AWS Machine Learning Blog
Deploy multiple machine learning models for inference on AWS Lambda and Amazon EFS
You can deploy machine learning (ML) models for real-time inference with large libraries or pre-trained models. Common use cases include sentiment analysis, image classification, and search applications. These ML jobs typically vary in duration and require instant scaling to meet peak demand. You want to process latency-sensitive inference requests and pay only for what you use without having to manage any of the underlying infrastructure.
In this post, we demonstrate how to deploy ML models for inference using AWS Lambda and Amazon Elastic File System (Amazon EFS).
Solution overview
To create a Lambda function implementing ML inference, we should be able to import the necessary libraries and load the ML model. When doing so, the overall size of those dependencies often goes beyond the current Lambda limits in the deployment package size (10 GB for container images and 50 MB for .zip files). One way of solving this is to minimize the libraries to ship with the function code, and then download the model from an Amazon Simple Storage Service (Amazon S3) bucket straight to memory. Some functions require external libraries that may be too large. In June 2020, AWS added Amazon EFS support to Lambda, so now it’s even easier and faster to load large models and files to memory for ML inference workloads.
Using Lambda and Amazon EFS provides a cost-effective, elastic, and highly performant solution for your ML inferencing workloads. You only pay for each inference that you run and the storage consumed by your model on the file system. With Amazon EFS, which provides petabyte-scale elastic storage, your architecture can automatically scale up and down based on the needs of your workload.
