AWS Partner Network (APN) Blog
Automating Signature Recognition Using Capgemini MLOps Pipeline on AWS
By Dr. Hany Hossny Mahmoud, AI & Data Science Manager – Capgemini
By Vikas Nambiar, Manager, Partner Solutions Architect – AWS
 |
| Capgemini |
 |
Recognizing a user’s signature is an essential step in banking and legal transactions. The process involves relying on human verification of a signature to establish a person’s identity.
However, this can be error prone, time consuming, and limits the automation for many banking applications that require human verification. The challenge can be solved using image processing, computer vision, machine learning, and deep learning.
Automating signature recognition enables most transactions to be done end-to-end rapidly and with minimal error, except if there’s an issue with the data and then it must be reviewed by humans.
A reliable signature checker can minimize the need for human verification to less than 5% of the needed human efforts manually. A signature checker enables process automation for user identity verification, such as signing up to new accounts or signing on home loan documents, or simply cashing a check with single or multiple signatures.
In this post, I will explain how Capgemini uses machine learning (ML) from Amazon Web Services (AWS) to build ML-models to verify signatures from different user channels including web and mobile apps. This ensures organizations can meet the required standards, recognize user identity, and assess if further verifications are needed.
Capgemini is an AWS Premier Tier Consulting Partner and Managed Cloud Service Provider (MSP) with a multicultural team of 220,000 people in 40+ countries. Capgemini has more than 12,000 AWS accreditations and over 4,900 active AWS Certifications.
The Signature Recognition ML Model
To define the model, Capgemini’s ML development team creates the model with two parallel datasets for golden data and input data:
- The golden data is the set of signatures stored in the bank database following the compliance standards of clarity and readability.
- The input data set is typically a set of signatures captured manually using a mobile camera or home scanner. This data tends to include image problems such as blur, glare, distortion, noisy background, and low resolution.
The ML team builds a pipeline to transform the input signatures to the gold standard format, and then find a recognition method to verify if the signature matches any of the golden signatures in the database.
The steps listed below describe how the process is implemented using on-premises pipeline:
- Input validation: The input image is first validated against a set of metrics to detect if it has any of the known issues such as blur, glare, noise, or low resolution. If the image has any of these issues, it should be fixed using known image processing methods including windowing, filtering, transformation, and histogram analysis. Afterwards, the image is re-evaluated using the same metrics to decide whether to pass the image to the model or reject it, then asks the user to re-upload the image or ask for human verification.
- Data pre-processing: Check images usually have multiple content such as printed names, logos, and serial numbers. Therefore, it needs pre-processing to extract the signature out of it, which includes windowing, edge detection, erosion, dilation, binarization, quantization, and others. Capgemini uses 2D signal processing libraries such asSciPy and OpenCV for signal processing and image processing.
- Feature engineering: Capgemini extracts and finds the most informative features from the images, such as RGB and HSV histograms, DFT components, color bins, and spatial coordination. These features are used as inputs to the learning algorithms (SciPy).
- Model selection: This is the process of evaluating multiple ML and deep learning algorithms to classify whether the image is a proper signature compared with the golden truth. This includes trying a variety of algorithms with different configurations and multiple pre-processing methods, and cross-validating results using multiple datasets using Scikitlearn and Keras.
- Model optimization: Once the ML pipeline is built, it’s optimized to achieve the best possible results using the embedded parameters in every step of the pipelines. This includes binarization threshold, clustering granularity, count of reduced dimensions, algorithm parameters, and validation methods.
- Non-functional validation: Once the ML pipeline is proven effective, it’s important to validate the response time, computational needs, required memory, and scalability potential to deal with overload and stress (Jmeter).
- Deployment as API: The ML pipeline is deployed as a restful API using Flask that is hosted using Gunicorn or FastAPI with a proxy web interface using NGINX.
The Traditional Machine Learning Pipeline
Every step of the machine learning development process was convoluted with another step of the DevOps pipeline as the pipeline consists of steps below:
- Development and coding including building data extract, transform, load (ETL), pre-processing, feature engineering, algorithm selection, and model testing. This can be implemented using any integrated development environment (IDE).
- Source control using tools to manage check-ins/outs, merging, branching, forking, push, and commit.
- Code flow orchestration from source control to deployment:
- Virtualize the development environment to have all the dependencies in one place with the exact versions.
- Build code using the previously set-up environment either manually or automatically.
- Ship the containers to the deployment environment such as test, staging, pre-production, or production.
