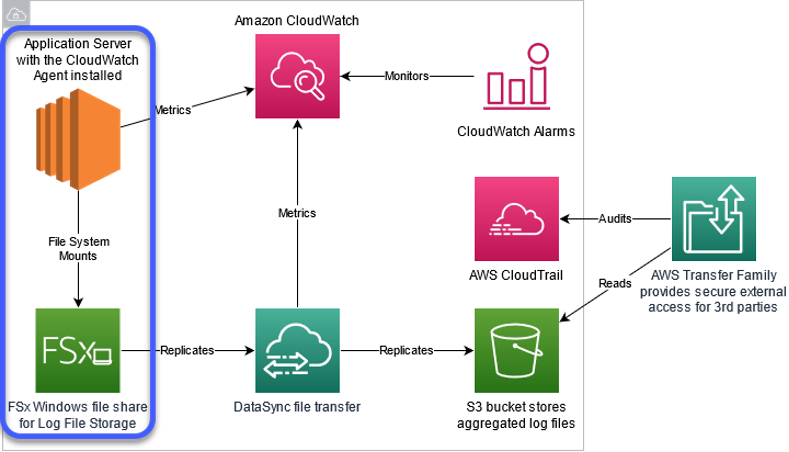
Figure 2: In this section, we cover the services highlighted in centralized log storage. See step 1
Amazon FSx supports four widely-used file systems: NetApp ONTAP, OpenZFS, Windows File Server, and Lustre. The solution architecture begins with provisioning an Amazon FSx file system for Windows File Server. In the example below, the Amazon FSx file system uses the settings recommended for production environments, including Multi-AZ for high availability and SSD storage for increased performance.
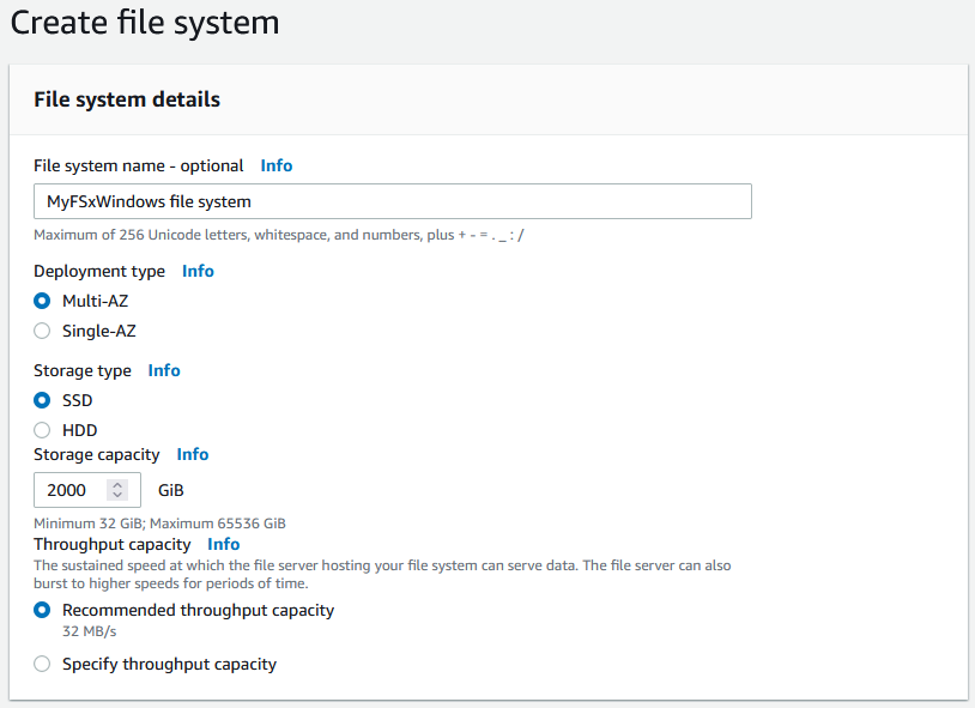
Figure 3: Amazon FSx Create file system console options
Amazon FSx for Windows File Server is a fully managed, highly reliable, and scalable file storage service accessible over the industry-standard Server Message Block (SMB) protocol. It is built on Windows Server, delivering administrative features such as Microsoft Active Directory (AD) integration and user quotas. Amazon FSx for Windows File Server serves as a central collection point that is very easy to configure. Customers can automate mounting the file share to their log directories using AWS Systems Manager Run Command or Group Policy. After attaching the file share, configure the application to write its log files to this location.