You can improve prediction times because this architecture allows you to load large ML models at low latency, load extra code libraries, and instantaneously load the latest version of your model. This allows you to run ML inference on those ML models concurrently at scale using Lambda invocations. Accessing data from Amazon EFS is as simple as accessing a local file, and the underlying system loads the latest version automatically.
In this post, we present an architectural pattern to deploy ML models for inferencing. We walk through the following steps:
- Create an Amazon EFS file system, access point, and Lambda functions.
- Build and deploy the application using AWS Serverless Application Model (AWS SAM).
- Upload the ML model.
- Perform ML inference.
In this post, we use a language recognition model (EasyOCR) to test our solution.
Architecture overview
To use the Amazon EFS file system from Lambda, you need the following:
- An Amazon Virtual Private Cloud (Amazon VPC)
- An Amazon EFS file system created within that VPC with an access point as an application entry point for your Lambda function
- A Lambda function (in the same VPC and private subnets) referencing the access point
The following diagram illustrates the solution architecture.
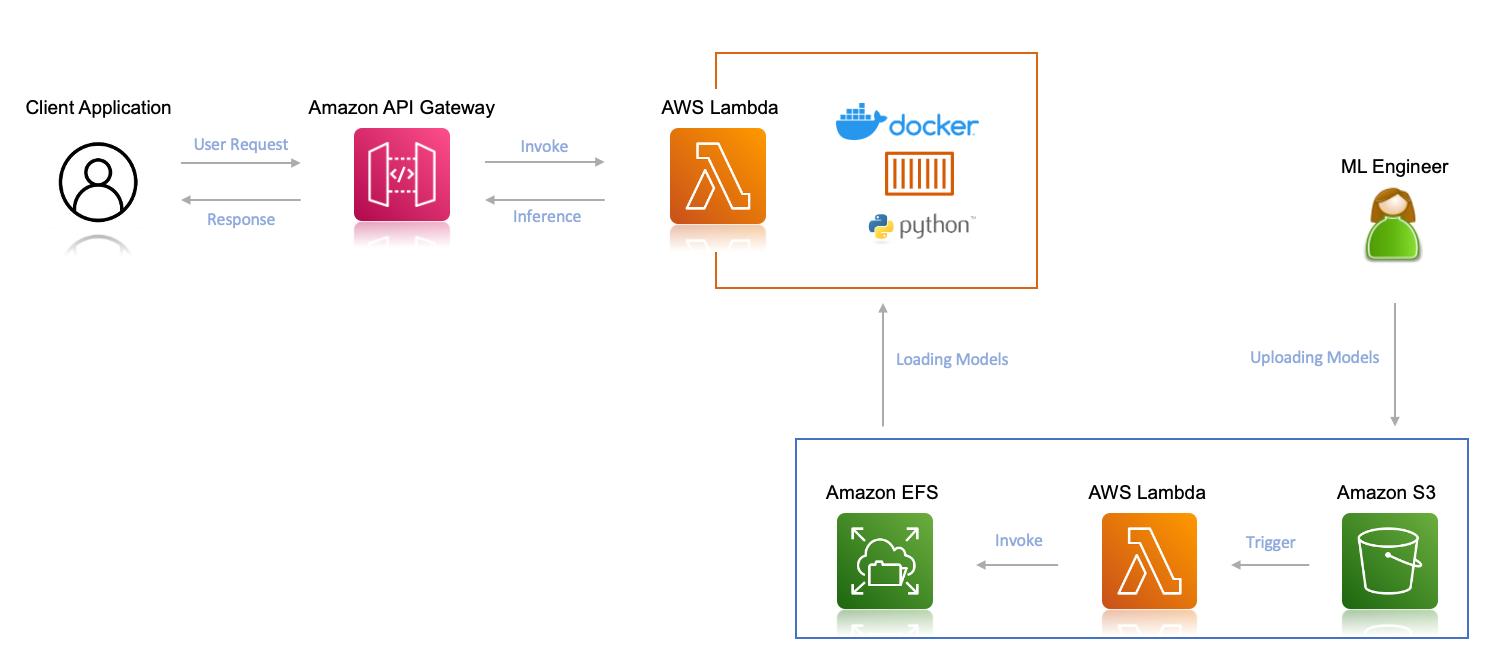
To upload the ML models to your file system, we use a Lambda function that is triggered when you upload the model to your S3 bucket.
