AWS Big Data Blog
Build a Serverless Architecture to Analyze Amazon CloudFront Access Logs Using AWS Lambda, Amazon Athena, and Amazon Kinesis Analytics
Nowadays, it’s common for a web server to be fronted by a global content delivery service, like Amazon CloudFront. This type of front end accelerates delivery of websites, APIs, media content, and other web assets to provide a better experience to users across the globe.
The insights gained by analysis of Amazon CloudFront access logs helps improve website availability through bot detection and mitigation, optimizing web content based on the devices and browser used to view your webpages, reducing perceived latency by caching of popular object closer to its viewer, and so on. This results in a significant improvement in the overall perceived experience for the user.
This blog post provides a way to build a serverless architecture to generate some of these insights. To do so, we analyze Amazon CloudFront access logs both at rest and in transit through the stream. This serverless architecture uses Amazon Athena to analyze large volumes of CloudFront access logs (on the scale of terabytes per day), and Amazon Kinesis Analytics for streaming analysis.
The analytic queries in this blog post focus on three common use cases:
- Detection of common bots using the user agent string
- Calculation of current bandwidth usage per Amazon CloudFront distribution per edge location
- Determination of the current top 50 viewers
However, you can easily extend the architecture described to power dashboards for monitoring, reporting, and trigger alarms based on deeper insights gained by processing and analyzing the logs. Some examples are dashboards for cache performance, usage and viewer patterns, and so on.
Following we show a diagram of this architecture.
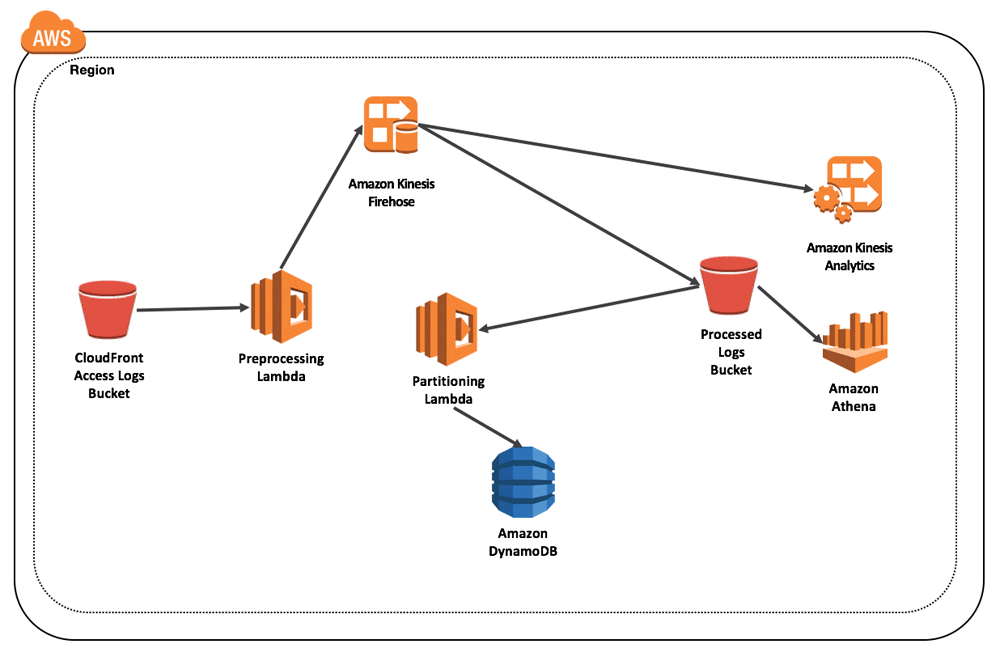
Prerequisites
Before you set up this architecture, install the AWS Command Line Interface (AWS CLI) tool on your local machine, if you don’t have it already.
Setup summary
The following steps are involved in setting up the serverless architecture on the AWS platform:
- Create an Amazon S3 bucket for your Amazon CloudFront access logs to be delivered to and stored in.