If you need to adapt these steps to do the same thing for your Linux-based workloads, you can. This modification requires replacing Amazon FSx for Windows File Server with Amazon Elastic File System, a fully managed NFS file system. For hybrid environments, consider using Amazon FSx for NetApp ONTAP. ONTAP is a multi-protocol file share supporting Windows SMB and Linux NFS clients.
For the Linux-based workload use case, use the following resources:
- Create your Amazon EFS file system
- Automate mounting Amazon EFS File Systems from the EC2 Launch Instance Wizard
- Getting started with Amazon FSx for NetApp ONTAP
Step 2: Replicate application log files into an Amazon S3 bucket
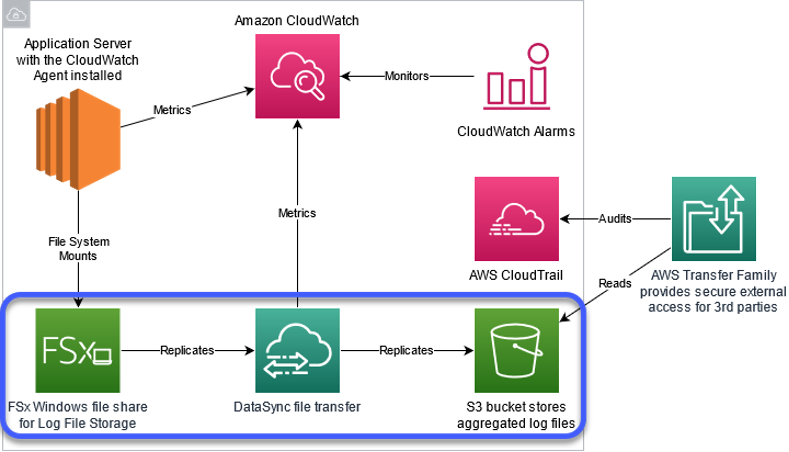
Figure 4: In this section, we’ll cover the services highlighted in log file replication. See step 2
After centralizing the log files using Amazon FSx, you can configure AWS DataSync to replicate the Amazon FSx file share to an Amazon S3 bucket. To start, we create two locations for DataSync to use. One location is the Amazon FSx file share that we just provisioned. The second location is the Amazon S3 bucket to house all the aggregated log files. Once that is complete, we create a task that contains all of the replication settings, including scheduling, archiving, and throttling controls. For more information, see the Configuring DataSync replication between Amazon FSx for Windows File Server to Amazon S3 What’s New post.
