Category: Amazon Aurora
Oracle 데이터베이스를 Amazon Aurora로 마이그레이션 하기
AWS Schema Conversion Tool(AWS SCT) 및 AWS Database Migration Service(AWS DMS) 를 사용하여 상용 데이터베이스를 Amazon Aurora로 마이그레이션하는 작업을 간소화하는 방법에 대한 개요를 제공합니다. 특히, Oracle 에서 MySQL과 호환되는 Amazon Aurora 로의 마이그레이션에 중점을 둡니다.
원문은 AWS Database Blog의 How to Migrate Your Oracle Database to Amazon Aurora 입니다.
데이터베이스 엔진 변경은 매우 어려울 수 있습니다. 그러나 Amazon Aurora와 같이 확장성이 뛰어나고 비용 효율적이며 완벽하게 관리되는 서비스의 많은 장점으로 인해 그 도전은 가치가 있습니다. 프로세스를 단순화 할 수 있는 도구가 있는 경우 특히 그렇습니다. 특정 엔진에서 다른 엔진으로 데이트베이스를 마이그레이션 할 때, 고려해야 할 사항이 두 가지 있습니다. 스키마와 코드 개체의 변환, 그리고 데이터 자체의 마이그레이션과 변환 등입니다. 다행히 AWS 는 데이터베이스의 변환 및 마이그레이션을 용이하게 하는 도구를 제공합니다.
AWS Schema Conversion Tool 은 원본 데이터베이스 스키마와 대다수의 사용자 정의 코드를 대상 데이터베이스와 호환되는 형식으로 자동 변환해 줌으로써 이기종 데이터베이스 마이그레이션을 단순화 합니다. 이 도구에서 변환하는 사용자 지정 코드에는 뷰(views), 저장 프로시저(stored procedures) 및 함수(functions)가 포함됩니다. 도구에서 자동으로 변환할 수 없는 코드는 사용자가 직접 변환할 수 있도록 명확하게 표시됩니다. AWS Database Migration Service는 다운타임을 최소화하면서 쉽고 안전하게 데이터를 마이그레이션 할 수 있도록 지원합니다.
좋습니다! 그럼 어디서 부터 시작해야 할까요?
AWS SCT로 작업하기
일반적으로, 모든 마이그레이션의 첫 번째 단계는 실행 가능성과 그에 따른 노력을 평가하는 것입니다. AWS SCT를 사용하여 오라클 데이터베이스를 Aurora로 변환하는데 필요한 개괄적인 노력을 평가해 볼 수 있습니다. AWS SCT는 여러 운영체제에서 실행할 수 있습니다. 이 글의 목적을 위해 Windows 에서 이 도구를 실행해 보도록 하겠습니다. AWS SCT를 다운로드 하려면 AWS Schema Conversion Tool 문서의 설치 및 업데이트를 참조하십시오. AWS SCT에 대한 전체 설명서를 보려면, AWS Schema Conversion Tool 이란 무엇인가? 를 확인하십시오.
이 글은 AWS SCT의 설치 및 구성을 다루지는 않지만, SCT를 원본 및 대상 데이터베이스에 연결하기 위해 Oracle 및 MySQL용 드라이버를 설치하는 것이 중요합니다. 원본 데이터베이스인 Oracle에 연결 한 후, 주어진 스키마를 마우스 오른쪽 단추로 클릭하고 평가 보고서를 생성할 수 있습니다. 이 평가 보고서는 Oracle 에서 Aurora로 변환할 수 있는 스키마의 양과 변환 후 남은 수동 작업을 매우 높은 수준에서 알려줍니다. 다음은 평가 보고서의 예제입니다.

평가 보고서 외에도, SCT는 각 객체가 정확히 어떻게 변환되는지 알려줍니다. 객체를 변환할 수 없는 경우, SCT는 그 이유를 알려주고 상황을 해결할 수 있는 방법에 대한 힌트를 제공합니다.

스키마의 100%가 Oracle 에서 Aurora로 변환되지 않는 경우에는 다음가 같이 몇가지 방법으로 문제를 해결할 수 있습니다.
- SCT가 Aurora로 변환할 수 있도록 원본 Oracle 데이터베이스의 개체를 수정합니다.
- 스키마를 그대로 변환하고 Aurora 데이터베이스에 적용하기 전에 SCT가 생성한 스크립트를 수정하십시오.
- 변환할 수 없는 객체를 무시하고 대상 데이터베이스에서 수정하십시오. 예를 들어, Oracle 에서dbms_random 패키지를 호출하는 함수가 있다고 가정하십시오. 이 패키지는 Aurora에는 존재하지 않습니다. 이 문제를 해결하려면 다음을 수행하십시오.
- 랜덤 값 생성을 애플리케이션 코드로 푸시하고 매개변수로 함수에 전달하십시오. 변환 전에 원본 데이터베이스에서 또는 변환 후에 대상 데이터베이스에 이 수정작업을 하도록 선택할 수 있습니다.
- SCT가 생성한 코드를 수정하여 MySQL 에서 사용할 수 있는RAND()함수를 사용하고 Aurora 데이터베이스에 새 코드를 적용합니다.
다른 예로, Oracle 에서 시퀀스를 사용하여 일부 고유 식별자를 채우는 경우를 가정해 보십시오. Aurora는 시퀀스를 지원하지 않으므로 이것을 해결하기 위해서 다음과 같이 할 수 있습니다.
- Aurora의 자동 증가(auto-increment) 기능을 사용하여 고유한 식별자를 자동으로 채웁니다. 이 방법을 사용하는 경우 Aurora 데이터베이스에서 스키마를 작성한 후 대상 테이블을 수정하는 스크립트를 작성해야 할 수 있습니다.
- 고유한 식별자(함수 또는 유사한 것을 사용)를 생성하는 대체 방법을 만들고 시퀀스에 대한 참조를 새 함수로 바꿉니다. 변환 전에 Oracle 소스에서 또는 변환 후에 Aurora 데이터베이스에서 이 작업을 수행할 수 있습니다.
- 두가지 방법을 모두 사용해야 할 수도 있습니다.
일반적으로 마이그레이션 작업의 일부로 SCT를 사용하는 경우 다음과 같은 작업을 함께 진행하는 것이 좋은 방법입니다.
- SCT 평가 보고서를 작성하고 그것을 사용하여 변환 작업의 부족한 부분을 채우기 위한 계획을 수립하십시오. 마이그레이션 후보 시스템이 여러 개인 경우 SCT 평가 보고서를 사용하여 먼저 진행해야 할 시스템을 결정하십시오.
- 작업 항목을 검토하고 변환에 실패한 각 항목에 대한 적절한 해결책을 결정하십시오.
- 이 프로세스를 반복하여 AWS Database Migration Service와 함께 사용하여 새로운 스키마에 데이터를 로드하고 새로운 Aurora 데이터베이스에 대해 애플리케이션을 테스트 할 수 있습니다.
AWS DMS로 넘어가 보겠습니다!
AWS DMS로 작업하기
AWS DMS를 사용하여 Oracle 원본 데이터베이스의 데이터를 새로운 대상인 Aurora 데이터베이스로 로드 할 수 있습니다. DMS의 가장 큰 장점은 대량 데이터를 로드 하는 것 외에도 진행중인 트랜잭션을 캡처하여 적용한다는 것입니다. Oracle 원본과 Aurora 대상 데이터베이스는 이전 할 때까지 동기화되어 유지됩니다. 이 방법을 사용하면 마이그레이션을 완료하는 데 필요한 중단 시간을 크게 줄일 수 있습니다. 모든 DMS 마이그레이션에는 다음 요소가 포함됩니다. 원본 엔드 포인트, Oracle; 대상 엔드 포인트, Aurora; 복제 서버; 및 작업.
Oracle 에서 Aurora로 마이그레이션 할 때 기존 데이터를 마이그레이션하고 진행중인 변경 사항을 복제하도록 작업 구성하기를 원할 겁니다. 이렇게 하면 대량 데이터를 마이그레이션하는 동안 DMS가 트랜잭션을 캡처하도록 합니다. 대량 데이터를 로드 한 후 DMS는 캡처 된 트랜잭션을 적용하기 시작하여 Oracle 및 Aurora 데이터베이스를 동기화 합니다. Aurora로 전환된 준비가 되면 애플리케이션을 중지하고, DMS가 마지막 트랜잭션을 적용하도록 하고, 새로운 Aurora 데이터베이스를 가리키는 애플리케이션을 시작합니다.
DMS를 사용하여 Oracle 에서 Aurora로 마이그레이션 할 때 고려해야 할 몇 가지 사항이 있습니다.
Supplemental logging. DMS가 원본 Oracle 에서 변경사항을 캡처하려면 보충 로깅(supplemental logging) 기능을 사용해야 합니다. 자세한 지침은 DMS 설명서 에서 찾을 수 있습니다.
DMS의 3단계. DMS는 데이터를 마이그레이션하고 진행중인 변경 사항을 복제할 때 세 단계를 거칩니다.
- Bulk load:마이그레이션의 대량 로드(Bulk load) 단계에서 DMS는 한 번에 n개의 테이블을 개별적으로 로드 합니다. 디폴트로는 n=8 입니다. 이 값은 DMS 관리 콘솔 또는 AWS CLI를 사용하여 설정할 수 있습니다.
- Application of cached transactions:대량 로드 단계에서 DMS는 원본 데이터베이스에 대한 변경 내용을 캡처합니다. 테이블에 대한 대량 로드가 완료되면 DMS는 대량 로드의 일부인 것처럼 최대한 빨리 캐시된 변경 내용을 해당 테이블에 적용합니다.
- Transactional apply:모든 테이블에 대해 대량 로드가 완료되면 DMS는 캡처 된 변경 사항을 단일 테이블 업데이트가 아닌 트랜잭션으로 적용하기 시작합니다.
보조 색인(Secondary indexes). 경우에 따라 성능상의 이유로 대량 로드 단계에서 보조 인덱스를 제거 할 수 있습니다. 대량 로드 단계에서 보조 색인 일부 또는 전체를 제거하도록 선택하면 트랜잭션 적용 단계에서 마이그레이션을 일시 중지하고 다시 추가해야 합니다. 모든 테이블에 대해 전체 로드가 완료된 후 마이그레이션을 안전하게 일시 중지할 수 있습니다.
외래 키(Foreign keys), 트리거(triggers), 등. 대량 로드는 테이블 단위로 수행되기 때문에 마이그레이션의 대량 로드 및 캐시 된 트랜잭션 단계에서 대상 Aurora 데이터베이스의 외래 키 조건이 위반될 수 있습니다. 대상 Aurora 엔드 포인트 정의의 추가 연결 속성으로 다음을 추가하여 외래 키 점검을 불가능 하게 할 수 있습니다. initstmt=SET FOREIGN_KEY_CHECKS=0. 일반적으로 데이터의 대량 로드로 인해 혼란을 겪거나 부정적인 영향을 받을 수 있는 사항을 처리하기 위한 전략을 수립해야 합니다. 예를 들어, 문제가 발생하지 않도록 하려면 트리거 설치를 마이그레이션의 컷 오버 단계까지 연기 할 수 있습니다.
