AWS Partner Network (APN) Blog
Low Latency Real-Time Cache Updates with Amazon ElastiCache for Redis and Confluent Cloud Kafka
By Joseph Morais, AWS Evangelist, Global Partner Solutions – Confluent
By Jobin George, Sr. Partner Solutions Architect – AWS
By Roberto Luna Rojas, ElastiCache Specialist Solutions Architect – AWS
 |
Confluent is an AWS ISV Partner with the Data & Analytics Competency and Service Ready designations in Amazon Redshift, AWS PrivateLink, and AWS Outposts.
Founded by the creators of Apache Kafka, Confluent offers a platform for data in motion that enables processing data as real-time streams across on-premises and Amazon Web Services (AWS).
In this post, we demonstrate how to power a logistics and inventory system with microsecond read performance powered by Amazon ElastiCache for Redis and durable streaming with Kafka powered by Confluent Cloud.
You can use this pattern for building streaming applications and other broad sets of use cases with asynchronous requirements for low latency reads. Apache Kafka consumption of records typically takes between 20-30ms (1 KB JSON). With ElastiCache, read operations take from 0.352-0.713ms for the same payload, which is, on average, 47X faster than Kafka.
Follow along as we walk through a use case to reduce an ecommerce website’s page loads to half a second or less. For use cases like this, it’s imperative we shave off every millisecond we can. Amazon ElastiCache provides the speed while Confluent provides the persistence of the data.
Solution Overview
Amazon ElastiCache is a scalable, fully managed in-memory data store that delivers sub-millisecond latency performance. It’s compatible with two popular in-memory data stores engines: Memcached and Redis. Redis is the most widely deployed because it’s easy to use, highly available, and supports multiple advanced data structures.
Confluent Cloud is a scalable, resilient, and secure event streaming platform powered by Apache Kafka. On top of fully managed Kafka, Confluent Cloud provides a number of other services that allow both operators and developers to focus on building applications instead of managing clusters.
Figure 1 illustrates a high-level, end-to-end overview of the solution, and we’ll go into each building block in more detail. In this use case, users interact with various microservices via Amazon API Gateway, including this post’s inventory service which leverages ElastiCache for Redis as a caching solution for the inventory and product detail lookups.
The cache updates in near-real-time using a Confluent sink connector, which observes changes to the topics in Confluent Cloud.
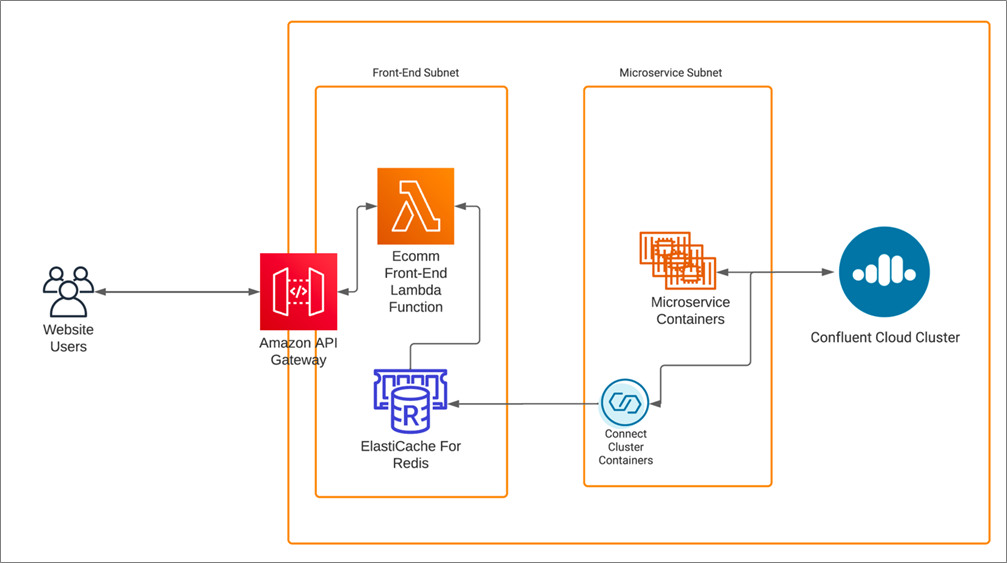
Figure 1 – Confluent Cloud cluster and Amazon ElastiCache.