- Notify the model reviewer to verify the deployed model. Upon their approval, the container will be shipped to the next environment.
- Before the model is shipped to deployment, it may require human verification of the performance, especially for non-functional requirements such as response time, security, scalability, and usability. This is where you need a standard testing process and an issue tracker for reporting and follow up.
- Once the model is deployed to the server, it needs an API gateway to provide the restful features such as message queuing, load balancing, and scalability for the models deployed.
- After deployment, Capgemini monitors the performance of the model in the runtime to track data drift and the concept drift of the model and act accordingly by tuning the model or rebuilding it.
Such a pipeline delivers models as API that will be hosted as a webservice, then used or integrated with a frontend web or mobile application developed by software development team.
Below is an overview of how such a pipeline’s architecture delivers a single model from development to production.

Figure 1 – Traditional ML pipeline for the signature recognition.
Such a pipeline require lots of interference and work from DevOps engineers to get the model from development to the final stage. The sequence diagram presented below illustrates the machine learning development process and its reliance on the human interference, specifically the DevOps engineers.

Figure 2 – Traditional ML development process and its reliance on human interference.
Issues Faced with On-Premise Implementations
Although the above pipeline delivers the required model, a couple of issues hinder the productivity of the team and reduce the likelihood of deployment using this pipeline. Capgemini’s observations of such an implementation are:
- More than 30% of ML working hours are wasted on operational steps along the road, including check-in, virtualizing, testing, reviewing, fixing, staging (pre-production environment), monitoring, and deployment. This time can be saved by automating the DevOps part and adopting CI/CD philosophy.
- The delivered model may not adhere to non-functional requirements such as model size, memory management, or response time. These issues are fatal enough to kill the whole model unless it’s realized at early stages of the development process, which can only be ensured via CI/CD environment.
As such, this process should be automated to minimize wasted time, delays, human efforts, and operational costs associated with maintaining the pipeline and reducing human intervention-related errors.
To overcome these issues, Capgemini implements its MLOps pipeline solution using Amazon SageMaker to speed up the process and minimize effort and time.
Capgemini MLOps Pipeline on AWS
To build such a pipeline using AWS managed service offerings that reduce operational maintenance efforts, follow these steps:
- Deploy notebooks in Amazon SageMaker, analyze the data using computer vision libraries such as OpenCV and scikit image, and build a set of features.
- The features are stored in Amazon DynamoDB, as the same image may have a huge number of features including RGB values, histograms, pixels, HSV, processed image such as binarization, erosion, dilation, color distributions, and quantized version.
- The first step is to differentiate if the image is a signature or not. This is a basic binary classification problem that can be done using AutoML or Amazon SageMaker Autopilot:
- Autopilot analyzes the features and finds the most informative ones in association with the ground truth, which is whether the image is a signature or not.
- Autopilot picks a set of metrics to evaluate the predictive models including precision, recall, F-score, area under ROC curve, and area under PR curve.
- Autopilot experiments multiple algorithms to find the best predictions according to the predetermined set of metrics.
- Autopilot optimizes the hyperparameters of the picked algorithm to achieve the best predictability and generate the model accordingly.
- Once the model is developed and validated using the predefined metrics, the model and code will be committed to AWS CodeCommit.
- The code will be built and deployed using AWS CodeBuild and AWS CodeDeploy.
- The model, code, and dependencies will be virtualized, containerized, and registered using Amazon Elastic Container Registry (Amazon ECR).
- The containers will be registered on AWS CloudFormation for provisioning, scaling, and management.
- The model will be hosted to Amazon API Gateway to be accessible as either a restful API or a WebSocket API. The APIs will be accessible via web apps and mobile apps.
Capgemini MLOps Pipeline on AWS simplifies the whole process of machine learning development to production. ML development teams can focus on data manipulation and feature preparation, and they don’t need to bother about the DevOps tasks such as source control, versioning, virtualization, containerization, deployment, scaling, and monitoring.