데이터 유형. 새로운 데이터베이스 엔진으로 마이그레이션 할 때, 지원되는 데이터 유형과, 원본 데이터 유형이 어떻게 새로운 대상 데이터 유형으로 변환되는 지를 이해하는 것은 중요합니다. 이 경우에는, DMS 설명서에 있는 Oracle 원본 데이터 유형과 Aurora 대상 데이터 유형을 확인해야 합니다
성능: 마이그레이션의 전체 성능은 원본 Oracle 데이터베이스의 데이터 양, 유형 및 분산에 따라 달라질 수 있습니다. 데이터베이스 마이그레이션 서비스 모범 사례 백서에는 마이그레이션 성능을 최적화 할 수 있는 몇가지 권장 사항이 있습니다.
프로세스를 요약하면 다음과 같습니다.
- SCT 평가 보고서를 사용하여 현재 진행중인 작업의 개요를 확인하십시오. Aurora 로의 마이그레이션 후보가 여러 개인 경우 이 보고서를 통해 어떤 것을 먼저 마이그레이션 할지 결정할 수 있습니다.
- 처리 전후에 필요할 수 있는 마이그레이션 단계를 없애기 위해 대상 스키마를 생성하는 것을 연습하고 DMS를 사용하여 로드 하십시오.
- 대상 시스템에서 애플리케이션을 테스트하여 새로운 환경에서 예상한대로 동작하는지 확인하십시오. 로드, 네트워크 구성 등 프로덕션 환경과 유사한 구성에서 애플리케이션을 테스트 해보십시오.
- 스키마 생성, 데이터 로딩, 후 처리 단계 적용, 원본과 동기화 된 대상 시스템 가져 오기 및 필요한 모든 단계를 포함하여 실제 마이그레이션을 실습하십시오.
- SCT나 DMS 는 전체 시스템을 한번에 마이그레이션 할 것을 요구하지 않습니다. 이러한 도구를 사용하여 원하는 경우 시스템을 효율적으로 마이그레이션하고 재구성(rearchitect) 할 수 있습니다.
실제 마이그레이션을 시작하기 전에, SCT와 DMS 에 대한 문서를 자세하게 읽는 것이 좋습니다. 또한 단계별 연습 및 데이터베이스 마이그레이션 서비스 모범 사례 백서를 읽는 것이 좋습니다.
도구 사용에 대한 테스트를 위한 샘플 데이터베이스는 AWS Github 저장소에서 찾을 수 있습니다.
이 글은 여러분의 특정 상황에 필요한 모든 가능한 단계 또는 고려 사항을 설명하기 위한 것은 아니지만, SCT 및 DMS를 사용하여 상용 Oracle 데이터베이스의 구속을 어떻게 줄일 수 있는지에 대한 좋은 아이디어를 제공하기 위해 작성되었습니다. 마이그레이션에 행운과 행복이 가득하길!
더 자세한 것은 AWS Summit 2017 기술 세션 중 AWS DMS를 통한 오라클 DB 마이그레이션 방법 (발표 자료) 및 동영상도 참고하시기 바랍니다.
본 글은 아마존웹서비스 코리아의 솔루션즈 아키텍트가 국내 고객을 위해 전해 드리는 AWS 활용 기술 팁을 보내드리는 코너로서, 이번 글은 양승도 솔루션즈 아키텍트께서 번역해주셨습니다.

Amazon Aurora Storage 엔진 소개
Amazon Aurora는 re:Invent 2014에서 발표한 이후, 2015년 7월에 정식으로 출시 및 2016년 4월 1일 서울 리전에 출시함으로써 국내외 많은 고객들이 RDBMS가 필요한 워크로드에 이미 도입을 하였거나 현재 도입을 고려하고 있습니다. Amazon Aurora는 AWS 역사상 가장 빠른 성장세를 보이고 있는 서비스 입니다. Amazon Aurora의 빠른 성능과 안정성을 지원하는 핵심인 Aurora 스토리지 엔진에 대한 좋은 블로그 글을 소개합니다.
원문은 AWS Database Blog의 Introducing the Aurora Storage Engine (https://aws.amazon.com/blogs/database/introducing-the-aurora-storage-engine/)입니다.
Amazon Aurora 는?
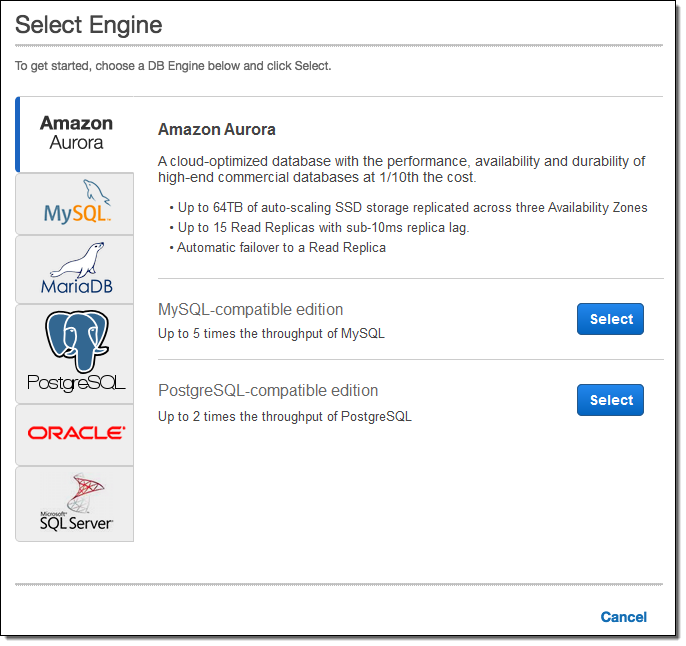
Amazon Aurora 는 고성능 상용 데이터베이스의 속도와 가용성에 오픈소스 데이터베이스의 간편성과 비용 효율성을 결합한 MySQL 호환 관계형 데이터베이스 서비스입니다. Amazon Aurora는 MySQL 보다 5배 뛰어난 성능과 상용 데이터베이스의 보안성, 가용성 및 안정성을 10분의 1의 비용으로 제공합니다. Aurora 에는 곧 출시 될 PostgreSQL 호환 에디션이 평가판으로 제공됩니다.
이 글에서 우리는 Aurora가 이러한 성능, 가용성 및 안정성을 제공할 수 있는 혁신적인 기술 중 하나인 스토리지 계층에 대해서 깊이 살펴볼 것입니다.
데이터베이스 스토리지의 진화
많은 고객들이 Direct Attached Storage(DAS)를 사용하여 데이터베이스 데이터를 저장합니다. 대기업 고객은 Storage Area Network(SAN)을 사용하기도 합니다. 이러한 접근 방식에는 다음과 같은 여러가지 문제가 있습니다:
- SAN은 비용이 많이 듭니다. 많은 수의 소규모 고개들은 SAN을 관리하는데 필요한 물리적인 SAN 인프라 또는 스토리지 전문성을 확보하기 힘듭니다.
- 디스크 스토리지는 성능을 위해 수평 확장이 복잡합니다. 효율적으로 운영하더라도, DAS와 SAN은 확장할 수 있는 한계가 여전히 존재합니다.
- DAS 및 SAN 인프라는 단일 물리적 데이터 센터에 존재합니다. 정전이나 네트워크 중단으로 단일 데이터 센터가 손상되면 데이터베이스 서버를 사용할 수 없습니다.
- 홍수, 지진 또는 기타 자연 재해로 인해 데이터 센터가 파괴되면 데이터가 손실 될 수 있습니다. 데이터 백업을 오프 사이트에 보관하면 새 위치에서 데이터베이스 서버를 다시 온라인 상태로 복구하는 데 몇 분에서 며칠 정도 걸릴 수 있습니다.
Amazon Aurora 스토리지 엔진 소개
Amazon Aurora는 클라우드를 활용하도록 설계되었습니다.
개념적으로 Amazon Aurora 스토리지 엔진은 한 리전(Region)의 여러 AWS 가용 영역(Availability Zone)에 걸친 분산된 SAN 입니다. AZ는 단일 또는 복수개의 물리적 데이터 센터로 구성된 논리적 데이터 센터입니다. 각 AZ는 해당 리전의 다른 AZ와의 신속한 통신을 가능하게 하는 낮은 대기시간 링크를 제외하고는 다른 AZ와 완벽히 격리됩니다. Amazon Aurora의 핵심인 분산형 저 지연 스토리지 엔진은 여러 AZ에 걸쳐서 구성됩니다.
스토리지 할당
Amazon Aurora는 보호 그룹(protection groups) 이라고 하는 10GB 논리 블록에 스토리지 볼륨을 구축합니다. 각 보호 그룹의 데이터는 6개의 스토리지 노드에 복제됩니다. 그런 다음 해당 스토리지 노드는 Amazon Aurora 클러스터가 운영되는 리전의 3개 AZ에 할당됩니다.
클러스터가 생성된 직후에는 스토리지가 거의 사용되지 않습니다. 데이터 양이 증가하여 현재 할당된 스토리지를 넘어서면 Aurora는 요건을 충족시키기 위해 볼륨을 자연스럽게 확장하고 필요에 따라 새로운 보호 그룹을 추가합니다. Amazon Aurora는 64TB라는 현재의 제한에 도달 할 때까지 이러한 방식으로 계속 확장합니다.

Amazon Aurora 가 쓰기를 처리하는 방법
Amazon Aurora에 데이터를 쓰면 6개의 스토리지 노드로 병렬로 전송됩니다. 이러한 스토리지 노드는 세 개의 AZ에 분산되어 있어 내구성과 가용성을 크게 향상시킵니다.
각 스토리지 노드에서 레코드는 먼저 인-메모리(in-memory) 큐에 들어갑니다. 이 큐의 로그 레코드는 중복 제거됩니다. 예를 들어, 마스트 노드가 스토리지 노드에 성공적으로 쓰고 난 후, 마스터 노드와 스토리지 노드 사이의 연결이 중단 된 경우 마스터 노드는 로그 레코드를 재전송 하지만 중복된 로그 레코드는 폐기됩니다. 보관할 레코드는 핫 로그(hot log)에서 디스크에 저장됩니다.