Building Blocks
Apache Kafka is an open-source distributed event streaming platform used by many companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
Confluent can help organizations run Kafka faster and at scale by leveraging elastic scaling capabilities.
Confluent offers two main products:
- Confluent Platform: A complete, enterprise-ready distribution of Apache Kafka.
- Confluent Cloud: A fully managed SaaS offering for Apache Kafka.
Built as a cloud-native service, Confluent Cloud offers a serverless experience with self-serve provisioning, elastic scaling, and usage-based billing so you pay for what you stream. Confluent Cloud protects your data using open standard security features, and the service reliability is backed by an enterprise-grade uptime SLA.
In addition to fully managing your Kafka clusters, Confluent Cloud has fully managed components including schema registry, connectors to popular AWS services such as Amazon Simple Storage Service (Amazon S3) and Amazon Redshift, and other databases such as ksqlDB. This enables you to harness the full power of data in motion without any of the operational burdens.
Caching is a widely used solution to achieve massive scale for high throughput and low latency applications. Most customers who use Amazon ElastiCache use it for caching due to its simplicity as a key value store.
ElastiCache provides a high performance, resizable, cost effective in-memory store, and removes the complexity associated with deploying and managing a distributed cache environment. It provides a multi-model store based on multiple built-in data structures, supports replication, eviction policies, and automatic failover to enhance high availability and resiliency.
In this configuration, you can implement caching using Redis STRINGS in a key value schema to reduce the read latency from the original store (Kafka).
Motivation
In this example, the development team at a hypothetical company recently built a new inventory management and logistics system using Confluent Cloud on AWS.
New inventory is unloaded from trucks into storage, which initiates events that publish messages into various Kafka topics including the inventory topic. Several microservices support these new systems and subscribe to a number of Kafka topics depending on their functionality.
The ecommerce frontend team relies on the inventory microservice (which uses the inventory Kafka topic) to pull product descriptions as pages are browsed by customers. Page load times are the most crucial key performance indicator for the team. So, the ecommerce team explored adding a caching layer to lower the latency.
Figure 2 shows what the implementation looks like before adding a cache.
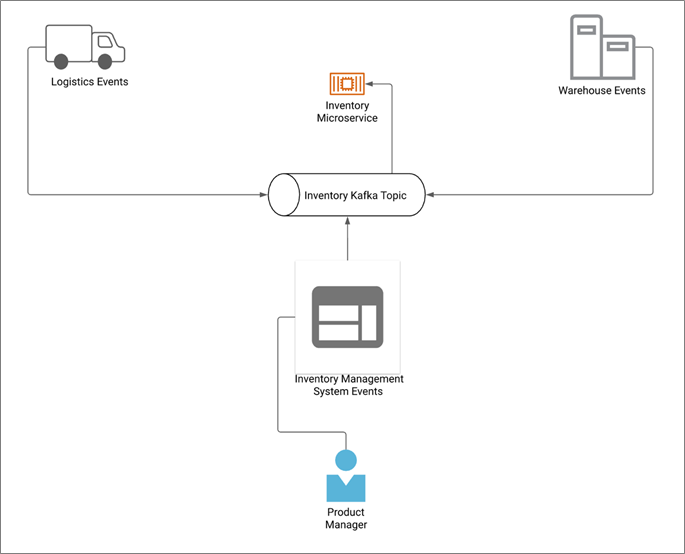
Figure 2 – Sample implementation of a Kafka topic with 20-30ms response.
Investigation
The hypothetical company’s development team explored Apache Kafka Streams and Confluent’s ksqlDB as a solution to the low latency requirement. However, due to the team’s relative inexperience with Kafka, they decided to implement a solution that was more in their comfort zone.
The operations team wanted to explore an easier way to get Kafka events into a familiar caching system. Although the team landed on Amazon ElastiCache for Redis to minimize their operational burden, they were still missing a critical piece to the puzzle.
After browsing and researching Confluent’s connectors, they realized they could set up the Confluent Redis sink connector to watch the inventory Kafka topic in Confluent Cloud and sink those events into their new Amazon ElastiCache cluster. This enabled the ecommerce team to pull product details in under a millisecond to satisfy their page load requirements.