- Create a second Amazon S3 bucket to receive processed logs and store the partitioned data for interactive analysis.
- Create an Amazon Kinesis Firehose delivery stream to batch, compress, and deliver the preprocessed logs for analysis.
- Create an AWS Lambda function to preprocess the logs for analysis.
- Configure Amazon S3 event notification on the CloudFront access logs bucket, which contains the raw logs, to trigger the Lambda preprocessing function.
- Create an Amazon DynamoDB table to look up partition details, such as partition specification and partition location.
- Create an Amazon Athena table for interactive analysis.
- Create a second AWS Lambda function to add new partitions to the Athena table based on the log delivered to the processed logs bucket.
- Configure Amazon S3 event notification on the processed logs bucket to trigger the Lambda partitioning function.
- Configure Amazon Kinesis Analytics application for analysis of the logs directly from the stream.
ETL and preprocessing
In this section, we parse the CloudFront access logs as they are delivered, which occurs multiple times in an hour. We filter out commented records and use the user agent string to decipher the browser name, the name of the operating system, and whether the request has been made by a bot. For more details on how to decipher the preceding information based on the user agent string, see user-agents 1.1.0 in the Python documentation.
We use the Lambda preprocessing function to perform these tasks on individual rows of the access log. On successful completion, the rows are pushed to an Amazon Kinesis Firehose delivery stream to be persistently stored in an Amazon S3 bucket, the processed logs bucket.
To create a Firehose delivery stream with a new or existing S3 bucket as the destination, follow the steps described in Create a Firehose Delivery Stream to Amazon S3 in the S3 documentation. Keep most of the default settings, but select an AWS Identity and Access Management (IAM) role that has write access to your S3 bucket and specify GZIP compression. Name the delivery stream CloudFrontLogsToS3.
Another pre-requisite for this setup is to create an IAM role that provides the necessary permissions our AWS Lambda function to get the data from S3, process it, and deliver it to the CloudFrontLogsToS3 delivery stream.
Let’s use the AWS CLI to create the IAM role using the following the steps:
- Create the IAM policy (lambda-exec-policy) for the Lambda execution role to use.
- Create the Lambda execution role (lambda-cflogs-exec-role) and assign the service to use this role.
- Attach the policy created in step 1 to the Lambda execution role.
To download the policy document to your local machine, type the following command.
aws s3 cp s3://aws-bigdata-blog/artifacts/Serverless-CF-Analysis/preprocessing-lambda/lambda-exec-policy.json <path_on_your_local_machine>
Following is the lambda-exec-policy.json file, which is the IAM policy used by the Lambda execution role.
Edit the policy, replacing “bucket-name” with the name of the bucket you created for your Amazon Cloudfront access logs to be delivered to (step 1 in Setup).
Then create the IAM policy used by Lambda execution role, by typing the following command.
aws iam create-policy --policy-name lambda-exec-policy --policy-document file://<path>/lambda-exec-policy.json
To download the assume policy document to your local machine, type the following command.
aws s3 cp s3://aws-bigdata-blog/artifacts/Serverless-CF-Analysis/preprocessing-lambda/assume-lambda-policy.json <path_on_your_local_machine>
Following is the assume-lambda-policy.json file, to grant Lambda permission to assume a role.
To create the AWS Lambda execution role and assign the service to use this role, type the following command.
aws iam create-role --role-name lambda-cflogs-exec-role --assume-role-policy-document file://<path>/assume-lambda-policy.json
To attach the policy (lambda-exec-policy) created to the AWS Lambda execution role (lambda-cflogs-exec-role), type the following command.
aws iam attach-role-policy --role-name lambda-cflogs-exec-role --policy-arn arn:aws:iam::<your-account-id>:policy/lambda-exec-policy
Now that we have created the CloudFrontLogsToS3 Firehose delivery stream and the lambda-cflogs-exec-role IAM role for Lambda, the next step is to create a Lambda preprocessing function.