레코드가 지속 된 후, 로그 레코드는 업데이트 큐라는 인-메모리 구조에 기록됩니다. 업데이트 큐에서 로그 레코드는 먼저 병합 된 다음 데이터 페이지로 만들어 집니다. 하나 이상의 로그 시퀀스 번호(LSN)가 누락 된 것으로 판단되면 스토리지 노드는 볼륨의 다른 노드에서 누락 된 LSN을 검색하는 프로토콜을 사용합니다. 데이터 페이지가 갱신 된 후 로그 레코드가 백업되고 가비지 컬렉션으로 표시됩니다. 그리고 데이터 페이지는 비동기식으로 Amazon S3에 백업됩니다.
핫 로그에 기록되어 쓰기가 지속되면 스토리지 노드는 데이터 수신을 확인합니다. 6개 스토리지 노드 중 4개 이상이 수신 확인을 하면 쓰기 작업은 성공한 것으로 간주되고 답신은 클라이언트 애플리케이션에 반환됩니다.
Amazon Aurora가 다른 엔진보다 빠르게 쓸 수 있는 이유 중 하나는 스토리지 노드에만 로그 레코드를 보내고 이러한 쓰기 작업이 병렬로 수행된다는 것입니다. 실제로 MySQL과 비교할 때, Amazon Aurora는 데이터가 6개의 다른 노드에 쓰여지고 있지만 유사한 워크로드 대해 IOPS가 약 1/8 정도 필요합니다.
이 모든 작업의 단계는 비동기적으로 진행됩니다. 쓰기는 지연을 줄이고 처리량을 향상시키기 위해 그룹 커밋(Group Commit)을 사용하여 병렬로 수행됩니다.
쓰기 대기 시간이 짧고 입출력 풋프린트(footprint)가 줄어든 Amazon Aurora는 쓰기 집약적인 애플리케이션에 이상적입니다.
내결함성(Fault Tolerance)
다음 다이어그램은 3개의 AZ에 저장된 데이터를 보여줍니다. 복제 된 데이터는 99.999999999%의 내구성을 제공하도록 설계된 Amazon S3에 지속적으로 백업됩니다.

이 설계는 Amazon Aurora가 클라이언트 애플리케이션에 대한 가용성 영향 없이 전체 AZ 또는 2개의 스토리지 노드에 대한 손실을 견딜 수 있게 합니다.
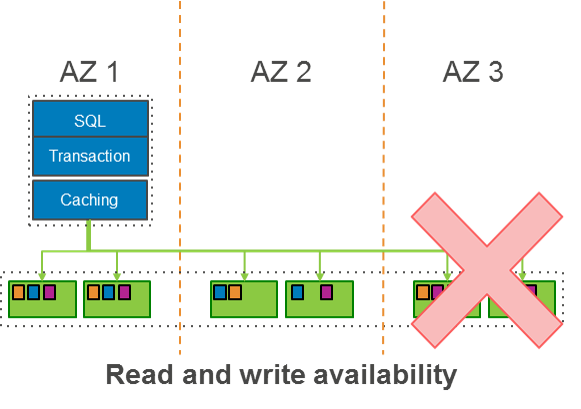
복구 과정에서 Aurora는 데이터 손실없이 보호 그룹에 있는 AZ와 또 다른 스토리지 노드의 손실에 견딜 수 있도록 설계되었습니다. 보호 그룹에 있는 4개의 스토리지 노드가 가용할 경우에만 Aurora 에서 쓰기가 지속되기 때문입니다. 쓰기를 수신 한 3개의 스토리지 노트가 다운 된 경우에도 Aurora는 4번째 스토리지 노드에서 쓰기를 계속 복구할 수 있습니다. 복구 중에 읽기 쿼럼(read quorum)을 유지하기 위해서, Aurora는 3개의 스토리지 노드가 동일한 LSN을 따라잡을 수 있도록 합니다. 그러나 쓰기 작업을 위해 볼륨을 액세스 하기 위해서, Aurora는 4개의 스토리지 노드가 복구 될 때까지 기다려야하므로 향후 쓰기를 위해 쓰기 쿼럼(write quorum)을 획득할 수 있습니다.

읽기의 경우, Aurora는 읽기를 수행하기 위해 가장 가까운 스토리지 노드를 찾습니다. 각 읽기 요청은 타임 스탬프, 즉 LSN과 관련됩니다. 스토리지 노드는 LSN까지 따라잡은 경우(즉, 해당 LSN까지 모든 업데이트를 수신 한 경우) 읽기를 수행 할 수 있습니다.
하나 이상의 스토리지 노드가 다운되었거나 다른 스토리지 노드와 통신 할 수 없는 경우 해당 노드는 가십 프로토콜(gossip protocol)을 사용하여 온라인 상태가 되면 다시 동기화 합니다. 스토리지 노드가 손실되고 새 노드가 자동으로 만들어지면 가십 프로토콜을 통해 동기화 됩니다
Amazon Aurora를 사용하면 컴퓨팅 및 스토리지가 분리됩니다. 이를 통해 읽기 복제본(read replica)은 복제본 자체의 데이터를 유지하지 않고도 스토리지 계층에 대한 컴퓨팅 인터페이스로 작동 할 수 있습니다. 이렇게 하면 모든 데이터를 동기화 할 필요없이 인스턴스가 온라인 상태가 되는 즉시 읽기 복제본에서 트래픽 처리를 시작할 수 있습니다. 마찬가지로 읽기 복제본의 손실은 기본 데이터에 영향을 미치지 않습니다. 그리고 읽기 복제본이 마스터 노드가 되더라도 데이터 손실이 없습니다. Amazon Aurora는 최대 15개의 읽기 복제본을 지원하고, 읽기 복제본에 내장된 로드 밸런싱 기능을 통해 고 가용성 및 읽기 집약적인 워크로드에 이상적입니다.
백업 및 복구
Amazon Aurora를 사용하면 최종 사용자의 성능에 영향을 미치지 않으면서 데이터가 실시간으로 S3로 계속 백업됩니다. 따라서 백업 윈도우와 자동화된 백업 스크립트가 필요하지 않습니다. 또한 사용자가 사용자 정의 백업 보유기간 중 어느 시점 으로든 복원할 수 있습니다. 이와 더불어, 여러 데이터 센터에 데이터를 복제하여 99.999999999%의 내구성을 제공하도록 설계된, 내구성이 뛰어난 저장소인 S3에 모든 백업이 저장되기 때문에 데이터 손실 위험이 크게 줄어 듭니다.
때때로 사용자는 특정 시점에서 Aurora 클러스터의 데이터 스냅샷을 만들고 싶어합니다. Amazon Aurora를 사용하면 성능에 아무런 영향을 미치지 않고서 이 작업을 수행 할 수 있습니다.
Amazon Aurora 백업에서 복원할 때 각 10GB 보호 그룹은 병렬로 복원됩니다. 또한 보호 그룹이 복원된 후에는 로그를 다시 적용할 필요가 없습니다. 즉, Amazon Aurora 는 보호 그룹이 복원되자 마자 최고 성능으로 동작할 수 있습니다.
보안
Amazon Aurora를 사용하면 업계 표준인 AES-256 암호화를 사용하여 모든 데이터를 암호화 할 수 있습니다. 사용자는 AWS 키 관리 서비스(AWS KMS)를 사용하여 키를 관리할 수 있습니다. Amazon Aurora 클러스터에 TLS 연결을 통해 데이터를 안전하게 전송할 수 있습니다. 이러한 기능 외에도 Amazon Aurora는SOC 1, SOC 2, SOC 3, ISO 27001/9001, ISO 27017/27018 및 PCI를 포함한 여러 인증/증명을 보유하고 있습니다.
결론
Amazon Aurora는 클라우드를 위해 설계되었습니다. Amazon Aurora는 여러 AZ에 데이터를 분산시킴으로써 매우 견고하고 가용성이 높은 데이터베이스 엔진을 제공합니다. 데이터가 저장되는 방법과 장소의 많은 혁신으로 인해 읽기 및 쓰기 처리량이 다른 관계형 데이터베이스 엔진보다 크게 향상되었습니다. 데이터베이스 복원 작업이 발생할 때의 속도도 마찬가지 입니다. 마지막으로 Amazon Aurora는 관리형 서비스이기 때문에 AWS가 백업, 패치 및 스토리지 관리 등의 차별성 없는 어려운 업무들(undifferentiated heavy lifting)을 처리해 드립니다.
지금 바로 Amazon Aurora 콘솔에서 시작하십시오 :
최신 기능 중 일부를 포함하여 Amazon Aurora에 대한 자세한 내용을 보려면 아래 강연 동영상을 참고하세요.
- AWS Summit Seoul 2016 – 관계형데이터베이스의 새로운 패러다임 : Amazon Aurora
- AWS CLOUD 2017 | Amazon Aurora를 통한 고성능 데이터베이스 운용하기
- AWS Summit 2017 Amazon Aurora 성능 향상 및 마이그레이션 모범 사례
본 글은 아마존웹서비스 코리아의 솔루션즈 아키텍트가 국내 고객을 위해 전해 드리는 AWS 활용 기술 팁을 보내드리는 코너로서, 이번 글은 양승도 솔루션즈 아키텍트께서 번역해주셨습니다.
Amazon Aurora PostgreSQL 버전 미리 보기(Preview) 공개
작년 re:Invent에서 Amazon Aurora PostgreSQL 호환 버전 계획을 발표하고, 미리보기 기능을 출시하였습니다.
많은 고객이 이에 대한 강한 피드백을 보내주셨으며, Amazon Aurora가 높은 가용성과 내구성을 제공할 것이며 AWS Cloud에서 PostgreSQL 9.6 응용 프로그램을 실행하기를 기대하고 있습니다.
미리보기 공개
오늘 우리는 모든 관심 있는 고객들에게 PostgreSQL 호환 Amazon Aurora의 미리 보기를 공개하고, 지금 신청받고 있습니다. 미국 동부 (버지니아 북부) 지역에서 사용해 보실 수 있고, 기존 환경 대비 PostgreSQL 성능이 2-3 배 향상됩니다. 또한 낮은 대기 시간의 읽기 복제본을 빠르고 쉽게 만들 수 있습니다.
Amazon RDS 성능 지표 참고
미리보기에는 새로운 Amazon RDS Performance Insights 도구가 포함되어 있습니다. 이 도구를 사용하여 각 쿼리를 볼 수 있는 기능을 포함하여 매우 상세한 수준에서 데이터베이스 성능을 이해할 수 있습니다. Performance Insight 대시 보드를 사용하여 데이터베이스로드를 시각화하고 SQL 문, 대기, 사용자 또는 호스트별로 필터링 할 수 있습니다.
