Amazon Web Services ブログ

新しい料金プランと新エージェント「Auto」の発表
Kiro は 9 月 30 日まで無料で利用でき、10 月 1 日以降は新しい料金体系に移行します。主な変更点として、vibe タスクと spec タスクの上限を統一した単一クレジットプール制、プロンプトの複雑さに応じた小数点単位でのクレジット消費、新規ユーザー向け 14 日間有効な 500 クレジットの無料トライアルを導入します。また、複数のモデルを組み合わせて最適な性能・効率・品質を提供する新しいエージェント「Auto」をデフォルトオプションとして追加し、Claude Sonnet 4 と比較してコスト削減を実現しながら同等の品質を維持します。料金プランは Free(50クレジット)から Power($200 /月)まで 4 段階で、すべての有料プランで超過利用時の従量課金($0.04/クレジット)に対応しています。

Amazon ECR の利用状況とセキュリティレポートを実装する
コンテナワークロードを管理する際、コンテナレジストリの一元的なオブザーバビリティを維持することはセキュリティと効率的なリソース利用のために不可欠です。Amazon Elastic Container Registry (ECR) は、イメージレベルとリポジトリレベルの両方でメトリクスを提供し、統合されたオブザーバビリティを構築する上で重要な役割を果たします。本記事では、これらのメトリクスをコスト内訳、利用状況メトリクス、セキュリティスキャン結果、および全リポジトリにわたるコンプライアンスステータスを含む、基本的で包括的なレポートに一元化する手順をご案内します。統合されたオブザーバビリティにより、利用パターンをより深く理解し、セキュリティリスクを特定し、セキュリティ要件と最適化のベストプラクティスに準拠させる必要があるリソースに優先順位を付けることが出来ます。

【開催報告】店舗業務にフォーカス!小売業界向け AI エージェント活⽤ワークショップ
2025年9月4日に開催された小売業界向けAIエージェント活用ワークショップの開催報告です。ファッション、アパレル、コンビニエンスストア等の小売企業15社が参加。生成AIの最新動向から、在庫管理・売上分析エージェントのハンズオン、そして店舗業務効率化のハッカソンまで実践的な内容を体験いただきました。ハッカソンでは6つの具体的なユースケース(売れ筋商品の補充発注、シフト変更調整、週報作成、店舗コンシェルジュ、商品ポップ作成、滞留在庫商品の広告作成)を特定し、画面プロトタイプの作成まで実施いただきました。
AWS は 2025 年 Gartner Magic Quadrant のクラウドネイティブアプリケーションプラットフォームとコンテナ管理の部門でリーダーに選出されました。
8 月、Amazon Web Services (AWS) は 2025年 Gartner Magic Qua […]

AWS Weekly Roundup: Strands Agents のダウンロード数 100 万回超え、Cloud Club Captain、AI Agent Hackathon など (2025 年 9 月 15 日)
9 月 8 日週、エージェンティック AI SDK の AWS オープンソースである Strands Agen […]