This Lambda preprocessing function parses the CloudFront access logs delivered into the S3 bucket and performs a few transformation and mapping operations on the data. The Lambda function adds descriptive information, such as the browser and the operating system that were used to make this request based on the user agent string found in the logs. The Lambda function also adds information about the web distribution to support scenarios where CloudFront access logs are delivered to a centralized S3 bucket from multiple distributions. With the solution in this blog post, you can get insights across distributions and their edge locations.
Use the Lambda Management Console to create a new Lambda function with a Python 2.7 runtime and the s3-get-object-python blueprint. Open the console, and on the Configure triggers page, choose the name of the S3 bucket where the CloudFront access logs are delivered. Choose Put for Event type. For Prefix, type the name of the prefix, if any, for the folder where CloudFront access logs are delivered, for example cloudfront-logs/. To invoke Lambda to retrieve the logs from the S3 bucket as they are delivered, select Enable trigger.

Choose Next and provide a function name to identify this Lambda preprocessing function.

For Code entry type, choose Upload a file from Amazon S3. For S3 link URL, type https://s3.amazonaws.com/aws-bigdata-blog/artifacts/Serverless-CF-Analysis/preprocessing-lambda/prep-data.zip. In the section, also create an environment variable with the key KINESIS_FIREHOSE_STREAM and a value with the name of the Firehose delivery stream as CloudFrontLogsToS3.

Choose lambda-cflogs-exec-role as the IAM role for the Lambda function, and type prep-data.lambda_handler for the value for Handler.

Choose Next, and then choose Create Lambda.
Table creation in Amazon Athena
In this step, we will build the Athena table. Use the Athena console in the same region and create the table using the query editor.
Creation of the Athena partition
A popular website with millions of requests each day routed using Amazon CloudFront can generate a large volume of logs, on the order of a few terabytes a day. We strongly recommend that you partition your data to effectively restrict the amount of data scanned by each query. Partitioning significantly improves query performance and substantially reduces cost. The Lambda partitioning function adds the partition information to the Athena table for the data delivered to the preprocessed logs bucket.
Before delivering the preprocessed Amazon CloudFront logs file into the preprocessed logs bucket, Amazon Kinesis Firehose adds a UTC time prefix in the format YYYY/MM/DD/HH. This approach supports multilevel partitioning of the data by year, month, date, and hour. You can invoke the Lambda partitioning function every time a new processed Amazon CloudFront log is delivered to the preprocessed logs bucket. To do so, configure the Lambda partitioning function to be triggered by an S3 Put event.
For a website with millions of requests, a large number of preprocessed logs can be delivered multiple times in an hour—for example, at the interval of one each second. To avoid querying the Athena table for partition information every time a preprocessed log file is delivered, you can create an Amazon DynamoDB table for fast lookup.
Based on the year, month, data and hour in the prefix of the delivered log, the Lambda partitioning function checks if the partition specification exists in the Amazon DynamoDB table. If it doesn’t, it’s added to the table using an atomic operation, and then the Athena table is updated.
Type the following command to create the Amazon DynamoDB table.
Here the following is true:
- PartitionSpec is the hash key and is a representation of the partition signature—for example, year=”2017”; month=”05”; day=”15”; hour=”10”.
- Depending on the rate at which the processed log files are delivered to the processed log bucket, you might have to increase the ReadCapacityUnits and WriteCapacityUnits values, if these are throttled.
The other attributes besides PartitionSpec are the following:
- PartitionPath – The S3 path associated with the partition.
- PartitionType – The type of partition used (Hour, Month, Date, Year, or ALL). In this case, ALL is used.
Next step is to create the IAM role to provide permissions for the Lambda partitioning function. You require permissions to do the following:
- Look up and write partition information to DynamoDB.
- Alter the Athena table with new partition information.