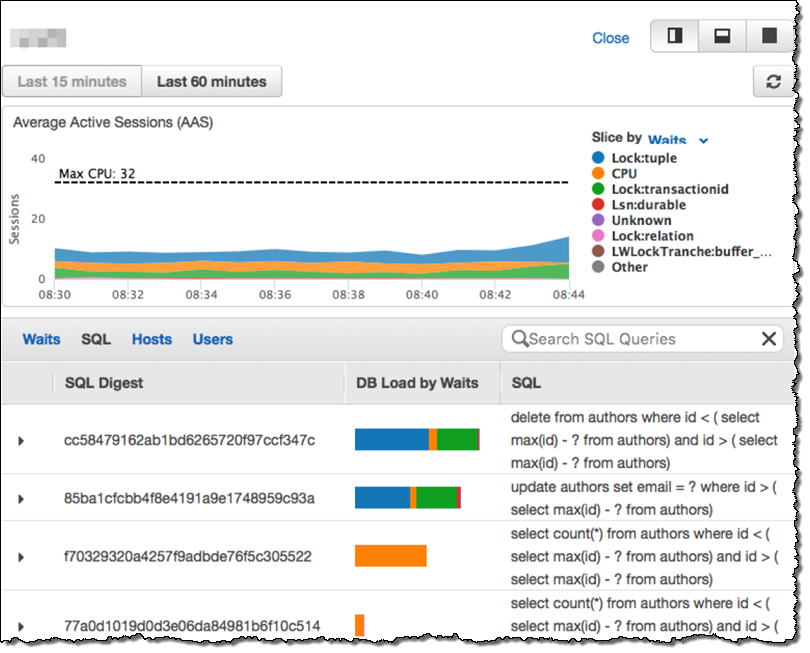
— Jeff;
Amazon Aurora 업데이트 – 리전간 및 계정간 기능 지원 및 T2.Small DB 추가 기능
오늘은 최근 Amazon Aurora 기능 업데이트를 모아서 보내드립니다. Aurora는 고성능 MySQL-호환(PostgreSQL-호환 예정) 엔터프라이즈 기반 데이터베이스 (Amazon Aurora 정식 출시 참고) 입니다.
Aurora의 최신 추가 사항은 다음과 같습니다.
- 리전간 스냅 샷 복사
- 리전간 암호화 된 데이터베이스 복제
- 계정간 암호화 된 스냅 샷 공유
- 미국 서부 (북부 캘리포니아) 리전 신규 추가
- T2.Small 인스턴스 지원
하나씩 잠깐 살펴 보겠습니다.
리전 간 스냅 샷 복사
이제 한 리전에서 다른리전으로 Amazon Aurora 스냅 샷 (자동 또는 수동)을 복사 할 수 있습니다. 스냅 샷을 선택하고 Snapshot Actions 메뉴에서 Copy Snapshot를 선택한 다음 영역을 선택하고 새 스냅 샷의 이름을 입력하시면 됩니다.
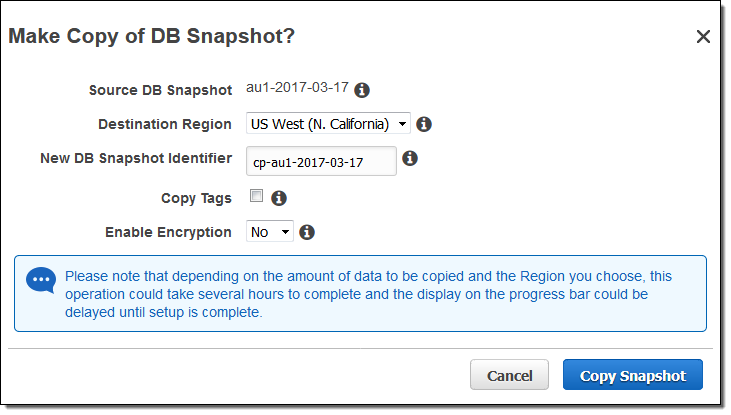
이 작업의 일부로 스냅 샷을 암호화하도록 선택할 수도 있습니다. 자세한 내용은 Copying a DB Snapshot or DB Cluster Snapshot를 참조하십시오.
리전 간 암호화 된 데이터베이스 복제
새로운 Amazon Aurora DB 인스턴스를 생성 할 때 암호화를 활성화 할 수 있습니다.
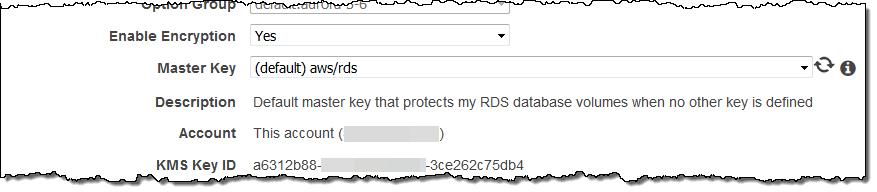
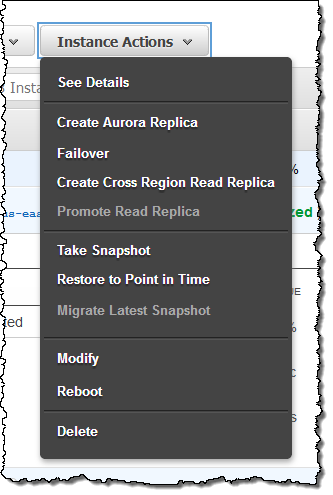
몇 번 클릭 만으로 다른 지역에 읽기 복제본을 만들 수 있습니다. 이 기능을 사용하여 멀티 리전간 기반 고 가용성 시스템을 구축하거나 데이터를 사용자에게 더 가깝게 데이터베이스를 이동시킬 수 있습니다. 리전간 읽기 복제본을 만들려면 기존 DB 인스턴스를 선택하고 메뉴에서 Create Cross Region Read Replica를 선택하십시오.
그런 다음 Network & Security 설정에서 대상 지역을 선택하고 Create를 클릭합니다.
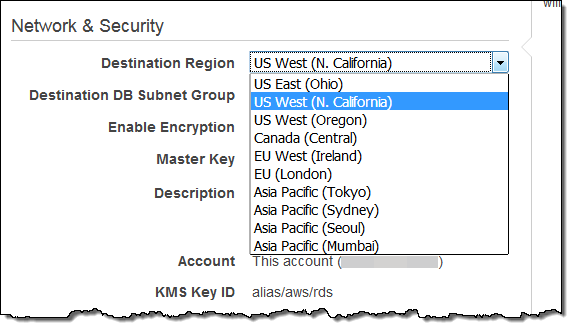
대상 리전에는 두 개 이상의 가용 영역(AZ)을 포함하는 DB 서브넷 그룹이 포함되어야합니다. 자세한 내용은 Replicating Amazon Aurora DB Clusters Across AWS Regions를 참고하시기 바랍니다.
계정간 암호화 된 스냅 샷 공유
Aurora DB 인스턴스를 생성 할 때 이미 주기적으로 자동화 된 스냅 샷을 구성 할 수 있습니다. 몇 번의 클릭만으로 원하는 시간에 스냅 샷을 만들 수도 있습니다.
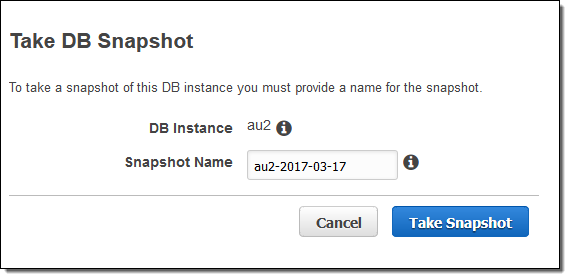
DB 인스턴스가 암호화되어 있어도 스냅샷을 만들 수 있습니다.
이제 암호화 된 스냅 샷을 다른 AWS 계정과 공유 할 수 있습니다. 이 기능을 사용하려면 DB 인스턴스 (스냅 샷)를 기본 RDS 키가 아닌 마스터 키로 암호화 해야 합니다. 스냅 샷을 선택하고 Snapshot Actions 메뉴에서 Share Snapshot를 선택하십시오.
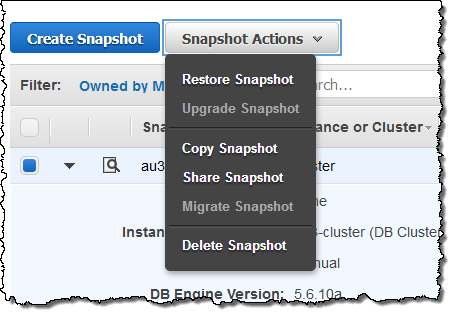
그런 다음 대상 AWS 계정 ID를 입력하고 각각을 클릭 한 다음 Add를 클릭 한 다음 Save을 클릭하여 스냅 샷을 공유하십시오.
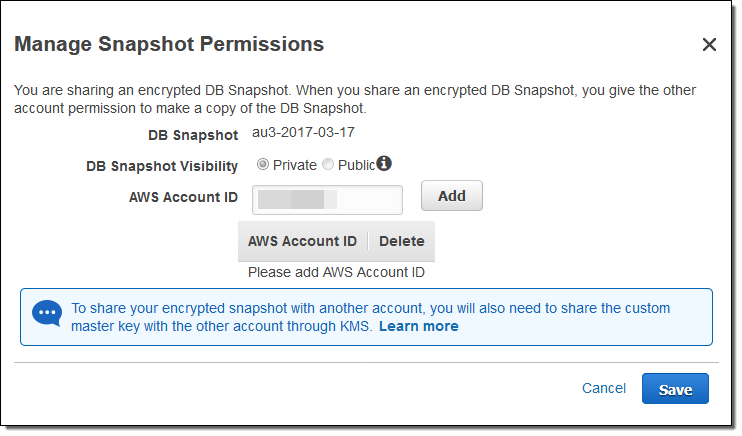
또한 스냅 샷을 암호화하는 데 사용 된 키를 공유해야 합니다. 이 기능에 대한 자세한 내용은 DSharing a DB Snapshot or DB Cluster Snapshot를 참조하십시오.
US West (Northern California Region) 리전 확장
이제 미국 서부 (북부 캘리포니아) 지역에서 Amazon Aurora DB 인스턴스를 시작할 수 있습니다. 리전별 가격은 Amazon Aurora Pricing 페이지를 참고하시기 바랍니다.
T2.Small 인스턴스 지원
이제 t2.small DB 인스턴스를 지원할 수 있습니다.