They found the connector will update the cache in under 30ms. They were confident their customers will always pull data in near-real time, and you can see the enhanced implementation below.
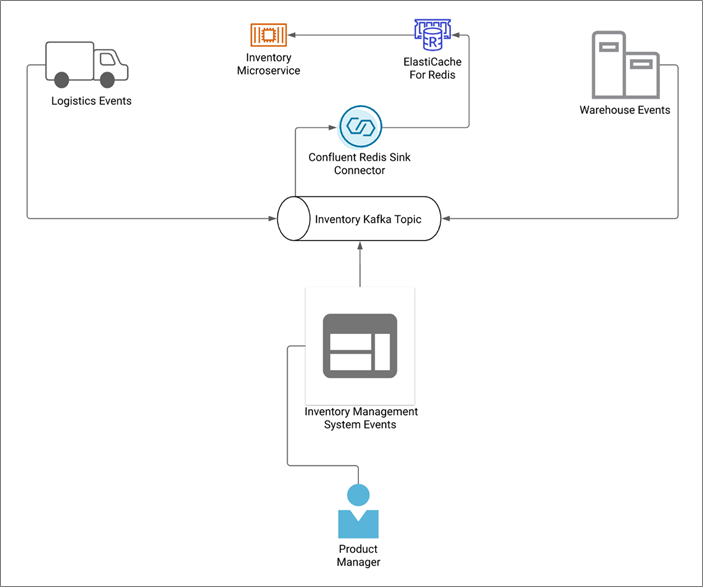
Figure 3 – Enhanced response near-real-time for a topic using Amazon ElastiCache.
Solution
With all of the pieces finally connected, we now have a real-time inventory system using fully managed Confluent Cloud. At the same time, we super-charged the ecommerce website inventory data reads by adding Amazon ElastiCache.
In the end, after implementing this solution the team learned about (1) some advanced access patterns to use in Redis in order to optimize their customers’ experiences; (2) key benefits beyond the performance and scalability gained by using ElastiCache for Redis; and (3) additional benefits gained by the flexibility that multiple data structures provide such as real-time scoring systems using SORTED SETS.
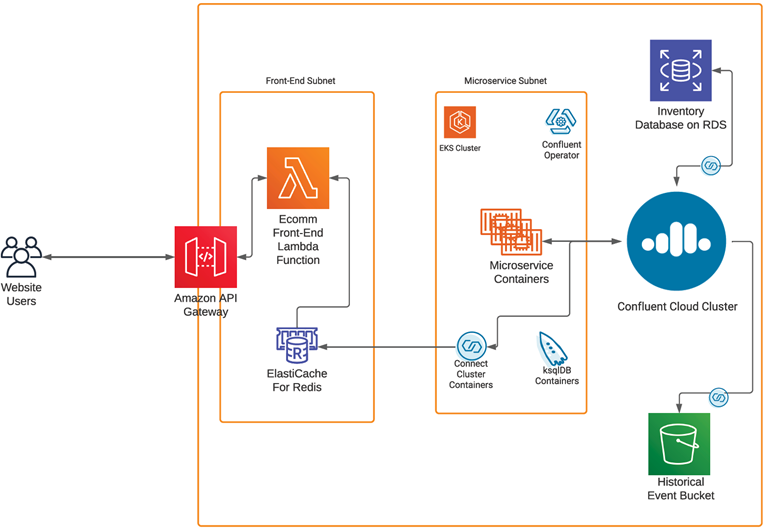
Figure 4 – Complete solution using AWS services and Confluent Cloud cluster.
Implementing the Solution
You can try out the data flow solutions solution by following below steps:
Prerequisites
- An active AWS account. If you don’t have one, create and activate a new AWS account.
- You need an Amazon Elastic Compute Cloud (Amazon EC2) key pair to log into virtual machines. If you don’t already have one you wish to use, here’s how to create a new one. In the following procedure, let’s name our key pair redis.pem and download it to your local machine to use in a later step.
- An active Confluent Cloud account. To get one, subscribe and sign up using Confluent Cloud on AWS Marketplace.
Signing up for Confluent Cloud
If you don’t already have an active Confluence Cloud account, navigate to AWS Marketplace and find Apache Kafka on Confluent Cloud – Pay As You Go. Select the Continue to Subscribe button. On the next page, review the pricing details and select the Subscribe button.
