Amazon Web Services ブログ

週刊AWS – 2026/3/16週
Amazon CloudWatch が組織全体での EC2 詳細モニタリング有効化を導入、Amazon Connect でオ外部メールアドレスにメール連絡先を転送可能、Amazon S3 Tables と Iceberg マテリアライズドビューの権限管理を簡素化、Amazon RDS の SQL Server Developer Edition 向け機能強化、Amazon Bedrock AgentCore Runtime でシェルコマンド実行がサポート開始、Amazon Redshift がダッシュボードと ETL ワークロードの新しいクエリのパフォーマンスを最大 7 倍向上、Amazon RDS Custom for SQL Server にOSアップデートの表示とスケジュール機能を追加

Amazon MSK Express ブローカーで Kafka 運用をシンプルにする
本記事では、Amazon MSK Express ブローカーが Kafka クラスターの運用をどのようにシンプルにするかを紹介します。サイジング、ストレージ管理、コンピューティングのスケーリング、モニタリング、アクセス制御、高可用性について、Express ブローカーがもたらす改善を解説します。

週刊生成AI with AWS – 2026/3/16 週
週刊生成AI with AWS, AgentCore の機能拡充が目立つ2026年3月16日号 – Amazon Bedrock AgentCore によるネットワーク運用エージェント構築のブログ記事を紹介。サービスアップデートでは AgentCore Runtime の AG-UI プロトコル・シェルコマンド実行・WebRTC サポートや、Minimax M2.5・GLM 5・Nemotron 3 Super の新モデル追加、SageMaker HyperPod のアイドルリソース共有をはじめとする13件のアップデートを紹介。

AWS クラウドでの 20 年 — 時間がたつのはなんと早いのでしょう!
AWS は創立 20 周年を迎えました! 着実なイノベーションのペースで、AWS は 240 を超える包括的な […]

2026 年最初の AWS ヒーローが選ばれました!
2026 年 3 月 18 日、3 人の非常に優れた開発者コミュニティリーダーたちを AWS ヒーローとしてご […]

メインフレームアプリケーションのモダナイゼーションに関する包括的な視点と配置戦略
配置戦略は、メインフレームモダナイゼーションにおいて複数の移行パターンを組み合わせる包括的アプローチです。ビジネス目標とワークロード特性に基づき適切なパターンを選択し、アプリケーションを管理可能な部分に分解して段階的に移行します。個別プロジェクトではなく全体ロードマップとして捉えることで、移行加速、リスク軽減、目標達成を支援します。
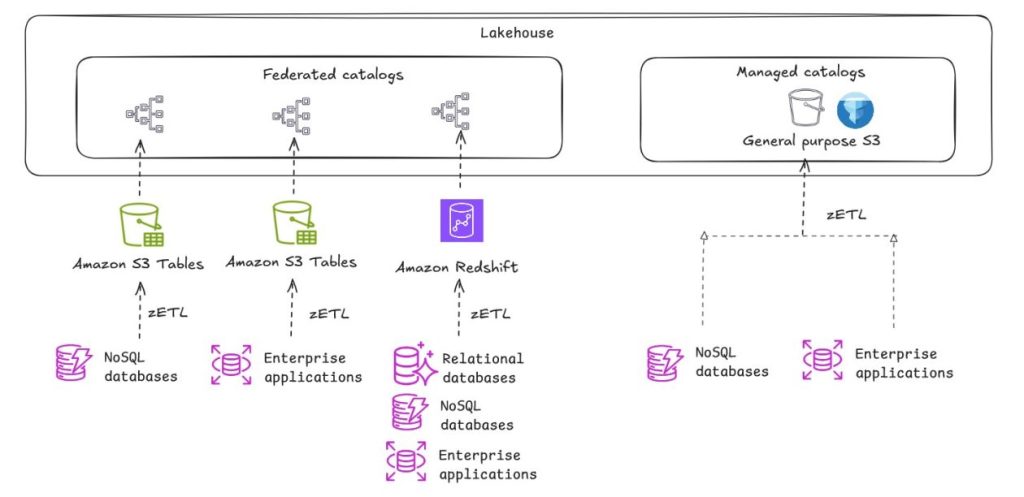
Amazon SageMaker を使用したレイクハウスのアーキテクチャ選択ガイド
Amazon SageMaker のレイクハウスアーキテクチャにおけるストレージパターンの選択ガイドです。データレイク (汎用 S3、S3 Tables) とデータウェアハウス (Redshift Managed Storage) の特性を比較し、ETL、Zero-ETL、データフェデレーションなどのデータ取り込みパターンとともに、ユースケースに応じた最適なアーキテクチャの選択方法を解説します。
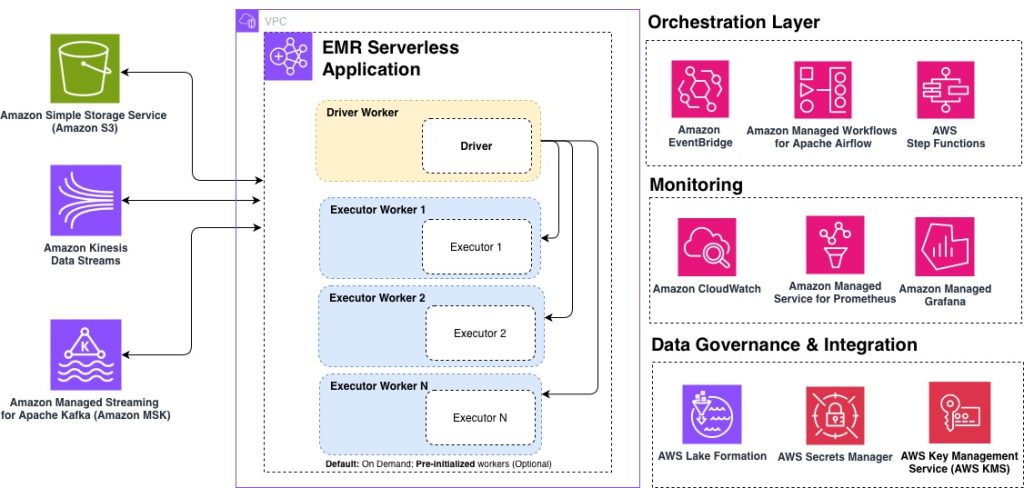
Amazon EMR Serverless のベストプラクティス 10 選
Amazon EMR Serverless のパフォーマンス、コスト、スケーラビリティを最適化するためのベストプラクティス 10 選を紹介します。アプリケーション設計、ワーカーの適正化、Graviton プロセッサの活用、ストレージ選択、マルチ AZ 構成など、効率的なデータ処理パイプラインの構築に役立つ実践的な推奨事項をまとめています。

AWS Load Balancer Controller が Kubernetes Gateway API サポートの一般提供を開始
AWS は最近、Amazon Web Services (AWS) Load Balancer Controller による Kubernetes Gateway API サポートの一般提供を発表しました。これまで、AWS Load Balancer Controller は Kubernetes Ingress と Service リソースの要件を満たすため、それぞれ Application Load Balancer (ALB) と Network Load Balancer (NLB) をプロビジョニングしていました。この新機能により、標準の Kubernetes Gateway API を使用してAWSロードバランシング機能を定義できるようになりました。

Oracle Database@AWS におけるレジリエンシーのための Well-Architected 設計
本記事は 2026/2/24に投稿された Well-Architected design for resili […]