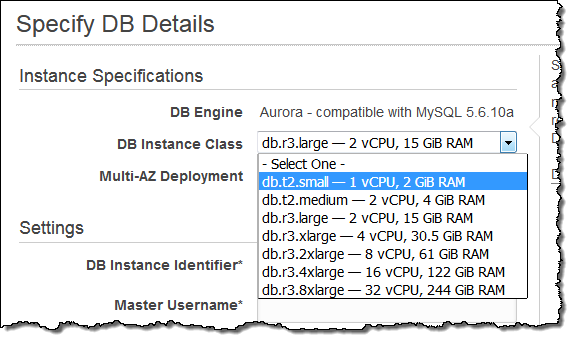
본 인스턴스 타입은 개발 및 테스트 환경과 가벼운 워크로드에 매우 적합합니다. 또한, 이를 사용하여 Amazon Aurora에 대한 기본 경험을 얻을 수 있습니다. 지난 11 월에 출시 한 t2.medium을 포함하여 6 개의 다른 인스턴스와 함께 Aurora를 사용할 수있는 모든 AWS 지역에서 사용할 수 있습니다.
t2.small DB 인스턴스의 주문형 가격은 미국 동부 (버지니아 북부) 지역에서 시간당 $ 0.041에서 시작되며 3 년 기간의 All Upfront Reserved 인스턴스의 경우 시간당 0.018 달러입니다. (자세한 내용은 Amazon Aurora Pricing 참조)
— Jeff;
이 글은 Amazon Aurora Update – More Cross Region & Cross Account Support, T2.Small DB Instances, Another Region의 한국어 버전입니다.
Amazon RDS MySQL로 부터 Aurora 읽기 복제본 생성 기능 출시!
24시간 실행하는 웹 사이트 또는 애플리케이션인 경우, 기존 데이터베이스 엔진에서 다른 엔진으로 마이그레이션은 매우 까다로운 작업입니다. 데이터베이스를 중단하고 작업을 할 수 없다면, 일반적으로 복제를 기반으로 하는 접근 방식이 가장 좋습니다.
오늘 Amazon Aurora 읽기 복제본(Read Replica)을 통해 MySQL 용 Amazon RDS DB 인스턴스에서 Amazon Aurora로 마이그레이션 할 수 있는 새로운 기능을 출시했습니다. 마이그레이션 프로세스는 기존 DB 인스턴스의 DB 스냅 샷을 만든 다음, 이를 새로운 Aurora 읽기 복제본을 사용합니다. 복제본을 설정 한 후 복제를 사용하여 원본과 같은 최신 상태로 만들고, 복제 지체가 없어지면 복제를 완료합니다. 이 시점에서 오로라 읽기 복제본을 독립 실행 형 Aurora DB 클러스터로 만들고 클라이언트 응용 프로그램을 연결합니다.
마이그레이션은 테라 바이트 데이터 당 몇 시간이 걸리고, 최대 6 테라 바이트의 MySQL DB 인스턴스에서 작동합니다. InnoDB 테이블은 MyISAM 테이블보다 복제가 약간 더 빠르며 압축되지 않은 테이블도 가능합니다. 마이그레이션 속도가 중요한 요소라면 MyISAM 테이블을 InnoDB 테이블로 옮기고, 압축 테이블을 압축 해제하여 성능을 향상 시킬 수도 있습니다.
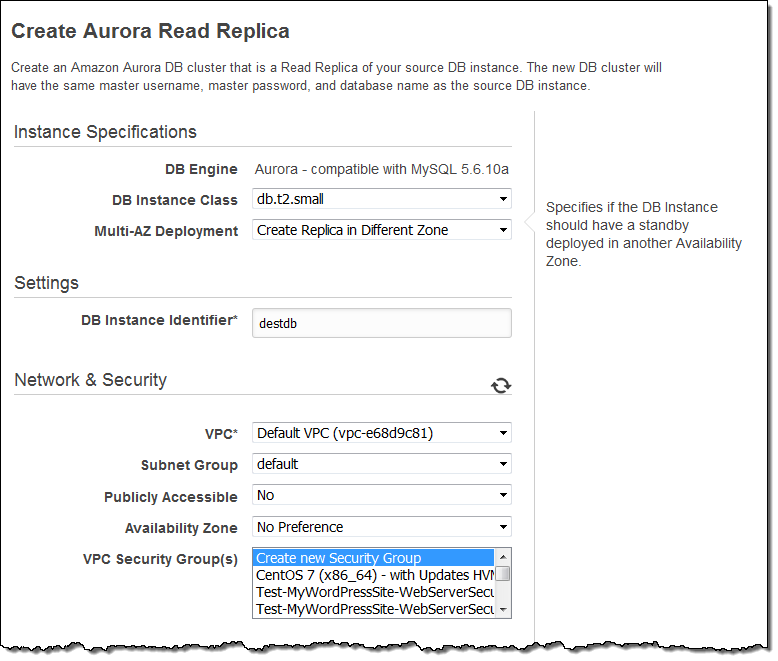
RDS DB 인스턴스를 마이그레이션하려면 AWS 관리 콘솔에서 Instance Actions를 선택하고 인스턴스 작업을 클릭 한 다음 Create Aurora Read Replica을 선택하십시오.
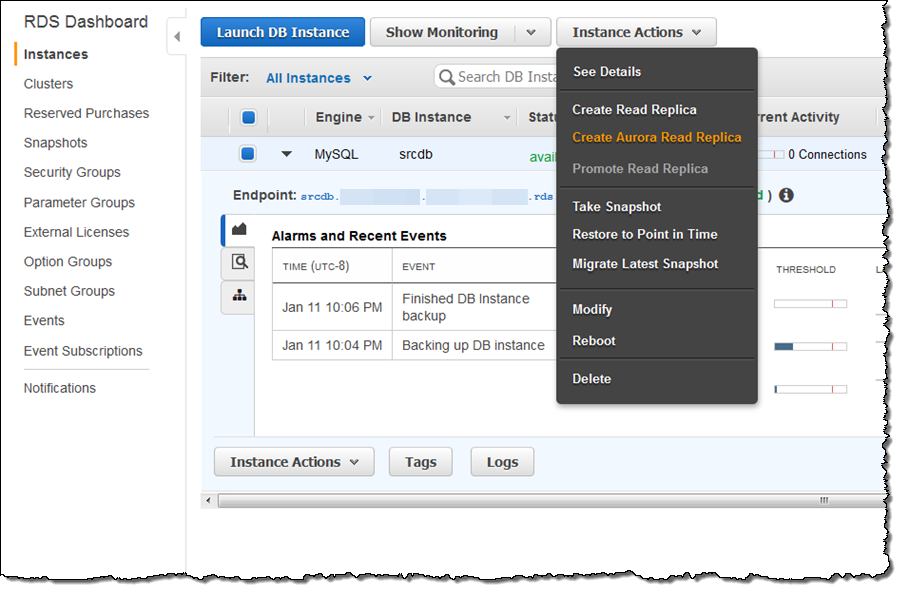
그런 다음 데이터베이스 인스턴스 식별자를 입력하고, 원하는 옵션을 설정 한 다음 Create Read Replica를 클릭합니다.
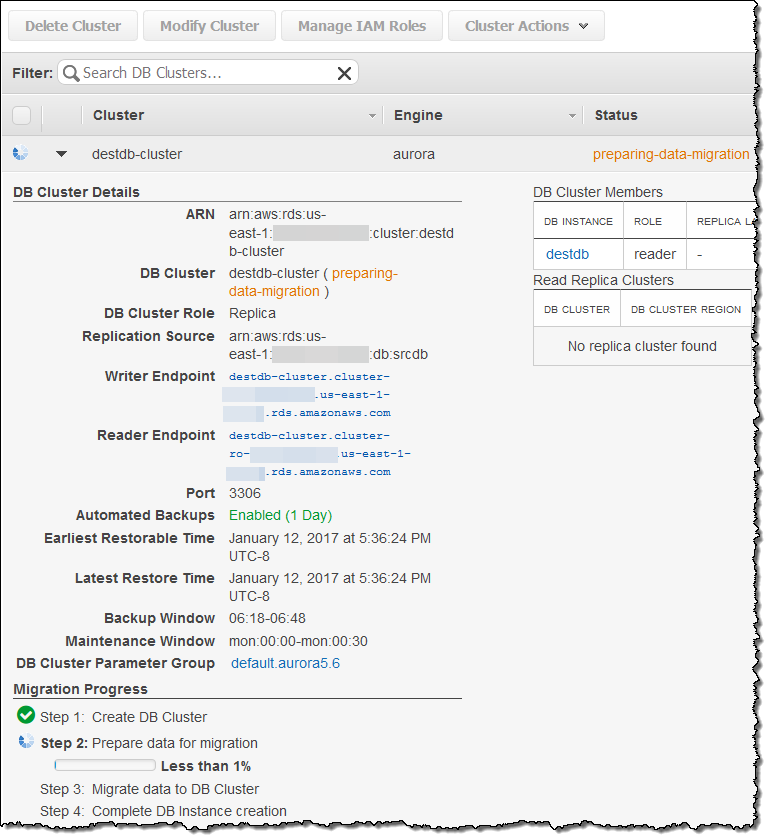
콘솔에서 마이그레이션 진행 상황을 모니터링 할 수 있습니다.
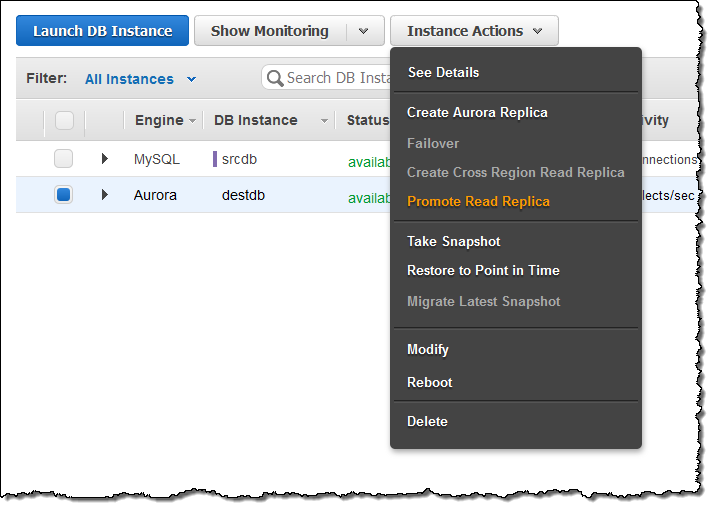
마이그레이션이 완료되면 새로운 Aurora 읽기 복제본에서 Replica Lag가 0이 될 때까지 기다렸다가 (복제본에서 SHOW SLAVE STATUS 명령을 사용하여 “Masters 뒤의 Seconds”를 확인) 복제본이 소스와 모두 동기화되면, 원본 MySQL DB 인스턴스에 대한 신규 트랜잭션을 중지하고 오로라 읽기 복제본을 DB 클러스터로 올립니다.
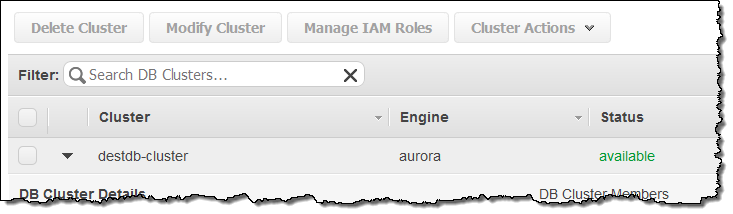
새 클러스터를 사용할 수 있을 때까지 기다립니다 (일반적으로 1 분 정도).