Next, to create an account, select the Set Up Your Account button on the pop-up window. This redirects you to a Confluent Cloud page. Provide the required details and create your account. Once created, you can use this account to carry out the remainder of this procedure.
Note that when you sign up, you get a monthly $200.00 USD credit for the first three months.
Creating a Confluent Cloud Kafka Cluster
Once you log in, you’ll see a pop-up asking few details regarding your Kafka experience and roles. Click Skip and go ahead.
On the next page, it will show options to configure your Confluent Cloud Kafka Cluster. Select Cluster Type as Basic and click Begin Configurations.
Select AWS and choose us-west-2 for Region, and then Single zone for the workshop. Click Continue.
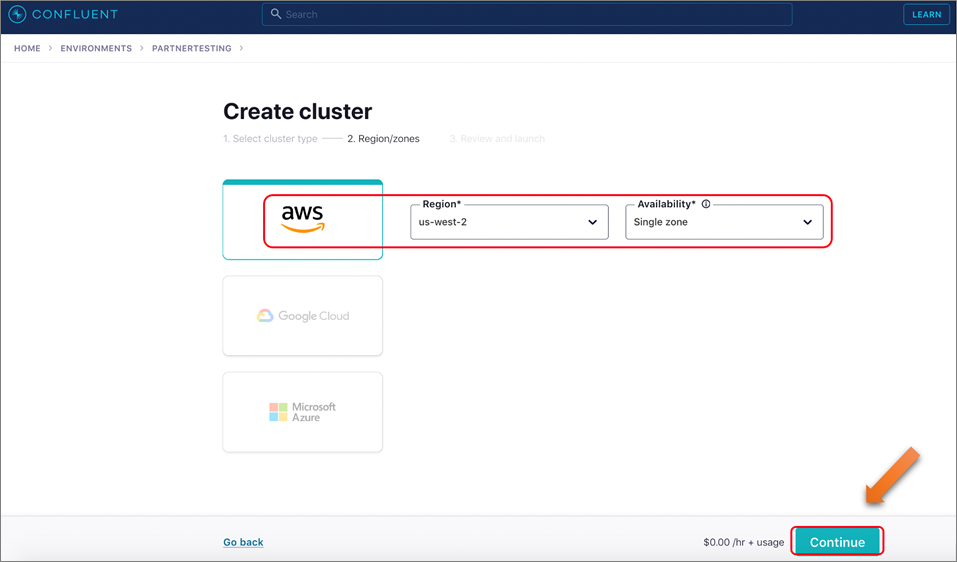
Figure 5 – Selecting AWS region and availability.
You will be asked to provide a credit card number to keep on file. Provide that information and click Review. Note that you’ll have a $200 USD free usage balance which will be more than enough to complete this workshop; hence, you won’t be charged.
Click Review and proceed to next page. Provide a name for your cluster, say “Confluent Workshop” and click Launch cluster. The cluster will be created instantly.
Creating Cluster API Keys
Navigate to the API Keys section and click on Create key, and then select the scope as Global and click Next.
On the next screen, you’ll see the keys generated for you. Ensure you save/copy the Key and Secret for use in the later sections. Provide a description, mark the check box and click Save.
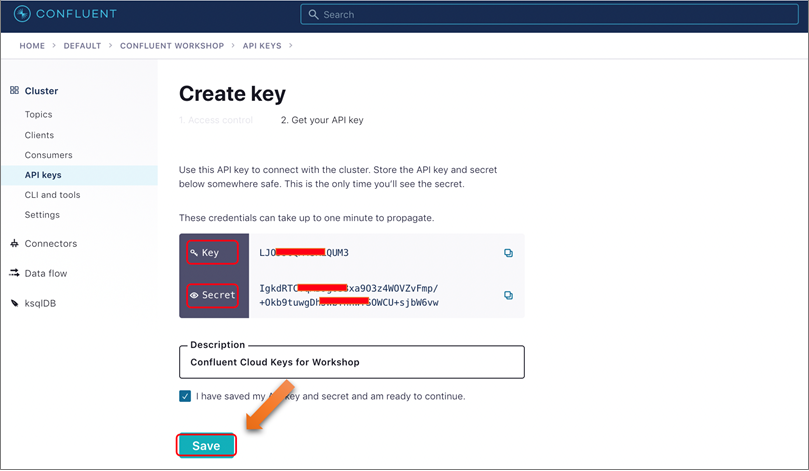
Figure 6 – Locate API key and secret to connect to your cluster.