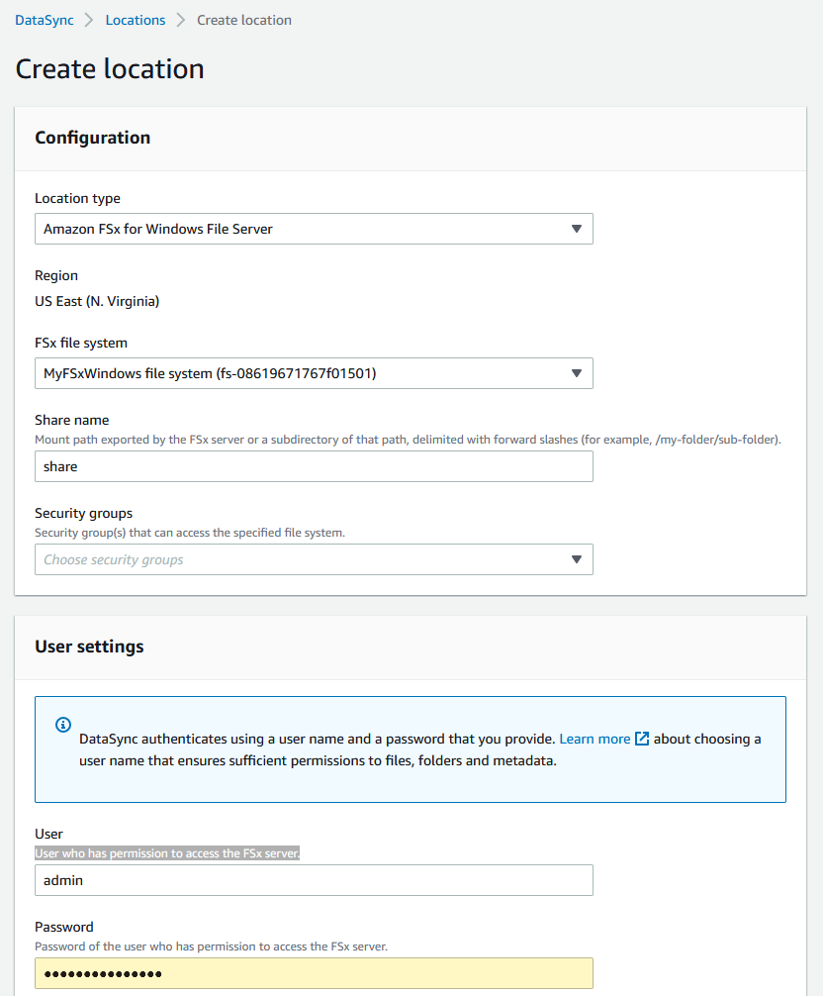
Figure 5: Amazon FSx for Windows File Server create file system console options
AWS DataSync supports a direct connection to each Windows EC2 instance. However, this approach does become an operationally complex model at scale. AWS DataSync uses end-to-end encryption to move data securely in addition to exposing scheduling, archiving, and throttling controls. The service is serverless, and customers only pay for the data copied.
Once the task runs successfully, your application logs should be replicating to the Amazon S3 bucket. You can use Amazon S3 Lifecycle Policy to enforce retention limits, change storage tiers, and automatically remove old files.
Step 3: Configure secure, auditable access to application log files using the AWS Transfer Family
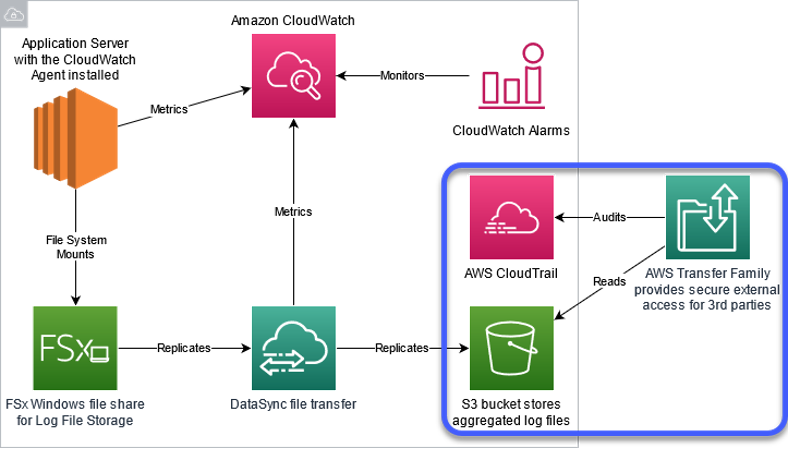
Figure 6: In this section, we’ll cover the services highlighted in External entity access. See step 3
Finally, we use AWS Transfer Family to expose the S3 bucket securely over Secure Shell (SSH) File Transfer Protocol. The service supports several protocols. See the AWS documentation here for how to create an SFTP-enabled server.
