AWS Partner Network (APN) Blog
How to Build and Deploy Amazon SageMaker Models in Dataiku Collaboratively
By Sunny Porinju, Sr. Product Marketing Manager at Dataiku
 |
Organizations often need business analysts and citizen data scientists to work with data scientists to create machine learning (ML) models, but they struggle to provide a common ground for collaboration.
Newly enriched Dataiku Data Science Studio (DSS) and Amazon SageMaker capabilities answer this need, empowering a broader set of users by leveraging the managed infrastructure of Amazon SageMaker and combining it with Dataiku’s visual interface to develop models at scale.
Dataiku, an AWS Advanced Technology Partner with the AWS Machine Learning Competency, is an artificial intelligence (AI) and analytics production platform. It was named a Leader in both the Gartner 2020 Magic Quadrant for Data Science and Machine Learning Platforms and the Forrester Wave: Multimodal Predictive Analytics and Machine Learning Solutions, Q3 2020.
Dataiku orchestrates the entire ML lifecycle and makes it accessible to data scientists and analysts alike.
Meanwhile, Amazon Web Services (AWS) has created a powerful machine learning platform for developers in Amazon SageMaker, a fully managed service that provides the ability to build, train, and deploy ML models quickly.
By leveraging the two technologies together, data teams can:
- Augment productivity by enabling data scientists and engineers to create and deploy AI applications with greater velocity, leveraging Dataiku’s data prep, feature engineering, and AutoML capabilities to operationalize models and associated data pipelines.
. - Support hundreds of less-technical data workers with intuitive tools for manipulating, analyzing, and visualizing large datasets. Business analysts can reveal new insights and make the right decisions based on data.
. - Improve AI monitoring, governance, compliance, and reuse by removing silos and sharing best practices across the enterprise.
Solution Architecture
The architecture diagram below highlights how Dataiku integrates with AWS. Dataiku DSS enables users to leverage:
- AWS Glue as a metastore, and Amazon Athena for SQL queries, against Amazon Simple Storage Service (Amazon S3) data.
- Amazon Elastic Kubernetes Service (Amazon EKS) for containerized Python, R, and Spark machine learning, as well as API service deployment.
- Amazon EMR as a data lake for in-cluster Hive and Spark processing.
- Amazon Redshift for in-database SQL processing.
- Amazon SageMaker, Amazon Rekognition, and Amazon Comprehend for ML and AI services.

Figure 1 – Solution architecture highlighting Dataiku’s integrations with AWS.
Dataiku + Amazon SageMaker in Action
New Amazon SageMaker capabilities in Dataiku allow users to:
- Prepare datasets specifically for use with Amazon SageMaker.
- Quickly convert any dataset to the formats required by Amazon SageMaker.
- Visually create analytics pipelines and applications that use models developed in Amazon SageMaker.
- Use visual interface in Dataiku to train and score models leveraging Amazon SageMaker Autopilot.
- Allow programmatic control of Amazon SageMaker through auto-generated Dataiku notebooks.
- Leverage pre-trained Amazon SageMaker models in Dataiku pipelines.
Let’s look at an example to see these capabilities in action and understand how you can leverage Amazon SageMaker and Dataiku to empower the broader data team.
We’ll be using a telecommunications churn use case where the business goal is to predict customers that are likely to churn, and the revenue impact of churn so that marketing or customer teams can take the best preventative action.
To follow along with this example more closely and to try out Dataiku’s Amazon SageMaker capabilities yourself, enroll in Dataiku’s free course on churn prediction or download the dataset.
In this example, we start with an existing Dataiku Flow—including data preparation and pre-existing model—to segment customers, predict churn, and analyze the impact on revenue.
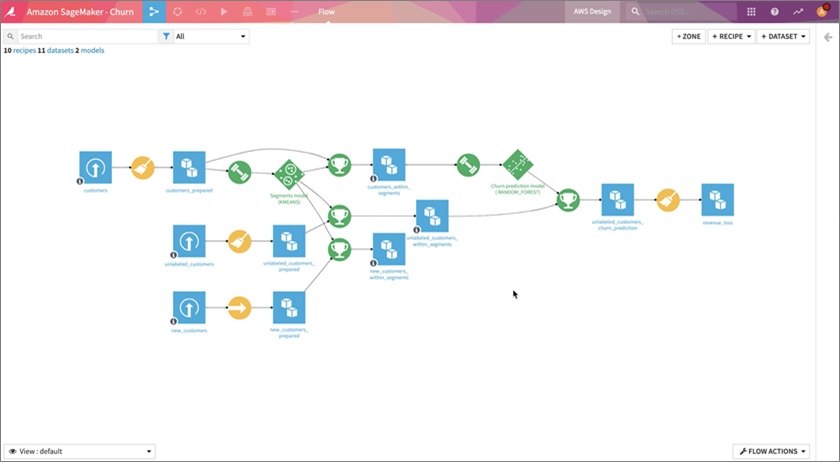
Figure 2 – Dataiku Flow with visual recipes to segment customers, predict churn, and analyze impact on revenue.