이제 응용 프로그램에 클러스터의 엔드포이트를 지정하면 됩니다!
본 기능은 오늘 부터 Amazon Aurora를 제공하는 모든 리전에서 사용 가능합니다.
— Jeff;
이 글은 New – Create an Amazon Aurora Read Replica from an RDS MySQL DB Instance의 한국어 번역입니다.
Amazon Aurora 업데이트 – 공간 인덱스와 제로 다운 타임 패치 기능 출시
AWS의 다양한 서비스 중 Amazon Aurora는 가장 빠르게 성장하고 있는 서비스입니다! 많은 고객은 빠른 속도, 성능 및 가용성에서 MySQL 호환 Aurora을 많이 이용 하시고 있으며, 향후 PostgreSQL 호환 Aurora역시 기대하시고 있습니다.
오늘 AWS re:Invent에서 새로 발표한 두 가지 기능인 공간 인덱스와 제로 다운 타임 패치 기능을 출시했습니다.
공간 인덱스
Amazon Aurora는 지금까지 공간 지점이나 면을 대표하는 GEOMETRY 형식을 사용할 수 있었습니다. 이러한 형식을 사용하여 열을 만들고, ST_Contains, ST_Crosses, ST_Distance (기타 다른 객체) 등의 기능을 공간 질의(spatial query)를 실행하는 데 사용하였습니다. 이들 질의 방식은 매우 강력하지만, 대용량 데이터 세트에 대해 조정하려면 미흡한 점이나 제한 사항이 있었습니다.
Aurora을 이용하여 대용량 위치 정보를 사용하는 응용 프로그램을 작성하기 위해 공간 데이터에 대해 매우 효율적인 인덱스를 사용하실 수 있게 되었습니다. Aurora는 dimensionally ordered space-filling curve (차원 정렬 공간 보충 곡선)을 이용하여, 빠른 확장성과 정확한 정보 검색을 수행할 수 있습니다. 인덱스는 b-tree를 사용하여, MySQL5.7에 비해 최대 2 배의 성능을 보입니다 (자세한 내용은 Amazon Aurora Deep Dive 및 발표 자료를 참고하세요.)
본 기능을 현재 이용하기 위해서는, Aurora Lab Mode를 사용하실 필요가 있습니다. 이 기능을 활성화 한 후 기존 테이블과 새로 생성하는 테이블에 spatial index를 설정하실 수 있습니다 (자세한 내용은 Amazon Aurora and Spatial Data를 참조하십시오).
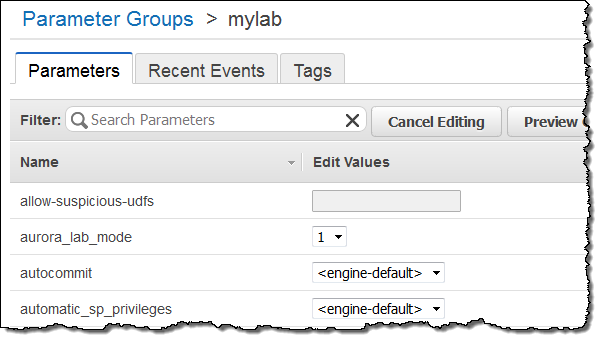
제로 다운 타임 패치
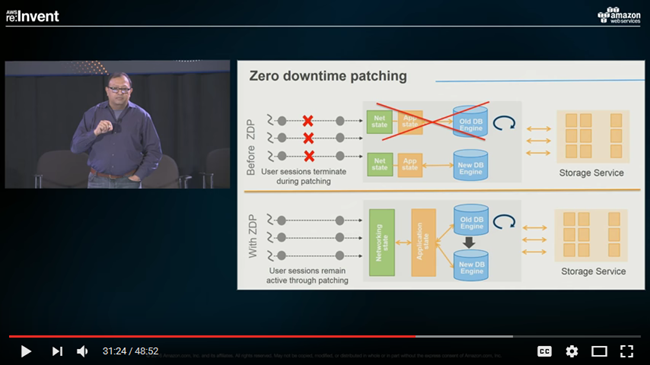
24시간 돌아가는 서비스에서 데이터베이스에 대한 패치와 업데이트를 위해 DB를 오프라인으로 돌릴 수 없고, 읽기 복제본(read replica)를 마스터로 임시로 변경하여 고가용성을 확보 한 후, 업데이트를 하는 방법을 이용해 왔습니다.
오늘 새로운 제로 다운 타임 패치 기능을 통해 Aurora 인스턴스 패치를 다운 타임이 없고, 고 가용성에 영향을 주지 않고 온라인으로 수행 할 수 있게 되었습니다. 이 기능은 현재 최신 버전 (1.10)가 적용된 Aurora 인스턴스에서 잘 작동합니다. 단일 노드 클러스터 및 다중 노드 클러스터 쓰기(Writer) 인스턴스 모두에서 작동하지만, 바이너리 로그가 활성화되어 있는 경우 비활성화됩니다.
이 패치 방식은 이미 열려있는 오픈 SSL(open SSL) 연결, 활성화 및 잠금 등의 트랜잭션 완료 및 임시 테이블 삭제 등을 기다립니다. 패치 적용 가능한 윈도우가 생긴 경우, 제로 다운 타임 패치를 적용합니다. 응용 프로그램 세션은 유지한 채, 패치가 적용되는 동안 데이터베이스 엔진이 재시작합니다. 순간 (5 초 정도) 처리량 저하가 발생합니다. 만약 제로 다운 타임 패치에서 적용 할 수 있는 윈도우가 없으면, 일반 패치 프로세스가 실행됩니다.
어떻게 동작하는지와 구현 방법에 대한 상세 정보는 Amazon Aurora Deep Dive video을 참조하십시오.
정식 출시
이 기능은 Amazon Aurora를 제공하는 모든 리전에서 오늘 부터 사용 가능합니다.
— Jeff;
이 글은 Amazon Aurora Update – Spatial Indexing and Zero-Downtime Patching의 한국어 번역입니다.
Amazon Aurora 업데이트 – PostgreSQL 호환 서비스 출시
2년전 Amazon Aurora 발표를 통해 RDS 팀에서 생각한 클라우드에서 관계형 데이터베이스의 모델을 설명한 신선한 아이디어를 제공한 바 있습니다.
이후 많은 고객으로 부터 정말 가슴 따뜻한 피드백을 받았습니다. MySQL 호환성을 유지하면서도, 고가용성 및 기본 암호화 기능에 대해 만족하고 있으며, Aurora를 통해 빠른 장애 복구와 10GB부터 64 TB까지 자체 스토리지 확장 등의 기능 등에 전적인 신뢰를 보여주셨습니다. Aurora는 6개의 복제본을 세 개의 가용 영역(AZ)에 분산 저장하여 가용성이나 성능 영향 없이 S3를 스토리지 공간으로 사용하고 있습니다. 확장이 필요할 때, 15개의 낮은 지연 속도의 읽기 복제본을 만들수도 있습니다. 더 자세한 사항은 Amazon Aurora 성능 평가 정보를 참고해 주시기 바랍니다.
고객들이 서비스에 대해 다양한 요구를 하고 있기 때문에 이에 대해 바르게 이해하고, 아래와 같이 고객의 피드백에 부합하는 기능을 계속해서 출시해 왔습니다.
- 11월 – 개발 및 테스트용 신규 T2.Medium DB 인스턴스 타입 추가
- 10월 – Lambda Function 호출 및 S3 데이터 읽기 지원
- 9월 – 신규 읽기 엔드 포인트 기능 (로드 밸런싱 및 고가용성 제공)
- 9월 – 병렬 미리 읽기, 고속 인덱싱 , NUMA 인식 등
- 7월 – MySQL 백업에서 클러스터 구축 기능 제공
- 6월 – 리전간 Read Replica 추가 가능
- 5월 – 계정간 스냅샷 기능 추가
- 4월 – Cluster View in RDS Console.
- 3월 – Additional Failover Control.
- 3월 – Local Time Zone Support.
- 3월 – 서울 리전 출시!
- 2월 – Availability in Asia Pacific (Sydney).
PostgreSQL 호환 서비스 출시
 기능적인 측면 뿐만 아니라 추가적인 데이터베이스 엔진 호환성에 대한 요청도 많이 받았습니다. 그 가장 우선 목록이 바로 PostgreSQL호환 서비스입니다. 20년 이상 개발되어온 오픈 소스 데이터베이스 엔진으로서 많은 엔터프라이즈 기업 및 스타트업에서 사용해 오고 있습니다. 특히, 고객들이 (SQL 서버나 오라클이 제공하는) 엔터프라이즈 기능과 성능 이점, PostgreSQL과 연계한 지리 정보 데이터 처리 기능에 만족하고 있는데, 이제 이들 기능을 Aurora가 제공하는 다양한 이점과 함께 활용해 볼 수 있게 되었습니다.
기능적인 측면 뿐만 아니라 추가적인 데이터베이스 엔진 호환성에 대한 요청도 많이 받았습니다. 그 가장 우선 목록이 바로 PostgreSQL호환 서비스입니다. 20년 이상 개발되어온 오픈 소스 데이터베이스 엔진으로서 많은 엔터프라이즈 기업 및 스타트업에서 사용해 오고 있습니다. 특히, 고객들이 (SQL 서버나 오라클이 제공하는) 엔터프라이즈 기능과 성능 이점, PostgreSQL과 연계한 지리 정보 데이터 처리 기능에 만족하고 있는데, 이제 이들 기능을 Aurora가 제공하는 다양한 이점과 함께 활용해 볼 수 있게 되었습니다.
오늘 Amazon Aurora용 PostgreSQL 호환 서비스를 미리보기로 출시합니다. 위에 언급한 장점과 함께, 높은 내구성과 고가용성 그리고 빠르게 읽기 복제본을 생성 및 배포할 수 있게 됩니다. 여기에 몇 가지 여러분이 좋아할 만한 사항을 소개합니다.
성능 – Aurora는 기존 환경에서 보다 2배까지 PostgreSQL 성능을 높였습니다.
호환성 – Aurora는 PostgreSQL (version 9.6.1) 오픈 소스 버전과 완벽하게 호환됩니다. 스토어드 프로시저에서도 Perl, pgSQL, Tcl, JavaScript (V8 자바스크립트 엔진 기반)을 지원할 예정입니다. 또한, Amazon RDS for PostgreSQL에서 제공하는 모든 확장 기능 및 플러그인 역시 지원할 예정입니다.
클라우드 네이티브 – Aurora를 통해 기존 AWS 서비스를 충분히 활용할 수 있으며, 아래의 서비스와 직접 연동이 가능합니다.