While you’re in the Cluster Page, select Settings from left panel and note down/copy the Bootstrap server URL, as you will need it during next section.
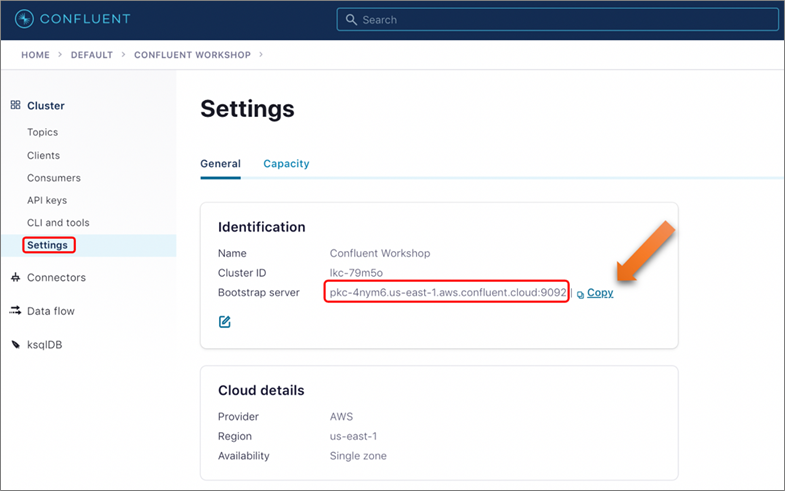
Figure 7 – Locate bootstrap server address.
Now you have Bootstrap server URL, API Key, and API Secret handy to proceed with the next section, where you’ll pass those as inputs for AWS CloudFormation deployments.
Creating a Kafka Topic
Navigate to the Confluent Cloud user interface (UI) and click Topic on the left navigation bar. On the Topics page, click Create Topic.
On the next screen, provide Topic name as “orders,” Number of partitions as 6, and then click Create with Defaults. The topic will be created in a few seconds.
Creating AWS Resources Needed for the Workshop
While logged into your AWS account, click on the Launch Stack button below, which will direct you to a CloudFormation create stack page.
![]()
Note that it’s very important to deploy CloudFormation and create AWS resources in the same region as Confluent Cloud Cluster for this workshop to function properly. Below, CloudFormation will launch in us-west-2.
In the appropriate sections, provide your API Key, API Secret, and Bootstrap server URL, and select the created “redis” key from the list (or of your choice). Acknowledge the capabilities and click Create Stack. For SSHLocation, use your private IP range or 0.0.0.0/0 based on how restrictive you want access to be.
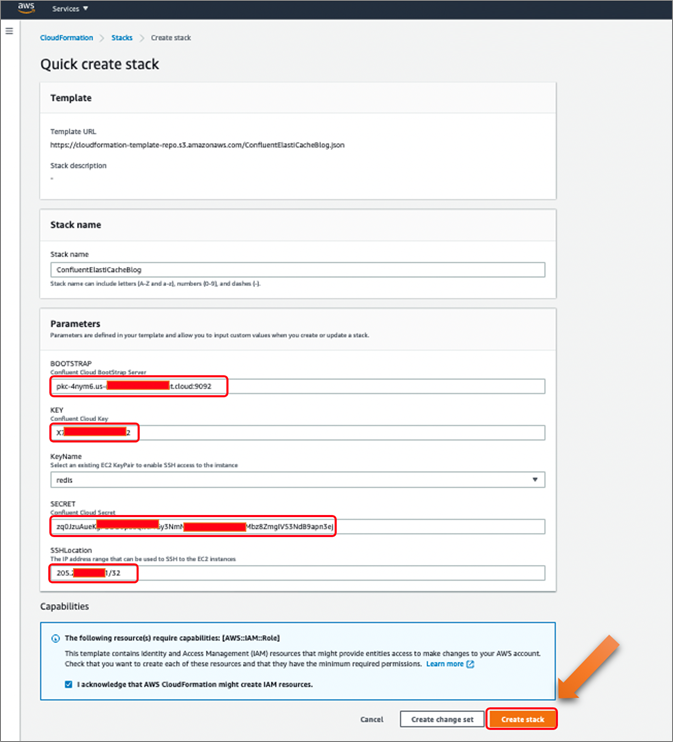
Figure 8 – Provide appropriate parameters for CloudFormation.