We are working with three input datasets in this example: the labeled customer data for training, unlabeled customer data for scoring, and new customer data for evaluating performance once the churn prediction model is built.
In the flow above, we use a K-means clustering algorithm to segment the data between existing customers, unlabeled customers, and new customers. Execution of the K-means clustering can be easily offloaded to Amazon EKS with Dataiku’s built-in Kubernetes cluster management interface.
Convert to Amazon SageMaker Format
Users performing data prep, model training, scoring, and validation in Dataiku are often not the same users coding the production-ready Amazon SageMaker models.
With the ability to convert a dataset to CSV or recordIO-protobuf formats, business analysts can visually work with the data in Dataiku DSS and send it over to the technical team in the necessary format.
With this capability, data scientists can ensure the data is in the final format needed for model training. This capability also allows data scientists and developers to work entirely in code and easily integrate their work back into Dataiku.
Train with Amazon SageMaker Autopilot
By selecting the SageMaker Autopilot recipe in Dataiku and choosing the output folder to save the results (we are using Amazon S3), we launch the visual recipe (shown in Figure 3 below) to configure the prediction parameters. Using the default settings, click RUN to train a new churn prediction model on the labeled customer data.
All of the files created as part of the Amazon SageMaker Autopilot job, including the models, code, and summary report, will be available inside Dataiku DSS once the job is complete.
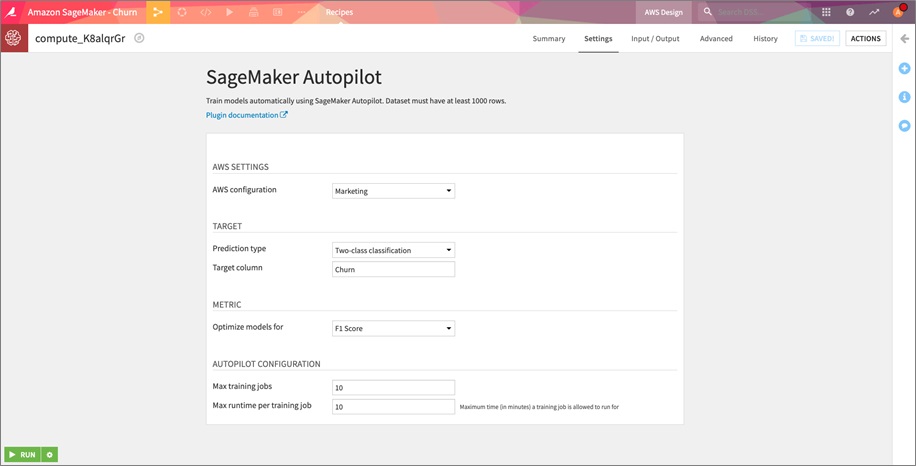
Figure 3 – Amazon SageMaker Autopilot setup page.
Now, sit back and allow Amazon SageMaker’s fully managed service to do the heavy lifting while training your model in a highly optimized way. No more worrying about technology orchestration or complex configurations—just hit run, and voila!
Batch Scoring with Amazon SageMaker
We can now use the model created by Amazon SageMaker Autopilot to score our unlabeled data. We’ll select the SageMaker Score recipe (shown in Figure 4 below), choose the model folder, and provide an output dataset for the scored data.
We can reuse the same connection configuration from model training, leave the model selection to automatic, and click RUN.
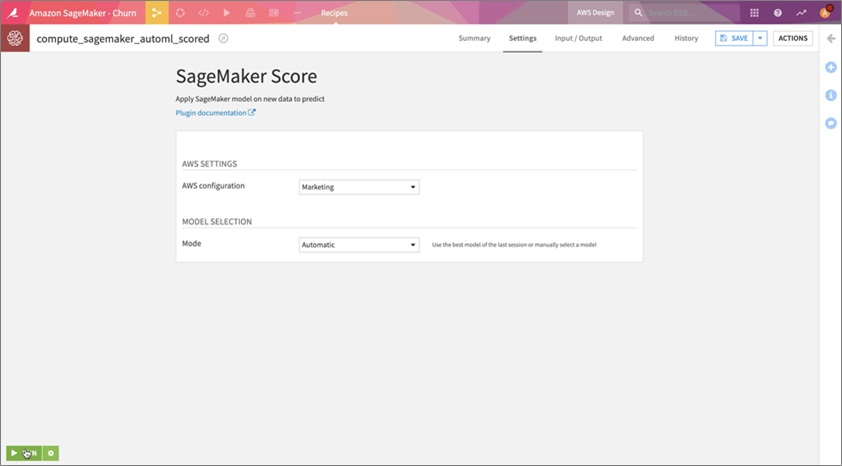
Figure 4 – Amazon SageMaker Score setup page in Dataiku DSS.
As seen in this example, scoring unlabeled data with the enhanced Amazon SageMaker batch scoring capability is fast and simple in Dataiku DSS.