In this post, we use an AWS Cloud9 instance and install the AWS SAM CLI on that instance, with the AWS Command Line Interface (AWS CLI) and AWS SAM CLI configured. AWS Cloud9 is a cloud-based integrated development environment (IDE) that lets you write, run, and debug your code with just a browser. To follow along with this post, you can use your AWS Cloud9 instance or any system that has the AWS CLI and AWS SAM CLI installed and configured with your AWS account.
Create an Amazon EFS file system, access point, and Lambda functions
Now we use a single AWS SAM deployment to create the following two serverless applications:
- app1(s3-efs) – The serverless application that transfers the uploaded ML models from your S3 bucket to your file system
- app2(ml-inference) – The serverless application that performs ML inference from the client
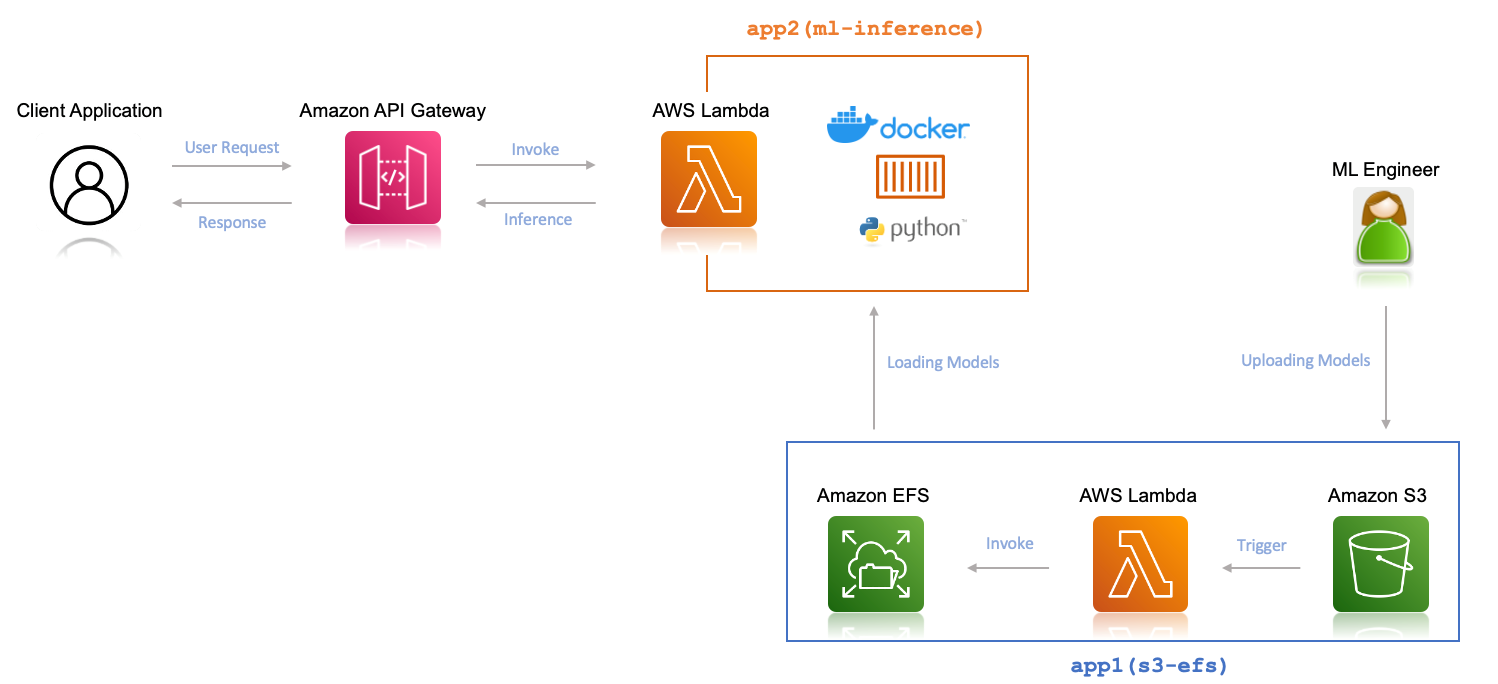
The following diagram illustrates the architecture of these applications.
- First, we need to create an Amazon Elastic Container Registry (Amazon ECR) repository with the following command:
We need this while creating the application via AWS SAM in the next step, so make a note of this newly created repository.
- In the terminal, create a folder (this is going to be the folder you use for your project):
- Create a new serverless application in AWS SAM using the following command:
- Choose Custom Template Location (
Choice: 2) as the template source, and provide the following GitHub template location:https://github.com/aws-samples/ml-inference-using-aws-lambda-and-amazon-efs.git.
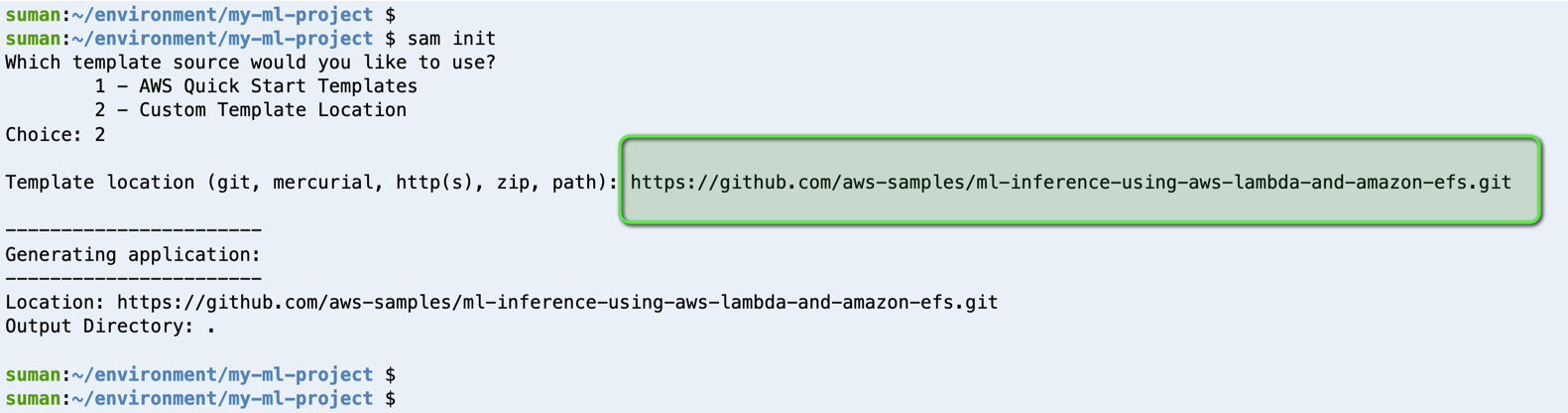
This downloads all the application code from the GitHub repo to your local system.

Before we build our application, let’s spend some time exploring the code.
