AWS News Blog
New for Amazon Redshift – Data Lake Export and Federated Query

|
A data warehouse is a database optimized to analyze relational data coming from transactional systems and line of business applications. Amazon Redshift is a fast, fully managed data warehouse that makes it simple and cost-effective to analyze data using standard SQL and existing Business Intelligence (BI) tools.
To get information from unstructured data that would not fit in a data warehouse, you can build a data lake. A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. With a data lake built on Amazon Simple Storage Service (Amazon S3), you can easily run big data analytics and use machine learning to gain insights from your semi-structured (such as JSON, XML) and unstructured datasets.
Today, we are launching two new features to help you improve the way you manage your data warehouse and integrate with a data lake:
- Data Lake Export to unload data from a Redshift cluster to S3 in Apache Parquet format, an efficient open columnar storage format optimized for analytics.
- Federated Query to be able, from a Redshift cluster, to query across data stored in the cluster, in your S3 data lake, and in one or more Amazon Relational Database Service (Amazon RDS) for PostgreSQL and Amazon Aurora PostgreSQL databases.
This architectural diagram gives a quick summary of how these features work and how they can be used together with other AWS services.
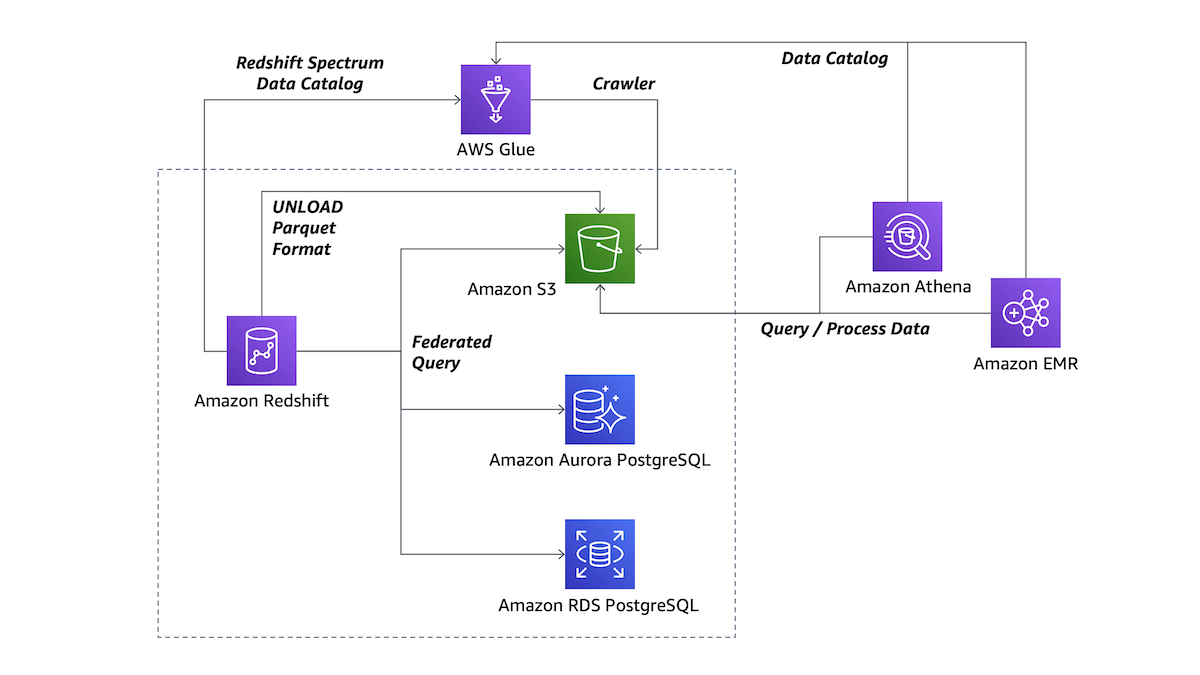
Let’s explain the interactions you see in the diagram better, starting from how you can use these features, and the advantages they provide.
Using Redshift Data Lake Export
You can now unload the result of a Redshift query to your S3 data lake in Apache Parquet format. The Parquet format is up to 2x faster to unload and consumes up to 6x less storage in S3, compared to text formats. This enables you to save data transformation and enrichment you have done in Redshift into your S3 data lake in an open format.
You can then analyze the data in your data lake with Redshift Spectrum, a feature of Redshift that allows you to query data directly from files on S3. Or you can use different tools such as Amazon Athena, Amazon EMR, or Amazon SageMaker.
To try this new feature, I create a new cluster from the Redshift console, and follow this tutorial to load sample data that keeps track of sales of musical events across different venues. I want to correlate this data with social media comments on the events stored in my data lake. To understand their relevance, each event should have a way of comparing its relative sales to other events.
Let’s build a query in Redshift to export the data to S3. My data is stored across multiple tables. I need to create a query that gives me a single view of what is going on with sales. I want to join the content of the sales and date tables, adding information on the gross sales for an event (total_price in the query), and the percentile in terms of all time gross sales compared to all events.
