Amazon Web Services ブログ
Category: Artificial Intelligence

コパイロットからコワーカーへ – AAAI : エージェント研究と実用化のギャップ
AAAI 2026 のパネルディスカッションで、Microsoft、Mistral、シンガポール国立大学、LinkedIn、AWS の研究者と実務者が、コーディングエージェントを本番環境に投入する際の現実的な課題について議論しました。研究は能力の最適化に注力する一方、本番環境では信頼性、コスト、レイテンシー、信頼、組織への適合性を同時に最適化する必要があり、そのギャップはアーキテクチャ設計、スケーラブルな強化学習環境の構築、評価ベンチマークの現実との乖離、そして人間とエージェント間の信頼構築という複数のレベルで現れます。パネルの結論は、AI エージェントの成功にはモデルの性能向上だけでなく、監査可能性や説明可能性を備えた信頼の仕組みづくりが不可欠であり、人間の役割はコードを書くことから、判断し、委任し、曖昧さを解消することへと移行しているというものでした。

Kiro スタートアップクレジットプログラムが復活します
起業家の皆さん、12 月のスタートアップクレジットにたくさんのご応募をいただきありがとうございました。昨年 Kiro スタートアップクレジットプログラムを開始した際、その反応は予想を大きく上回るものでした。数千もの応募が寄せられ、ニーズは明確でした。アーリーステージのチームには、成長に合わせてスケールする開発者ツールが必要だということです。
そこで、このプログラムを復活させます。本日より、対象となるスタートアップは最大 1 年分の Kiro Pro+ を無料で申請できます。仕様駆動開発と高度な AI エージェントを活用して、コストを気にせず開発を加速できます。

Kiro に MiniMax M2.5 と GLM-5 が追加されました
Kiro に新たに MiniMax M2.5 と GLM-5 の 2 つのオープンウェイトモデルが追加されました。MiniMax M2.5 はクレジット乗数 0.25x の低コストモデルで、SWE-Bench Verified 80.2% を達成し、マルチステップ実装や長時間エージェントセッションに最適です。GLM-5 は 200K コンテキストウィンドウを持つ大規模 MoE モデルで、リポジトリ規模の複雑なアーキテクチャ変更や長期エージェントワークフローに強みを発揮します。両モデルは IDE と CLI から即座に利用可能です。

Kiro CLI の新しいデザイン
私たちはターミナルが大好きです。この記事を読んでいるあなたも、きっとそうでしょう。CLI には、スピード、集中力、そして直接性という独特の魅力があります。速く、反応が良く、即座に結果が返ってくる。Kiro CLI はすでに、エージェントとの直接チャット、計画の作成、複数ステップにわたる処理の実行といった機能を通じて、エージェント型コーディングの力をターミナル環境にもたらしています。そして、さらに良い体験を追求した結果、新しいデザインへの刷新が必要だという結論に至りました。
本日、Kiro CLI の刷新された UX をご紹介します。いつでも以前の体験に戻せる「実験的モード」として提供しますので、ぜひフィードバックをお聞かせください。Kiro CLI をインストールして、コマンドラインで kiro-cli –tui と入力するだけで試せます。

AWS DevOps Agent によるエージェンティック AI を活用した自律的インシデント対応
このブログは、AWS DevOps Agentを使った自律的なインシデント対応について解説します。従来のSREエンジニアは、障害発生時に複数のログやツールから情報を手動で収集し、原因を特定するのに数時間かかっていました。AWS DevOps Agentは、アプリケーショントポロジーの理解、クロスアカウント調査、継続的学習機能を備えた完全マネージド型のAI運用チームメンバーです。6つの主要機能(Context、Control、Convenience、Collaboration、Continuous Learning、Cost Effective)により、単純なLLMラッパーとは異なる本格的な運用支援を実現します。このブログを読むことで、AWS DevOps Agentがどのように運用の複雑性を軽減し、インシデント対応を自動化・高速化するかを理解できます。