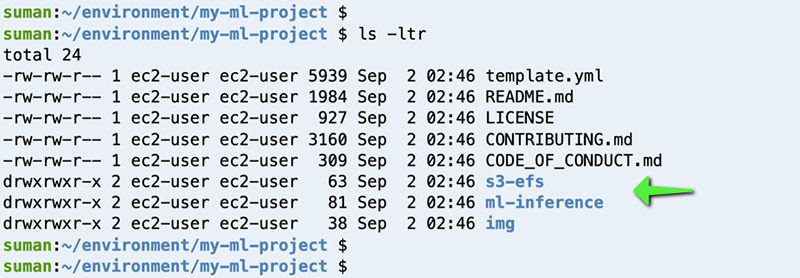
As mentioned before, we use a single AWS SAM template (template.yaml) to create two serverless applications: app1(s3-efs) and app2(ml-inference).
We can see the same in our project folder.
We can read the app.py file located inside the s3-efs folder, which is the Lambda function meant for downloading ML models from your S3 bucket to the your file system.
Similarly, we can read the app.py under the folder ml-inference, which is the Lambda function meant for ML inference from the client. The requirements.txt under the same folder highlights the required Python packages that are used for the application.
We deploy the ml-inference serverless application using a custom Docker container and use the following Dockerfile to build the container image, which is again saved under the same folder ml-inference.
The AWS SAM template file template.yaml, located under the project folder my-ml-project, contains all the resources needed to build the applications.
Build and deploy the AWS SAM application
Now we’re ready to build our application. First, let’s review all the files that we created or edited in the previous section, and make sure nothing is missing.

- From the project directory, run the
sam build –-use-containercommand. - Deploy the application using the
sam deploy –guidedcommand and provide the required information.
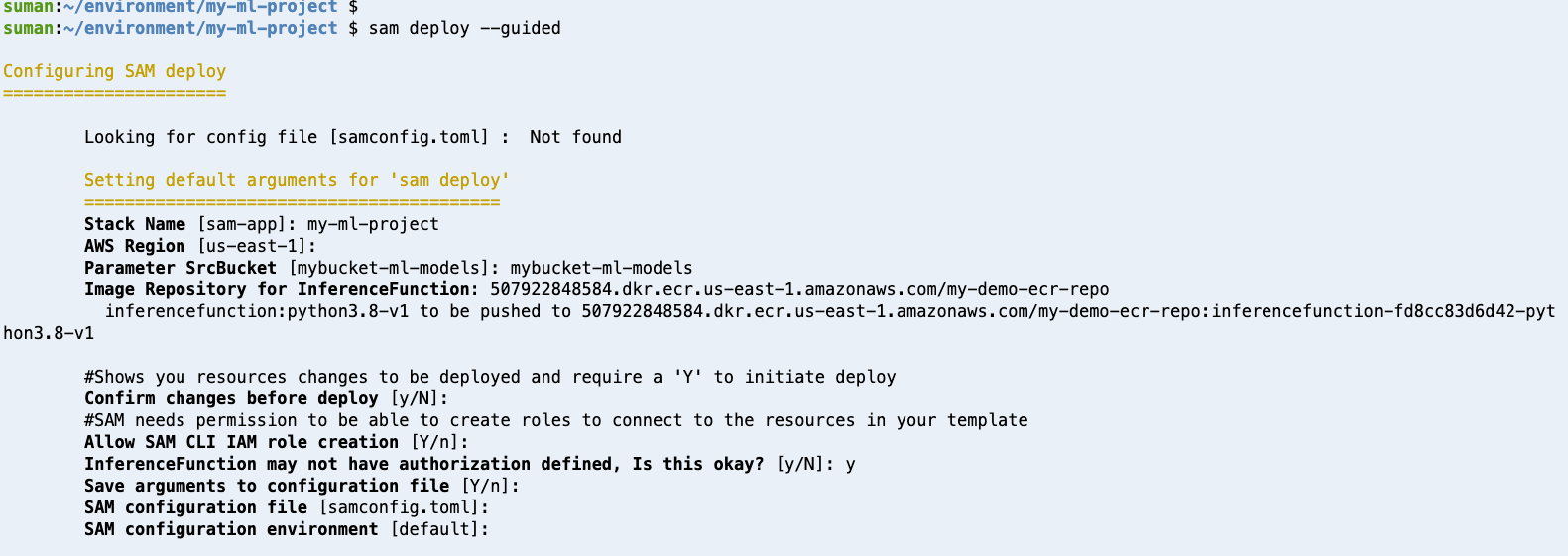
Wait for AWS SAM to deploy the model and create the resources mentioned in the template.