To export the result of the query to S3 in Parquet format, I use the following SQL command:
UNLOAD ('SELECT sales.*, date.*, total_price, percentile
FROM sales, date,
(SELECT eventid, total_price, ntile(1000) over(order by total_price desc) / 10.0 as percentile
FROM (SELECT eventid, sum(pricepaid) total_price
FROM sales
GROUP BY eventid)) as percentile_events
WHERE sales.dateid = date.dateid
AND percentile_events.eventid = sales.eventid')
TO 's3://MY-BUCKET/DataLake/Sales/'
FORMAT AS PARQUET
CREDENTIALS 'aws_iam_role=arn:aws:iam::123412341234:role/myRedshiftRole';To give Redshift write access to my S3 bucket, I am using an AWS Identity and Access Management (IAM) role. I can see the result of the UNLOAD command using the AWS Command Line Interface (AWS CLI). As expected, the output of the query is exported using the Parquet columnar data format:
$ aws s3 ls s3://MY-BUCKET/DataLake/Sales/
2019-11-25 14:26:56 1638550 0000_part_00.parquet
2019-11-25 14:26:56 1635489 0001_part_00.parquet
2019-11-25 14:26:56 1624418 0002_part_00.parquet
2019-11-25 14:26:56 1646179 0003_part_00.parquet
To optimize access to data, I can specify one or more partition columns so that unloaded data is automatically partitioned into folders in my S3 bucket. For example, I can unload sales data partitioned by year, month, and day. This enables my queries to take advantage of partition pruning and skip scanning irrelevant partitions, improving query performance and minimizing cost.
To use partitioning, I need to add to the previous SQL command the PARTITION BY option, followed by the columns I want to use to partition the data in different directories. In my case, I want to partition the output based on the year and the calendar date (caldate in the query) of the sales.
UNLOAD ('SELECT sales.*, date.*, total_price, percentile
FROM sales, date,
(SELECT eventid, total_price, ntile(1000) over(order by total_price desc) / 10.0 as percentile
FROM (SELECT eventid, sum(pricepaid) total_price
FROM sales
GROUP BY eventid)) as percentile_events
WHERE sales.dateid = date.dateid
AND percentile_events.eventid = sales.eventid')
TO 's3://MY-BUCKET/DataLake/SalesPartitioned/'
FORMAT AS PARQUET
PARTITION BY (year, caldate)
CREDENTIALS 'aws_iam_role=arn:aws:iam::123412341234:role/myRedshiftRole';
This time, the output of the query is stored in multiple partitions. For example, here’s the content of a folder for a specific year and date:
$ aws s3 ls s3://MY-BUCKET/DataLake/SalesPartitioned/year=2008/caldate=2008-07-20/
2019-11-25 14:36:17 11940 0000_part_00.parquet
2019-11-25 14:36:17 11052 0001_part_00.parquet
2019-11-25 14:36:17 11138 0002_part_00.parquet
2019-11-25 14:36:18 12582 0003_part_00.parquet
Optionally, I can use AWS Glue to set up a Crawler that (on demand or on a schedule) looks for data in my S3 bucket to update the Glue Data Catalog. When the Data Catalog is updated, I can easily query the data using Redshift Spectrum, Athena, or EMR.
The sales data is now ready to be processed together with the unstructured and semi-structured (JSON, XML, Parquet) data in my data lake. For example, I can now use Apache Spark with EMR, or any Sagemaker built-in algorithm to access the data and get new insights.
Using Redshift Federated Query
You can now also access data in RDS and Aurora PostgreSQL stores directly from your Redshift data warehouse. In this way, you can access data as soon as it is available. Straight from Redshift, you can now perform queries processing data in your data warehouse, transactional databases, and data lake, without requiring ETL jobs to transfer data to the data warehouse.
Redshift leverages its advanced optimization capabilities to push down and distribute a significant portion of the computation directly into the transactional databases, minimizing the amount of data moving over the network.
Using this syntax, you can add an external schema from an RDS or Aurora PostgreSQL database to a Redshift cluster:
CREATE EXTERNAL SCHEMA IF NOT EXISTS online_system
FROM POSTGRES
DATABASE 'online_sales_db' SCHEMA 'online_system'
URI ‘my-hostname' port 5432
IAM_ROLE 'iam-role-arn'
SECRET_ARN 'ssm-secret-arn';Schema and port are optional here. Schema will default to public if left unspecified and default port for PostgreSQL databases is 5432. Redshift is using AWS Secrets Manager to manage the credentials to connect to the external databases.
With this command, all tables in the external schema are available and can be used by Redshift for any complex SQL query processing data in the cluster or, using Redshift Spectrum, in your S3 data lake.
Coming back to the sales data example I used before, I can now correlate the trends of my historical data of musical events with real-time sales. In this way, I can understand if an event is performing as expected or not, and calibrate my marketing activities without delays.
For example, after I define the online commerce database as the online_system external schema in my Redshift cluster, I can compare previous sales with what is in the online commerce system with this simple query:
SELECT eventid,
sum(pricepaid) total_price,
sum(online_pricepaid) online_total_price
FROM sales, online_system.current_sales
GROUP BY eventid
WHERE eventid = online_eventid;Redshift doesn’t import database or schema catalog in its entirety. When a query is run, it localizes the metadata for the Aurora and RDS tables (and views) that are part of the query. This localized metadata is then used for query compilation and plan generation.
Available Now
Amazon Redshift data lake export is a new tool to improve your data processing pipeline and is supported with Redshift release version 1.0.10480 or later. Refer to the AWS Region Table for Redshift availability, and check the version of your clusters.
The new federation capability in Amazon Redshift is released as a public preview and allows you to bring together data stored in Redshift, S3, and one or more RDS and Aurora PostgreSQL databases. When creating a cluster in the Amazon Redshift management console, you can pick three tracks for maintenance: Current, Trailing, or Preview. Within the Preview track, preview_features should be chosen to participate to the Federated Query public preview. For example:

These features simplify data processing and analytics, giving you more tools to react quickly, and a single point of view for your data. Let me know what you are going to use them for!
— Danilo