- Perform Amazon CloudWatch logs operations.
- Perform Amazon S3 operations.
To download the policy document to your local machine, type following command.
To download the assume policy document to your local machine, type the following command.
To create the Lambda execution role and assign the service to use this role, type the following command.
Let’s use the AWS CLI to create the IAM role using the following three steps:
- Create the IAM policy(lambda-partition-exec-policy) used by the Lambda execution role.
- Create the Lambda execution role (lambda-partition-execution-role)and assign the service to use this role.
- Attach the policy created in step 1 to the Lambda execution role.
To create the IAM policy used by Lambda execution role, type the following command.
To create the Lambda execution role and assign the service to use this role, type the following command.
To attach the policy (lambda-partition-exec-policy) created to the AWS Lambda execution role (lambda-partition-execution-role), type the following command.
Following is the lambda-partition-function-execution-policy.json file, which is the IAM policy used by the Lambda execution role.
Download the .jar file containing the Java deployment package to your local machine.
From the AWS Management Console, create a new Lambda function with Java8 as the runtime. Select the Blank Function blueprint.
On the Configure triggers page, choose the name of the S3 bucket where the preprocessed logs are delivered. Choose Put for the Event Type. For Prefix, type the name of the prefix folder, if any, where preprocessed logs are delivered by Firehose—for example, out/. For Suffix, type the name of the compression format that the Firehose stream (CloudFrontLogToS3) delivers the preprocessed logs —for example, gz. To invoke Lambda to retrieve the logs from the S3 bucket as they are delivered, select Enable Trigger.

Choose Next and provide a function name to identify this Lambda partitioning function.

Choose Java8 for Runtime for the AWS Lambda function. Choose Upload a .ZIP or .JAR file for the Code entry type, and choose Upload to upload the downloaded aws-lambda-athena-1.0.0.jar file.
For the source code and instruction on how to build the .jar file see, https://github.com/awslabs/serverless-cf-analysis.
Next, create the following environment variables for the Lambda function:
- TABLE_NAME – The name of the Athena table (for example, cf_logs).
- PARTITION_TYPE – The partition to be created based on the Athena table for the logs delivered to the sub folders in S3 bucket based on Year, Month, Date, Hour, or Set this to ALL to use Year, Month, Date, and Hour.
- DDB_TABLE_NAME – The name of the DynamoDB table holding partition information (for example, athenapartitiondetails).
- ATHENA_REGION – The current AWS Region for the Athena table to construct the JDBC connection string.
- S3_STAGING_DIR – The Amazon S3 location where your query output is written. The JDBC driver asks Athena to read the results and provide rows of data back to the user (for example, s3://<BUCKET_NAME>/<folder>/).

To configure the function handler and IAM, for Handler copy and paste the name of the handler: com.amazonaws.services.lambda.CreateAthenaPartitionsBasedOnS3EventWithDDB::handleRequest. Choose the existing IAM role, lambda-partition-execution-role.

Choose Next and then Create Lambda.
Interactive analysis using Amazon Athena
In this section, we analyze the historical data that’s been collected since we added the partitions to the Amazon Athena table for data delivered to the preprocessing logs bucket.
Scenario 1 is robot traffic by edge location.
Scenario 2 is total bytes transferred per distribution for each edge location for your website.
Scenario 3 is the top 50 viewers of your website.
Streaming analysis using Amazon Kinesis Analytics
In this section, you deploy a stream processing application using Amazon Kinesis Analytics to analyze the preprocessed Amazon CloudFront log streams. This application analyzes directly from the Amazon Kinesis Stream as it is delivered to the preprocessing logs bucket. The stream queries in section are focused on gaining the following insights:
- The IP address of the bot, identified by its Amazon CloudFront edge location, that is currently sending requests to your website. The query also includes the total bytes transferred as part of the response.
- The total bytes served per distribution per population for your website.
- The top 10 viewers of your website.