- When deployment is complete, record the API Gateway endpoint URL, which we use for inference next.

Upload the ML model
To have all your models on your Amazon EFS file system, copy all the ML models in your S3 bucket (the same bucket that you specified while deploying the AWS SAM application using sam deploy –guided earlier). All the model files can be found at the EasyOCR Model Hub.
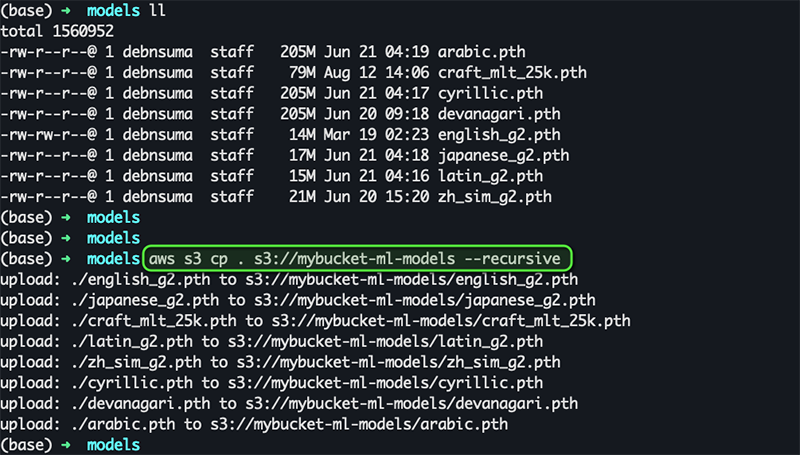
After you upload all the model artifacts on your S3 bucket, it triggers the Lambda function that we deployed in the previous step, which copies all the models in the file system.
Perform ML inference
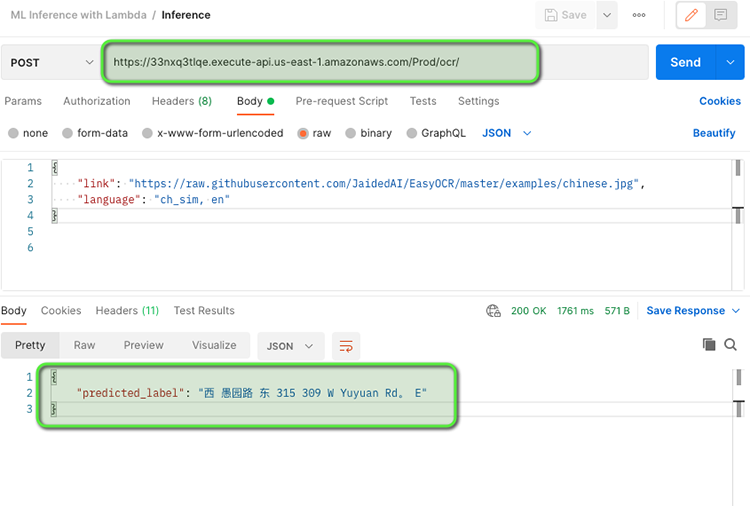
Now we can trigger the Lambda function using the API Gateway endpoint (which you noted earlier while deploying the application using AWS SAM). You can use an API client like Postman to perform the inference. Use the API Gateway endpoint URL you saved earlier and sent the POST request. For this post, we send the following image of a Chinese sign post to the application for text extraction.

We got the predicted_label as expected.
The first invocation (when the function loads and prepares the pre-trained model for inference on CPUs) may take about 30 seconds. To avoid a slow response or a timeout from the API Gateway endpoint, you can use Provisioned Concurrency to keep the function ready. The next invocations should be very quick.
You can also review a quick video walkthrough of this demo.
Model performance
Amazon EFS has two throughput modes: bursting and provisioned.