【開催報告】AWS GameDay for Telecom: Winning the DDoS Game
はじめに アマゾン ウェブ サービス ジャパン合同会社 ソリューションアーキテクトの黒田です。 通信業界の企業 […]
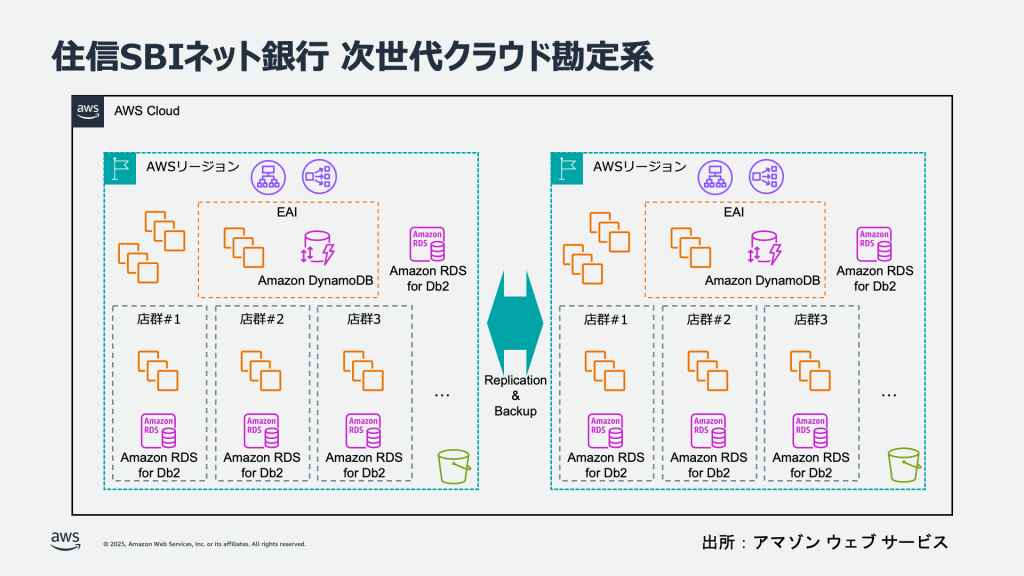
住信 SBI ネット銀行が勘定系システムのクラウド化に AWS を採用 – AWS を推奨クラウドプロバイダーに選定する同行の全ての主要システムが AWS で稼働
住信 SBI ネット銀行株式会社は、勘定系システムの更改に向けてアマゾン ウェブ サービス(以下、AWS)のクラウド環境を採用することを決定しました。2028 年初旬の本番稼働を目指し、AWS 上での次世代勘定系システムの設計・構築が進められており、移行完了後は、同行の主要システム全てが AWS 上で稼働することとなります。将来的なスケーラビリティを見据えた、デジタルバンク向けの次世代クラウド勘定系アーキテクチャーへの移行により、3,000 万口座を超える膨大なデータボリュームへの対応が可能となるほか、今後の事業拡大にも柔軟に対応できる設計が実現されます。
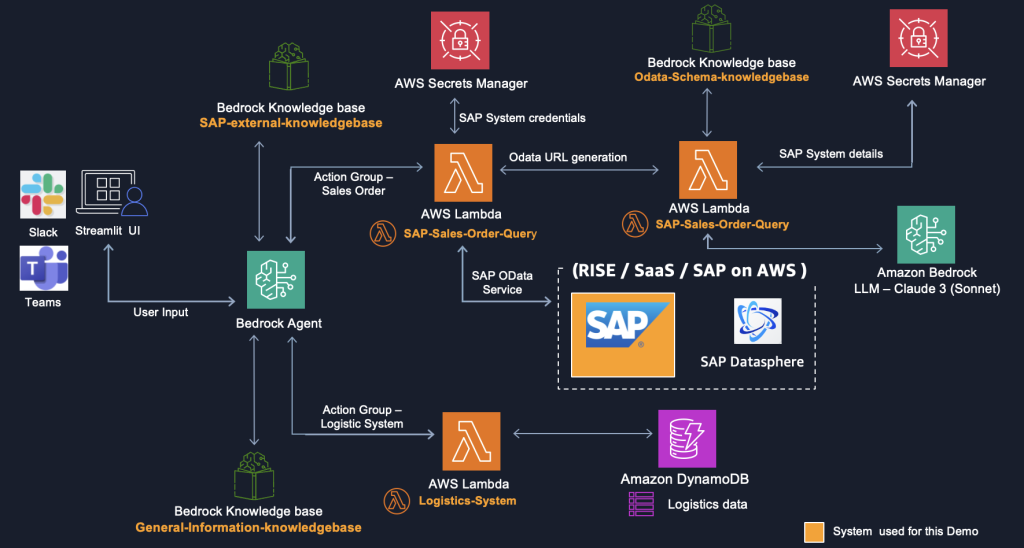
SAP 対応エージェンティック AI アシスタントを AWS の生成 AI サービスで実現
AWSとSAPは、最先端の生成AIサービス、堅牢なインフラストラクチャ、豊富な実装リソースの包括的なスイートにより、生成AI導入ジャーニーのあらゆる段階で顧客を支援します。これらの提供サービスはSAPシステムと統合でき、AWSとSAPの広大なクラウドサービスエコシステムを補完します。
このブログ(2部構成のシリーズのパート1)では、Amazon Bedrockおよびその他のAWSサービスを活用して、MS Teams、Slack、Streamlitユーザーインターフェースを通じて統一されたビューで自然言語を使用してSAPおよび非SAPデータソースから洞察を得る方法について説明し、実例を示します。
ロシアの APT29 による水飲み場型攻撃キャンペーンを Amazon が阻止
Amazon の脅威インテリジェンスチームが、ロシアの対外情報庁に関連する脅威アクター APT29 による水飲み場型キャンペーンを特定し阻止しました。この攻撃では侵害されたウェブサイトを通じて訪問者を悪意のあるインフラストラクチャにリダイレクトし、Microsoft のデバイスコード認証フローを悪用しようとしていました。攻撃者は正規サイトに難読化された JavaScript を注入し、訪問者の約 10% を Cloudflare を模した偽サイトにリダイレクトする手法を使用。Amazon は EC2 インスタンスの隔離や攻撃ドメインのブロックなどの対策を実施し、組織向けに多要素認証の有効化や不審なリダイレクトへの注意などの保護対策を推奨しています。

Amazon EC2 M4 インスタンスと M4 Pro Mac インスタンスの発表
2001 年から macOS を使用し、4 年前のリリースから Amazon EC2 Mac インスタンスを使 […]