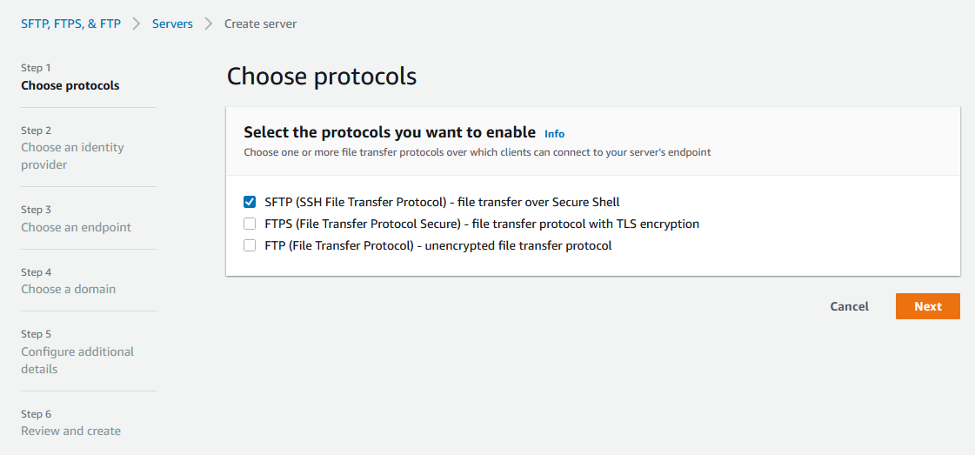
Figure 7: AWS Transfer Family console options
The AWS Transfer Family is serverless and enables customers to control access and audit usage through AWS CloudTrail. CloudTrail monitors the cloud resources and creates a history of any AWS API calls within the account, including calls made using the AWS Management Console, AWS SDKs, the command line tools, and higher-level AWS services. It also collects metadata such as the source IP address, the caller’s AWS IAM identity, and related properties.
Step 4: Monitor the pipeline’s operational health
We now have an end-to-end solution that automatically replicates the EC2 fleet’s application logs to Amazon S3 and makes them available to external partners. The pipeline is built upon managed services and requires little to no maintenance. To verify the operational health of our log pipeline, we use Amazon CloudWatch which provides us visibility into this solution’s performance so that we can detect, respond to, and optimize our AWS resource utilization.
A standard solution integrates the services’ built-in CloudWatch Metrics with CloudWatch Alarms. Following an alarm triggering, you can automatically respond through different actions, such as sending an email, invoking custom AWS Lambda functions, and using Metric Streams to notify SaaS solutions. This flexibility enables you to integrate your existing processes and preferred tooling quickly and easily.
Step 5: Cleaning up
To avoid ongoing charges for the resources you created, you should first empty the S3 buckets from Step 2. Next, delete the CloudFormation stack to remove the managed resources. Suppose you configured all resources manually. In that case, delete the Transfer Family server, DataSync resources (agent, task, and locations), FSx for Windows File Server file system, and any temporary EC2 instances.
Please refer to Amazon FSx for Windows Filer Server, AWS DataSync, AWS Transfer Family, Amazon CloudWatch, and Amazon S3 pricing pages for costing details.
Summary
Collecting application log files continuously and sharing them securely with external parties can be challenging. This problem is even more complicated when the security policy does not permit direct access to compute resources. This post demonstrated how you could securely enable external partner access to application log files. It uses AWS Managed Services to avoid requiring direct access to the compute instances or custom code. Also, you can freely mix and match individual components to meet particular use cases. Try out the sample CDK code and see how easy it is to provide specific file-level access in a secure, repeatable manner.
To learn more about AWS Transfer Family and other resources mentioned in this blog, check out the following resources:
Thanks for reading this blog post. If you have any comments or questions, please leave them in the comments section.