- AWS Key Management Service (KMS) – 암호화 기능 지원
- AWS Identity and Access Management (IAM) – 세부적인 Aurora API 및 자원 접근 제어
- Amazon Simple Storage Service (S3) –지속적으로 데이터베이스를 백업하고, 빠르게 복구 가능
- Amazon Relational Database Service (RDS) – 프로비저닝, 백업 관리, 모니터링, 컴퓨팅 자원 확장 및 데이터베이스 설정 관리
- AWS Database Migration Service – 기존 데이터센터 혹은 EC2에서 운용 중이던 PostgreSQL, Oracle, SQL Server의 손쉬운 이전 지원
- AWS Schema Conversion Tool – 데이터베이스 스키마에 대한 손쉬운 이전 지원
RDS 콘솔에서 이제 Aurora 중에서 PostgresSQL Compatible 을 선택할 수 있습니다.
그 다음 DB 인스턴스 타입과 멀티 AZ 배포 조건을 선택하고, 데이터베이스 인스턴스의 이름과 아이디와 암호를 설정합니다.
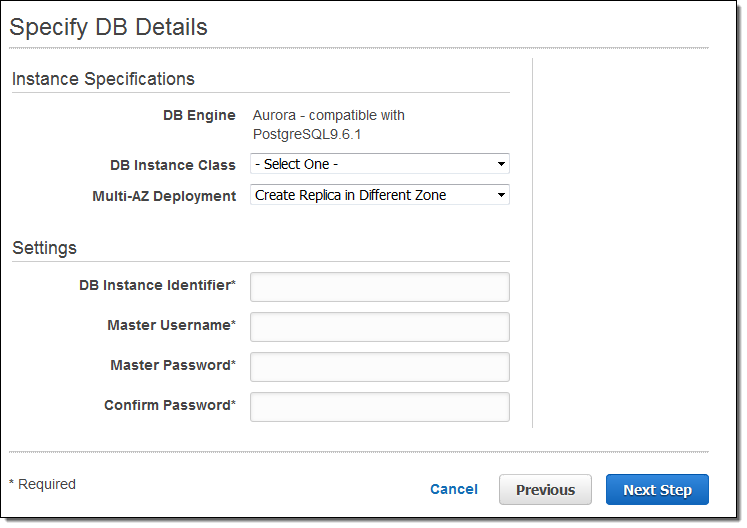
Amazon Aurora용 PostgreSQL 호환 서비스는 오늘 부터 US East (Northern Virginia) 리전에서 미리 보기로 사용 가능하며, 미리 보기 신청을 통해 바로 써 보실 수 있습니다!
몇 가지 성능 비교 사항
Dave Wein는 Amazon Aurora용 PostgreSQL 호환 서비스와 PostgreSQL 9.6.1를 비교하는 몇 가지 테스트를 진행했습니다. 비교를 위해 m4.16xlarge 인스턴스 기반 데이터베이스 서버와 c4.8xlarge 인스턴스 기반 클라이언트를 사용했습니다.
PostgreSQL는 ext4 파일 시스템 기반 15K IOPS EBS 볼륨 세 개로 이루어진 45K의 Provisioned IOPS 스토리지로 구성하고, WAL 압축 기능 및 오토 버큠(Autovacuum)을 사용하여 양쪽의 같은 워크로드로 성능 테스트를 하였습니다.
우선 쓰기 기반 Sysbench 워크 로드 (20GB 데이터베이스- 250 테이블 및 15만개 열)에서 시작해서, 매회 데이터베이스 재생성을 진행하여 시간이 지남에 따라 아래와 같은 결과를 얻었습니다.
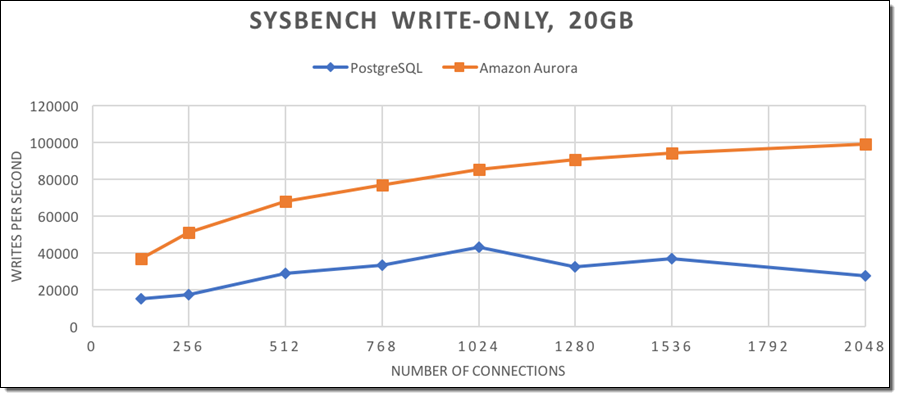
각 실행 시 전체 소요 시간은 아래와 같습니다.
progress: 1791.0 s, 34248.7 tps, lat 29.143 ms stddev 12.233
progress: 1792.0 s, 36696.2 tps, lat 27.363 ms stddev 10.882
progress: 1793.0 s, 26287.4 tps, lat 37.549 ms stddev 20.430
progress: 1794.0 s, 31377.7 tps, lat 31.993 ms stddev 17.408
progress: 1795.0 s, 36219.6 tps, lat 27.522 ms stddev 10.942
progress: 1796.0 s, 35786.4 tps, lat 27.731 ms stddev 11.262
progress: 1797.0 s, 34926.6 tps, lat 29.108 ms stddev 12.176
progress: 1798.0 s, 35663.6 tps, lat 27.766 ms stddev 11.544
progress: 1799.0 s, 36472.6 tps, lat 27.608 ms stddev 10.923
progress: 1800.0 s, 34215.3 tps, lat 28.999 ms stddev 12.095
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 2000
query mode: prepared
number of clients: 1000
number of threads: 1000
duration: 1800 s
number of transactions actually processed: 61665153
latency average = 29.175 ms
latency stddev = 14.011 ms
tps = 34250.027914 (including connections establishing)
tps = 34267.524614 (excluding connections establishing)
또한 비슷한 실행의 마지막 40 분을 다루는 초당 처리량 그래프를 아래와 같이 공유했습니다.
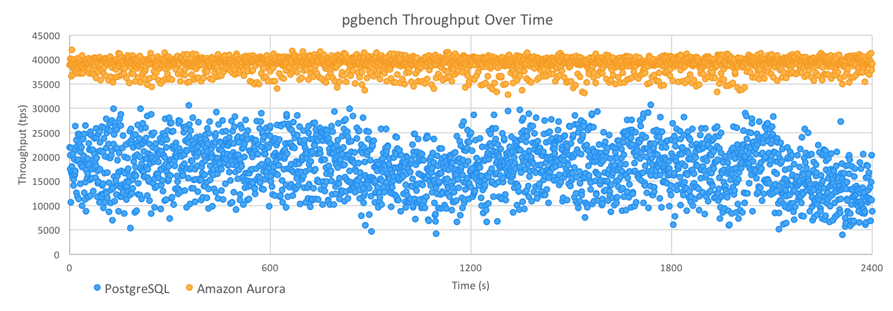
위에서 보시다시피, Amazon Aurora는 PostgreSQL보다 높은 처리량을 제공하여 지터의 1/3 (표준 편차는 각각 1395 TPS 및 5081 TPS)입니다.
David와 Grant는 2017 년 초에 보다 자세한 결과물을 공유하기 위해 데이터를 수집하고 있습니다.
곧 출시 – 성능 확인 기능
앞으로 아주 다양한 측면에서 데이터베이스 성능을 이해할 수 있도록 디자인한 새로운 도구를 출시할 예정입니다. 각 질의에 대한 세부적인 사항과 데이터베이스가 어떻게 질의를 처리하는지 상세히 볼 수 있습니다. 아래는 미리보기 스크린샷입니다.
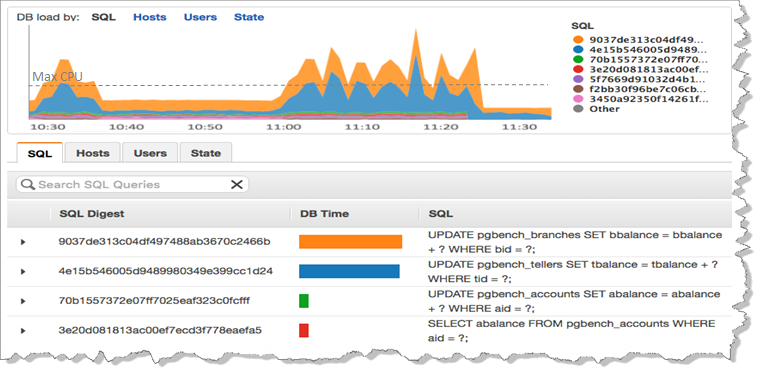
본 미리 보기 기능에 새로운 성능 보고 기능을 포함할 예정이고, 계속해서 관련 소식을 본 블로그를 통해 전달해 드리겠습니다.
— Jeff;
이 글은 AWS re:Invent 2016 신규 출시 소식으로 Amazon Aurora Update – PostgreSQL Compatibility의 한국어 번역입니다. re:Invent 출시 소식에 대한 자세한 정보는 12월 온라인 세미나를 참고하시기 바랍니다.
Amazon Aurora 기반 개발 및 테스트용 신규 T2.Medium DB 인스턴스 타입 추가
Amazon Aurora는 이미 db.r3.large (2 vCPUs/15 GiB of RAM)에서 db.r3.8xlarge (32 vCPUs/244 GiB of RAM)까지 단계별로 다섯 가지의 데이터베이스 인스턴스 타입을 지원하고 있습니다. 이를 통해 보다 높은 성능을 위해 폭넓은 애플리케이션 범위를 지원 하고 있습니다.
 오늘 여섯번째 선택으로 db.t2.medium (2 vCPUs/4 GiB of RAM) 데이터베이스 인스턴스 타입 지원을 소개합니다. 다른 T2 인스턴스 처럼 싱글 코어 성능의 40% 정도를 보장하고, CPU를 많이 쓰는 질이나 다른 데이터베이스 작업에 CPU 성능 전체를 사용할 수 있는 크레딧을 제공합니다. 본 인스턴스 타입은 CPU 크레딧을 처음에 전체를 할당하고, CPU 추가 성능시 크레딧을 사용하고, 그렇지 않을 시간에는 보충하는 모델을 가지고 있습니다. (자세한 사항은 저가 T2 인스턴스 출시 – 급격한 트래픽 처리 가능 참고.)