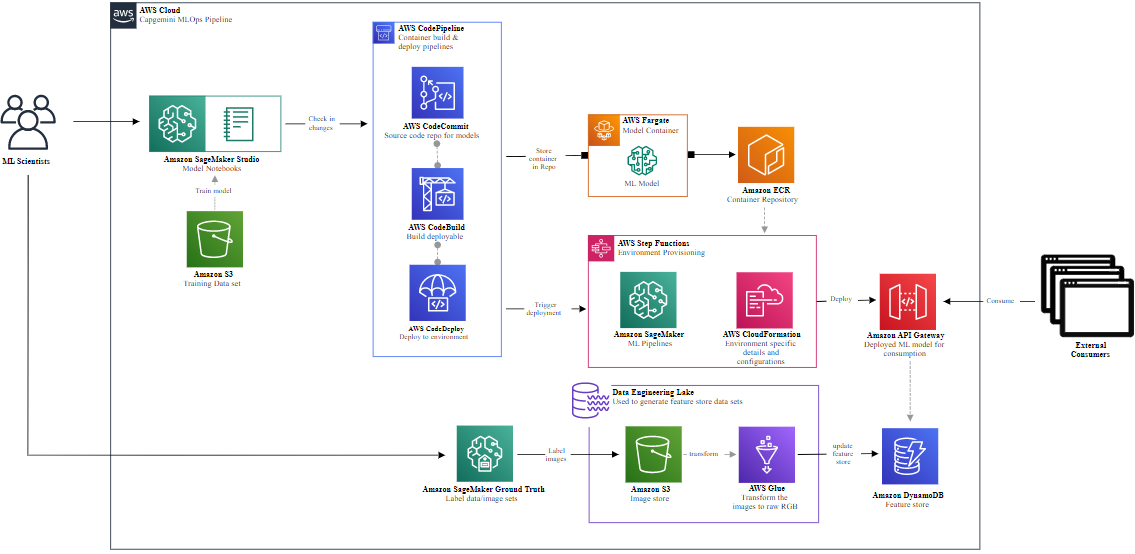
Figure 3 – Capgemini MLOps pipeline for signature recognition.
Subsequent sequence diagram requires minimal human interference after using Amazon SageMaker. The MLOps pipeline as implemented with AWS minimizes loops, bottlenecks, dependencies, and wasted time.
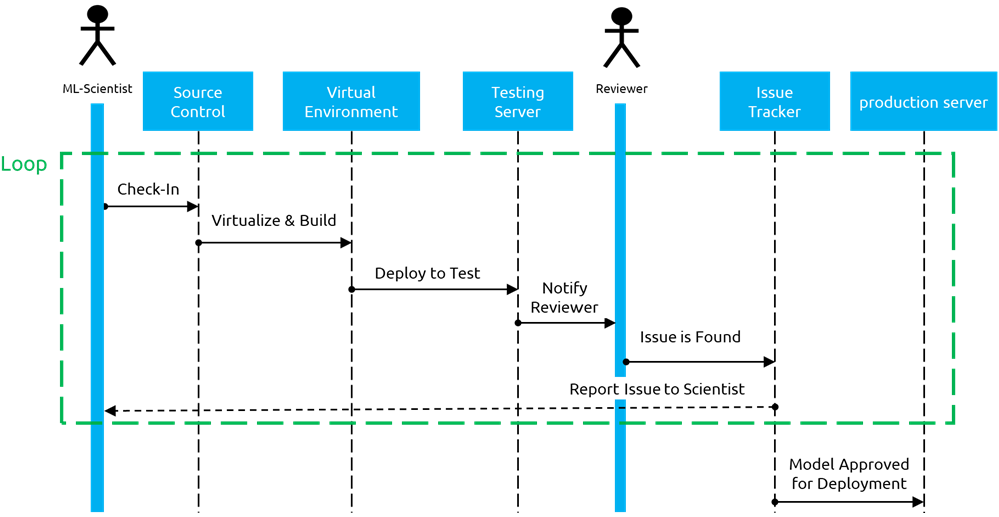
Figure 4 – Capgemini MLOps pipeline sequence diagram using Amazon SageMaker.
Conclusion
Machine learning development and MLOps are two tasks convoluted with each other. If one of them has a problem, the other cannot move forward.
In this post, I showed how Capgemini can build ML models to recognize signatures using AWS services such as Amazon SageMaker that simplifies DevOps tasks and accelerates development to deployment process. This allows data scientists to focus on the scientific challenges instead of being concerned with deployment and environment issues.
The content and opinions in this blog are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
.

.
Capgemini – AWS Partner Spotlight
Capgemini is an AWS Premier Tier Consulting Partner and MSP with a multicultural team of 220,000 people in 40+ countries. Capgemini has more than 12,000 AWS accreditations and over 4,900 active AWS Certifications.
Contact Capgemini | Partner Overview
*Already worked with Capgemini? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.