To download the firehose-access-policy.json file, type the following.
To download the kinesisanalytics-policy.json file, type the following.
Before we create the Amazon Kinesis Analytics application, we need to create the IAM role to provide permission for the analytics application to access Amazon Kinesis Firehose stream.
Let’s use the AWS CLI to create the IAM role using the following three steps:
- Create the IAM policy(firehose-access-policy) for the Lambda execution role to use.
- Create the Lambda execution role (ka-execution-role) and assign the service to use this role.
- Attach the policy created in step 1 to the Lambda execution role.
Following is the firehose-access-policy.json file, which is the IAM policy used by Kinesis Analytics to read Firehose delivery stream.
Following is the assume-kinesisanalytics-policy.json file, to grant Amazon Kinesis Analytics permissions to assume a role.
To create the IAM policy used by Analytics access role, type the following command.
To create the Analytics execution role and assign the service to use this role, type the following command.
To attach the policy (irehose-access-policy) created to the Analytics execution role (ka-execution-role), type the following command.
To deploy the Analytics application, first download the configuration file and then modify ResourceARN and RoleARN for the Amazon Kinesis Firehose input configuration.
To download the Analytics application configuration file, type the following command.
To deploy the application, type the following command.
To start the application, type the following command.
SQL queries using Amazon Kinesis Analytics
Scenario 1 is a query for detecting bots for sending request to your website detection for your website.
Scenario 2 is a query for total bytes transferred per distribution for each edge location for your website.
Scenario 3 is a query for the top 50 viewers for your website.
Conclusion
Following the steps in this blog post, you just built an end-to-end serverless architecture to analyze Amazon CloudFront access logs. You analyzed these both in interactive and streaming mode, using Amazon Athena and Amazon Kinesis Analytics respectively.
By creating a partition in Athena for the logs delivered to a centralized bucket, this architecture is optimized for performance and cost when analyzing large volumes of logs for popular websites that receive millions of requests. Here, we have focused on just three common use cases for analysis, sharing the analytic queries as part of the post. However, you can extend this architecture to gain deeper insights and generate usage reports to reduce latency and increase availability. This way, you can provide a better experience on your websites fronted with Amazon CloudFront.
In this blog post, we focused on building serverless architecture to analyze Amazon CloudFront access logs. Our plan is to extend the solution to provide rich visualization as part of our next blog post. You can find the code and JSON documents used in this post in our Github repository.
About the Authors
 Rajeev Srinivasan is a Senior Solution Architect for AWS. He works very close with our customers to provide big data and NoSQL solution leveraging the AWS platform and enjoys coding . In his spare time he enjoys riding his motorcycle and reading books.
Rajeev Srinivasan is a Senior Solution Architect for AWS. He works very close with our customers to provide big data and NoSQL solution leveraging the AWS platform and enjoys coding . In his spare time he enjoys riding his motorcycle and reading books.
 Sai Sriparasa is a consultant with AWS Professional Services. He works with our customers to provide strategic and tactical big data solutions with an emphasis on automation, operations & security on AWS. In his spare time, he follows sports and current affairs.
Sai Sriparasa is a consultant with AWS Professional Services. He works with our customers to provide strategic and tactical big data solutions with an emphasis on automation, operations & security on AWS. In his spare time, he follows sports and current affairs.
 Chris Geisel is an enterprise support lead at AWS. The technical account managers on his team handle the largest customers in western Canada, providing the highest level of premium support. In his free time, he enjoys writing python and leveraging AWS Serverless technologies for personal projects, as well as coaching youth soccer.
Chris Geisel is an enterprise support lead at AWS. The technical account managers on his team handle the largest customers in western Canada, providing the highest level of premium support. In his free time, he enjoys writing python and leveraging AWS Serverless technologies for personal projects, as well as coaching youth soccer.
Related
Analyzing VPC Flow Logs with Amazon Kinesis Firehose, Amazon Athena, and Amazon QuickSight