The easy-to-use visual interface abstracts away the complexity of working with Amazon SageMaker’s engine for less technical users without compromising its computational prowess. That means business analysts and citizen data scientists can quickly train ML models and apply them to unlabeled datasets with a just few clicks.
Model Evaluation with Amazon SageMaker
We can use the SageMaker Evaluate recipe in the Amazon SageMaker plugin to test the model against new labeled data. Once again, we select the model folder and create new Amazon S3 datasets for the scored output data and model performance metrics.
Next, we can accept the default settings and click RUN.
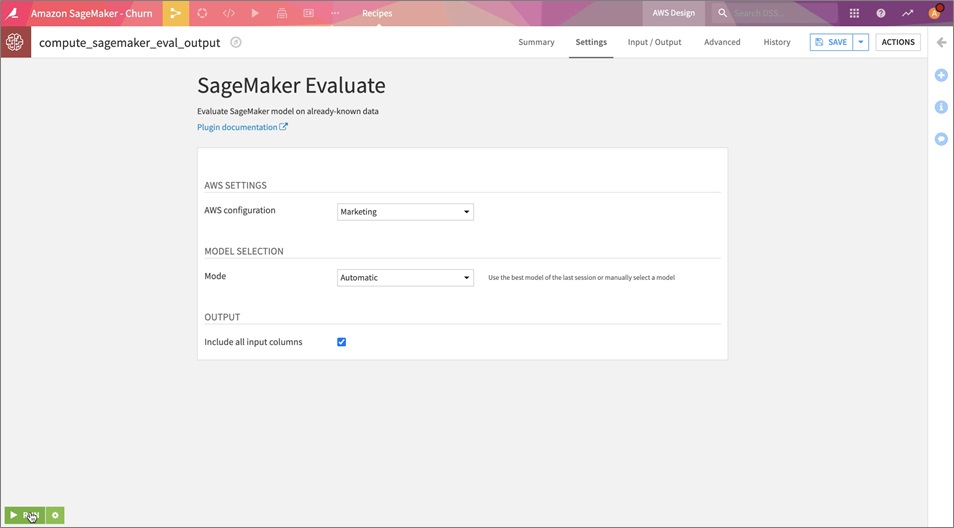
Figure 5 – Amazon SageMaker Evaluate setup page in Dataiku DSS.
Model evaluation is an integral part of the model development process. With the Evaluate recipe, data teams can validate models quickly, helping them find the best model for any given data and choose models that will work in the future.
Also, assuming the churn prediction model has been in use for a while and there is a risk of model drift, it’s a good idea to periodically check model performance to make sure it’s still working as expected.
Results
Now that the model evaluation job is complete, we can have a look at the results. We see key model metrics like accuracy, F1 score, precision, and recall to understand how the newly trained Amazon SageMaker model performs on new customer data.
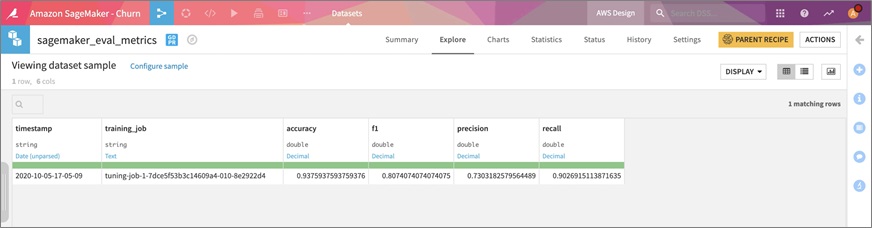
Figure 6 – Evaluation metrics for newly trained Amazon SageMaker model in Dataiku DSS.
The scored output dataset combined with the evaluation metrics helps us track the model performance over time, and understand when we might need to train a new model.
Using the customer churn example, we have used Dataiku DSS and Amazon SageMaker to train a model on our labeled data, use that model to score our unlabeled data, and finally generate metrics to evaluate the performance of our model on new customer data.
Amazon SageMaker Endpoint Scoring
To get an immersive experience with Amazon SageMaker in Dataiku, we enhanced our capability to allow users to plug in any deployed models into their Dataiku flows for scoring.
Expand the reach and impact of these projects by enabling anyone in the organization to use any deployed Amazon SageMaker model.
Conclusion
With the enriched capabilities for leveraging Amazon SageMaker from Dataiku Data Science Studio (DSS), any and all users within an organization can collaborate and deliver cross-company AI projects and initiatives.
Advanced data science teams that operationalize Amazon SageMaker models will get a frictionless experience collaborating on data projects with business analysts and citizen data scientists.
You can enable citizen data scientists to collaborate with teams of data scientists, and empower them to develop their own models at scale. To get started, download Dataiku DSS for free. Dataiku DSS is also available on AWS Marketplace.
The content and opinions in this blog are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
.

.
Dataiku – AWS Partner Spotlight
Dataiku is an AWS Machine Learning Competency Partner that provides the Data Science Studio (DSS), a development environment for data scientists and data preparation.
Contact Dataiku | Partner Overview | AWS Marketplace
*Already worked with Dataiku? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.