This starts creating the AWS resources required and takes about 10 minutes to complete the creation.
Once completed, navigate to the Outputs tab and make a note of EC2Instance and RedisEndpoint URLs, and keep them handy for using in following sections.
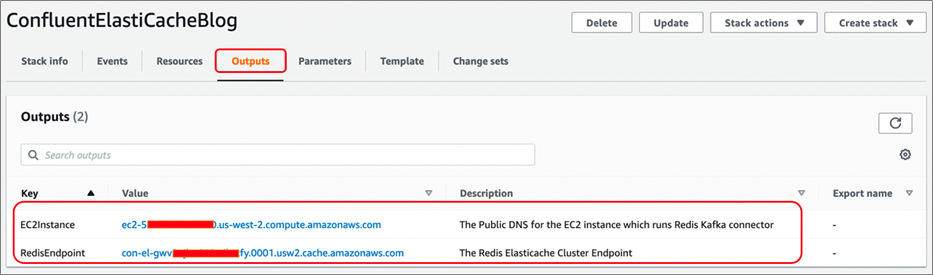
Figure 9 – Locate EC2 instance DNS and ElastiCache endpoint from CloudFormation output.
Once the CloudFormation completes, you have the resources to run the self-managed Redis connector launched. It’s configured to connect to your Confluent Cloud account and ready to ingest data into the ElastiCache for Redis cluster created.
Configuring DataGen Source Connector
Now, navigate back to the Confluent Cloud UI and click on Connector on the left panel, filter for “datagen,” and click on the Datagen Source connector button.
On the next page, provide the following details:
| Name | DataGen |
| Kafka API Key | <Your Kafka API Key> |
| Kafka API Secret | <Your Kafka API Secret> |
| Topic name | orders |
| Output message format | JSON |
| Quickstart | ORDERS |
| Max interval between messages | 1,000 |
| Tasks | 1 |
Click on Next, and then review the details provided. Click the Launch button to proceed. It will take few minutes for the connector to complete provisioning and start.
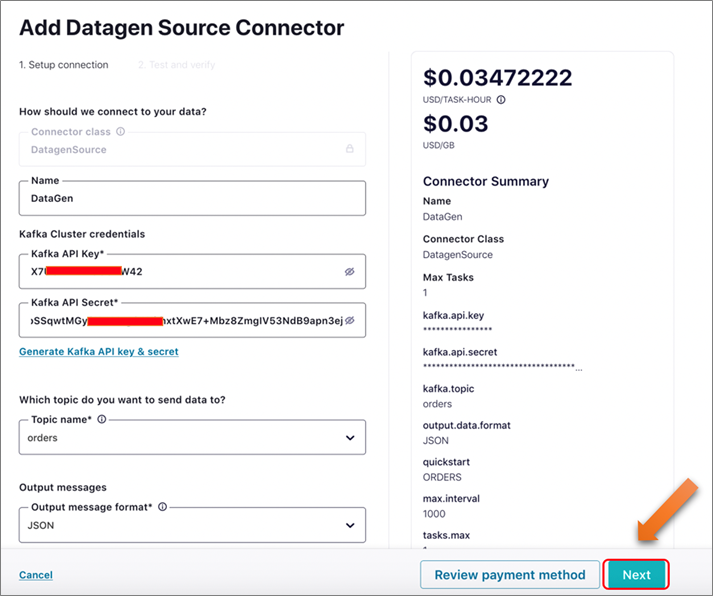
Figure 10 – Create DataGen source connector by providing required parameters.
Once the connector starts, messages will start flowing into the topic “orders” from the DataGen source. They will flow into the self-managed Redis connector spun up as part of the CloudFormation template, and eventually into ElastiCache for Redis cluster.