Kiro のエンタープライズガバナンス: MCP サーバーとモデルを管理する
Kiro に 2 つの新しいエンタープライズガバナンス機能が追加されました。管理者が承認済み MCP サーバーを JSON 形式のレジストリでホワイトリスト管理できる「MCP サーバーレジストリ」と、組織内の開発者が利用できる AI モデルを制限できる「モデルガバナンス」です。MCP レジストリは起動時・24 時間ごとに同期され、未承認サーバーへの接続を防止します。モデルガバナンスはデータレジデンシー要件への対応にも有効で、実験的モデルを承認完了まで無効化できます。これらの機能は Kiro IDE 0.11.28 / CLI 1.23 以降のエンタープライズユーザー向けに提供されます。

AWS Weekly Roundup: AWS AI/ML Scholars プログラム、Agent Plugin for AWS Serverless など (2026 年 3 月 30 日)
2026 年 3 月 23 日週の出来事で私が最も心を躍らせたのは、AWS Agentic AI バイスプレジ […]

Amazon OpenSearch Service のエージェント AI でオブザーバビリティとトラブルシューティングを効率化
Amazon OpenSearch Service にエージェント AI 機能が追加されました。エージェントチャットボット、調査エージェント、エージェントメモリの 3 つの機能が連携し、インシデント発生時のアラートから根本原因の特定までを数分で実現します。仮説駆動型の分析で複数インデックスのデータを自動相関し、平均復旧時間 (MTTR) を短縮します。
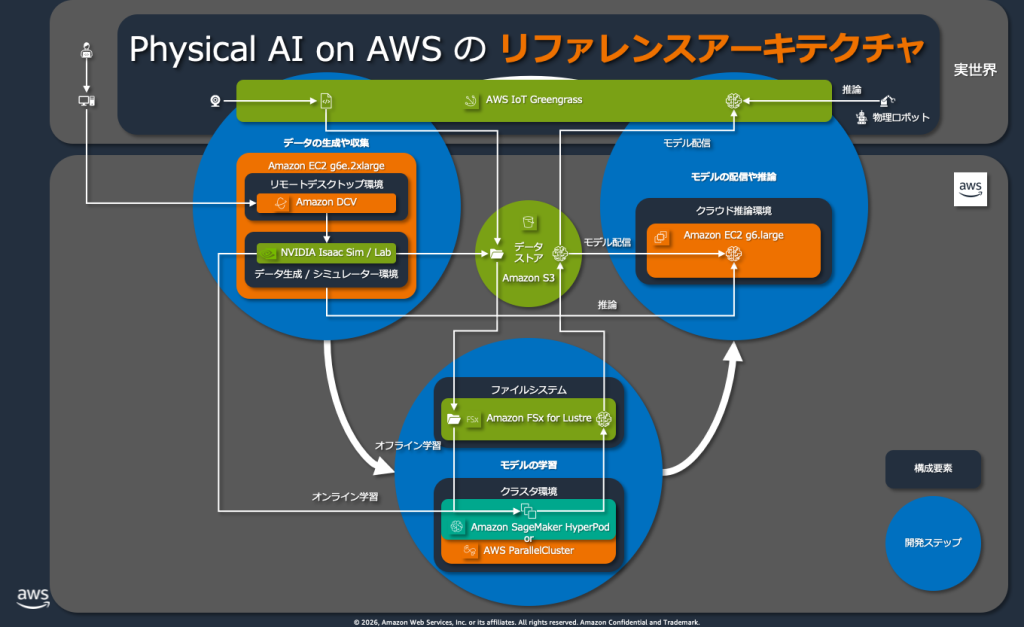
「Physical AI on AWS 勉強会 #1」を開催しました
2026 年 3 月 24 日、アマゾン ウェブ サービス ジャパン合同会社(以下、AWS ジャパン)は、「フ […]

大成株式会社様の AWS 生成 AI 活用事例「Amazon Bedrock と Amazon Q Developer で非エンジニアが実現する契約書管理 AI エージェントの構築」のご紹介
みなさん、こんにちは。AWS ソリューションアーキテクトの古屋です。 日々のお客様との会話の中で、「業務課題を […]