In bursting mode, the throughput of your file system depends on how much data you’re storing in it. The number of burst credits scales with the amount of storage in your file system. Therefore, if you have an ML model that you expect to grow over time and you drive throughput in proportion to the size, you should use burst throughput mode.
You can monitor the use of credits in Amazon CloudWatch; each Amazon EFS file system has a BurstCreditBalance metric. If you’re consuming all your credits, and the BurstCreditBalance metric is going to zero, you should use provisioned throughput mode and specify the amount of throughput you need. Alternatively, if you have a smaller model but you expect to drive a very high throughput, you can switch to provisioned throughput mode.
With Lambda and Amazon EFS, you get the advantage of caching when you read the same file repeatedly. When you have a new Lambda function that has a cold start, your files are read over the network and then held in the Lambda cache before the function is run. The next time the function is invoked, if the file hasn’t changed, the file is read directly from the cache. Earlier in 2021, we decoupled the amount of read throughput from write throughput. With this, if you configure 100 MB/sec of throughput, you can now read up to 300 MB/sec.
Conclusion
In this post, you learned how to run ML on Lambda to reduce costs, manage variability, and automatically scale without having to manage any underlying infrastructure. You learned how to run an ML inference OCR application with a serverless, scalable, low-latency, and cost-effective architecture using Lambda and Amazon EFS. You can extend this architecture to enable other ML use cases such as image classification, sentiment analysis, and search.
We’re excited to see what interesting applications you build to delight your users and meet your business goals. To get started, see the GitHub repo.
About the Authors
 Newton Jain is a Senior Product Manager responsible for building new experiences for Machine Learning, High Performance Computing (HPC), and Media Processing customers on AWS Lambda. He leads the development of new capabilities to increase performance, reduce latency, improve scalability, enhance reliability, and reduce cost. He also assists AWS customers in defining an effective Serverless strategy for their compute-intensive applications.
Newton Jain is a Senior Product Manager responsible for building new experiences for Machine Learning, High Performance Computing (HPC), and Media Processing customers on AWS Lambda. He leads the development of new capabilities to increase performance, reduce latency, improve scalability, enhance reliability, and reduce cost. He also assists AWS customers in defining an effective Serverless strategy for their compute-intensive applications.
 Vinodh Krishnamoorthy is a Sr Technical Account manager. Currently, he supports AWS Enterprise customers’ creative and transformative spirit of innovation across all technologies, including compute, storage, database, big data, application-level services, networking, serverless, and more. He advocates for his customers and provides strategic technical guidance to help plan and build solutions using best practices, and proactively keep customers’ AWS environments operationally healthy.
Vinodh Krishnamoorthy is a Sr Technical Account manager. Currently, he supports AWS Enterprise customers’ creative and transformative spirit of innovation across all technologies, including compute, storage, database, big data, application-level services, networking, serverless, and more. He advocates for his customers and provides strategic technical guidance to help plan and build solutions using best practices, and proactively keep customers’ AWS environments operationally healthy.
 Suman Debnath is a Principal Developer Advocate at Amazon Web Services, primarily focusing on Storage, Serverless and Machine Learning. He is passionate about large scale distributed systems and is a vivid fan of Python. His background is in storage performance and tool development, where he has developed various performance benchmarking and monitoring tools. You can find him on LinkedIn and follow him on Twitter.
Suman Debnath is a Principal Developer Advocate at Amazon Web Services, primarily focusing on Storage, Serverless and Machine Learning. He is passionate about large scale distributed systems and is a vivid fan of Python. His background is in storage performance and tool development, where he has developed various performance benchmarking and monitoring tools. You can find him on LinkedIn and follow him on Twitter.
 Ananth Vaidyanathan is a Sr. Product Manager at AWS. Having spent time on different teams across Amazon, he has business and technical expertise in helping customers migrate to and innovate on AWS. He loves thinking about new ideas and creating new products that bring value to customers on the cloud. In his spare time, he is an avid reader of world history and an amateur violin player.
Ananth Vaidyanathan is a Sr. Product Manager at AWS. Having spent time on different teams across Amazon, he has business and technical expertise in helping customers migrate to and innovate on AWS. He loves thinking about new ideas and creating new products that bring value to customers on the cloud. In his spare time, he is an avid reader of world history and an amateur violin player.