오늘 여섯번째 선택으로 db.t2.medium (2 vCPUs/4 GiB of RAM) 데이터베이스 인스턴스 타입 지원을 소개합니다. 다른 T2 인스턴스 처럼 싱글 코어 성능의 40% 정도를 보장하고, CPU를 많이 쓰는 질이나 다른 데이터베이스 작업에 CPU 성능 전체를 사용할 수 있는 크레딧을 제공합니다. 본 인스턴스 타입은 CPU 크레딧을 처음에 전체를 할당하고, CPU 추가 성능시 크레딧을 사용하고, 그렇지 않을 시간에는 보충하는 모델을 가지고 있습니다. (자세한 사항은 저가 T2 인스턴스 출시 – 급격한 트래픽 처리 가능 참고.)
db.t2.medium 인스턴스 타입은 정식 서비스 전 개발 및 테스트 혹은 작은 서비스에 최적의 비용 대비 성능을 보여줄 것입니다. CPUCreditUsage나 CPUCreditBalance 통계를 통해 크레딧 상태를 체크하는 것이 좋습니다.
정식 출시
오늘 부터 Amazon Aurora 데이터베이스 선택 시 모든 리전에서 사용 가능합니다. 사용 금액은 시간 당 $0.125(서울 리전)로 부터 시작되며, 예약 인스턴스 또한 지원 합니다.
— Jeff;
이 글은 Use Amazon Aurora for Dev & Test Workloads with new T2.Medium DB Instance Class의 한국어 번역입니다.
Amazon Aurora 업데이트 – Lambda Function 호출 및 S3 데이터 읽기 지원
AWS 서비스들은 그 자체만으로도 훌륭하지만, 서로 결합함으로써 더욱 다양한 서비스를 만들 수 있습니다. 저희의 서비스 모델은 각 서비스를 선택하여 학습하여 경험을 쌓은 다음, 다른 서비스와 결합 및 확장하는 레고블럭을 조립하는 것 같은 방식입니다. 이를 통해 각 서비스를 다양하게 활용할 기회와 함께 고객의 요구에 따라 서비스 로드맵에 반영할 수 있습니다.
오늘은 이와 관련하여 MySQL 호환 관계형 데이터베이스 서비스인 Amazon Aurora에 두 가지 기능을 추가합니다.
- Lambda 함수 호출 – Amazon Aurora 데이터베이스의 스토어드 프로시저(stored procedures)에서 AWS Lambda 함수를 호출 할 수 있습니다.
- S3 데이터 읽기 – Amazon Simple Storage Service (S3) 버킷에 저장된 데이터를 Amazon Aurora 데이터베이스에서 읽을 수 있습니다.
위의 두 가지 기능은 다른 AWS 서비스를 연계하기 위해 Amazon Aurora에 적절한 권한을 부여해야합니다. IAM 정책(Policy) 및 IAM 역할(Role)을 만들고, 그 역할을 Amazon Aurora 데이터베이스 클러스터에 부여합니다. 자세한 단계는Authorizing Amazon Aurora to Access Other AWS Services On Your Behalf를 참조하십시오.
Lambda 함수 통합
관계형 데이터베이스 트리거(trigger)와 스토어드 프로시저를 함께 사용하여 본 기능을 수행할 수 있습니다. 트리거는 특정 테이블 작업 전후에 수행 할 수 있습니다. 예를 들어, Amazon Aurora는 MySQL과 호환성이 있기 때문에 INSERT, UPDATE, DELETE 작업에 트리거를 지원합니다. 스토어드 프로시저는 트리거에 대한 응답에서 실행 가능한 스크립트입니다.
Lambda 함수를 스토어드 프로시저를 사용하여, Aurora 데이터베이스와 다른 AWS 서비스를 묶을 수 있습니다. Amazon Simple Email Service (SES)를 이용하여 이메일을 보내거나 Amazon Simple Notification Service (SNS)를 이용해 알림을 보내고, Amazon CloudWatch에 사용자 정의 통계를 추가하거나, Amazon DynamoDB 테이블을 업데이트할 수 있습니다.
그 외에도 복잡한 ETL 작업 또는 워크 플로우, 데이터베이스 테이블에 대한 감사, 성능 모니터링 및 분석 등의 용도로도 사용할 수 있습니다.

스토어드 프로시저에서 mysql_lambda_async 프로시저를 호출 하면 됩니다. 이 프로시저는 비동기적으로 주어진 Lambda 함수를 실행하기 위해 함수 실행 완료를 기다리지 않고 처리를 종료합니다. Lambda 함수에 이용하는 AWS 서비스 및 자원에 대한 권한을 부여해야합니다.
자세한 내용은 Invoking a Lambda Function from an Amazon Aurora DB Cluster를 참조하십시오.
S3 데이터 읽기
또한, AWS의 주요서비스인 Amazon S3 버킷에 저장된 데이터를 직접 Aurora에 가져올 수 있게 되었습니다 (지금까지는 한 번 EC2 인스턴스에 다운로드 한 후 가져와야했습니다.)
Amazon Aurora 클러스터에서 접근 가능하면, AWS 어느 리전에 데이터가 배치되어 있어도 읽기 가능합니다. 형식은 텍스트 또는 XML 형식을 지원합니다.
텍스트 형식의 데이터를 가져 오기 위해서는, LOAD DATA FROM S3 명령을 이용합니다. 이 명령은 MySQL의 LOAD DATA INFILE과 거의 같은 옵션을 지원합니다. 그리고, 압축 데이터는 현재 지원하지 않습니다. 특정 행이나 필드 구분자와 문자 집합 설정이 가능하고, 지정한 행과 열 수를 무시하고 통합 할 수 있습니다.
XML 형식 데이터를 가져 오기 위해 새로운 LOAD XML from S3
<row column1="value1" column2="value2" />
...
<row column1="value1" column2="value2" />
또는 아래와 같습니다.
<row>
<column1>value1</column1>
<column2>value2</column2>
</row>
...또는 아래와 같습니다.
<row>
<field name="column1">value1</field>
<field name="column2">value2</field>
</row>
...더 자세한 사항은 Loading Data Into a DB Cluster From Text Files in an Amazon S3 Bucket 문서를 참고하십시오.
정식 출시
본 신규 기능은 오늘부터 이용하실 수 있습니다! 추가로 요금이 부과되지 않지만, 일반적인 Amazon Aurora, Lambda, S3 요금이 발생합니다.
— Jeff;
이 글은 Amazon Aurora Update – Call Lambda Functions From Stored Procedures; Load Data From S3의 한국어 번역입니다.
Amazon Aurora – 신규 읽기 엔드 포인트 기능 (로드 밸런싱 및 고가용성 제공)
Amazon Aurora는 더욱 사용하기 쉬우면서 강력한 데이터베이스 서비스로 자리잡고 있습니다. 지난 몇 달 동안 저희는 MySQL 백업에서 클러스터 생성, 리전간 Read Replica 추가 가능, 계정간 스냅샷 공유 기능 추가, 장애 처리를 위한 추가 기능 및 데이터베이스 마이그레이션 서비스 등을 지속적으로 출시했습니다.
오늘은 Aurora 읽기 복제 기능을 위해 클러스터 수준의 읽기 엔드 포인트를 추가했습니다. 여러분이 만든 응용 프로그램은 지금까지 하던 방식 대로 특정 읽기 복제본에 대해 직접 쿼리를 실행할 수도 있습니다. 이번에 추가한 읽기 엔드 포인트를 이용하도록 변경하면, 부하 분산 및 고가용성 등 두 가지 큰 이점을 얻을 수 있습니다.
로드 밸런싱(Load Balancing)
클러스터 엔드 포인트에 연결하여 DB 클러스터의 읽기 복제본 간의 로드 밸런싱ㅣ 가능합니다. 이것은 읽기 워크로드를 분산하고, 사용 가능한 복제본 간에 자원을 효율적으로 활용할 수 있어 보다 높은 성능을 얻을 수 있습니다. 장애 발생 시, 각 응용 프로그램이 연결되어있는 복제본이 기본 인스턴스로 승격하는 경우 연결은 일단 끊기고, 그 후 다시 연결을 할 클러스터의 다른 복제본에 읽기 쿼리를 실행할 수 있습니다.
고 가용성(Higher Availability)
Aurora 복제본을 각 가용 영역(Availability Zone)마다 배치하고, 읽기 엔드 포인트를 통해 연결할 수 있습니다. 특정 가용 영역에 문제가 만일 발생했을 경우, 읽기 엔드 포인트를 이용하여 최소한의 다운 타임으로 읽기 트래픽을 다른 가용 영역내 복제본에서 실행 가능합니다.
엔드 포인트 확인하기
읽기 엔드 포인트는 Aurora Console에서 확인 가능합니다.
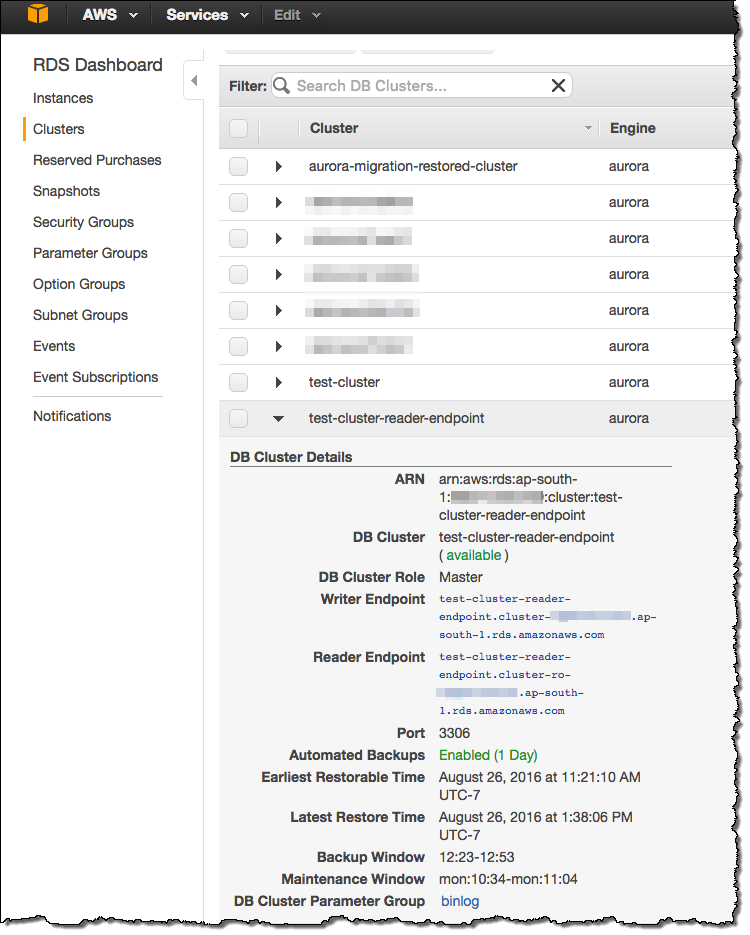
본 기능은 Aurora를 제공하는 모든 리전에서 지금 바로 사용 가능합니다.
— Jeff;
이 글은 New Reader Endpoint for Amazon Aurora – Load Balancing & Higher Availability의 한국어 번역입니다.