Connecting to ElastiCache Redis to Verify Data Availability
As part of the CloudFormation template, we installed Redis Visualizer on the Amazon EC2 node running the Kafka Redis connector. Now, let’s establish a tunnel to the node and visualize data availability.
Navigate to a terminal and execute the following commands:
Below is an example of how the commands should be executed in order to establish port forwarding. Make sure you successfully login without any errors to ensure port forwarding worked.
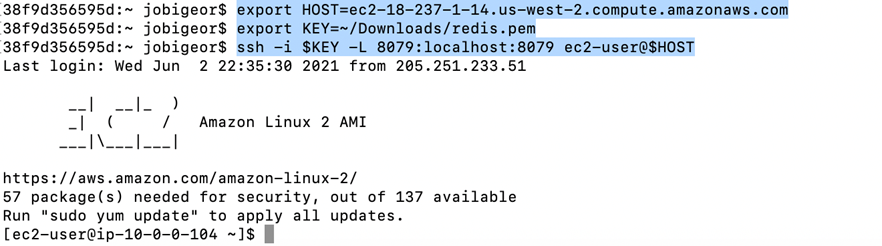
Figure 11 – Commands to establish port forwarding from localhost.
Once you execute the command, it establishes a port forwarding to connect and access Redis Visualizer running on port 8097 in the EC2 instance on your local machine.
Access http://localhost:8079/ and provide your RedisEndpoint captured from the CloudFormation output in the Host section, and click Analyze to leave everything default. You should be able to verify the data availability as below.
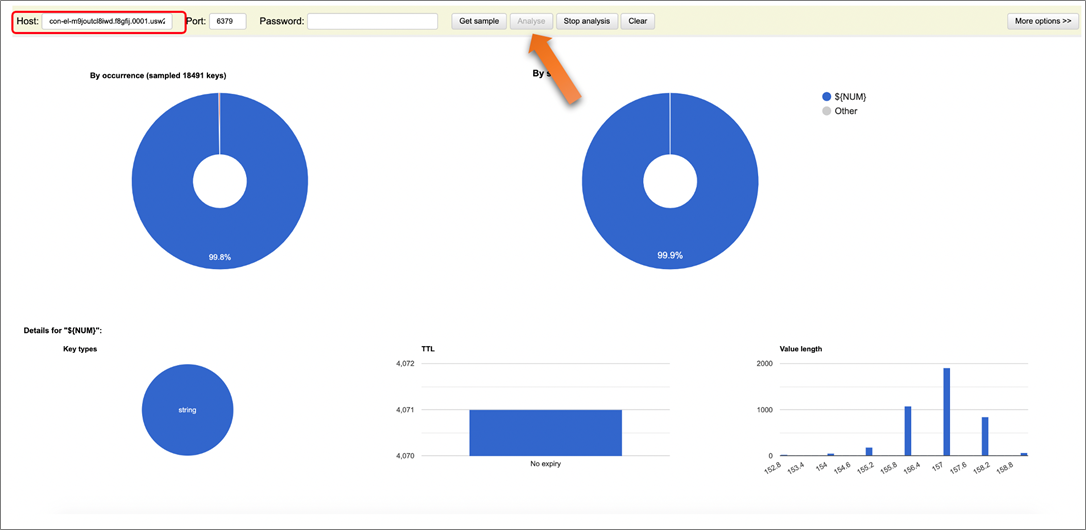
Figure 12 – Redis Visualizer helping to verify the data availability.
You have completed implementing this solution as described in this post. The solution consists of a DataGen connector publishing data into a topic named “orders” while a Kafka connect Redis-Connector running on an EC2 instance consumes the messages and ingests it into Redis for low latency use cases.
We also used Redis Visualizer to verify data availability rather than using command line utility.
Now, we can also query the contents of each order by performing a GET operations in ElastiCache for Redis, specifically GET orders:18, and the contents will be a JSON payload as follows:
Cleanup
In order to avoid incurring additional charges caused by resources created as part of this post, make sure you delete the AWS CloudFormation stack. Go to the CloudFormation console and in Stacks you can delete the stack that was created.
Also on Confluent Cloud, make sure you delete the topics and connectors running followed by the cluster itself.
Additional Benefits
Now that we have the power of Amazon ElastiCache for Redis in our hands, we can start exploring other use cases beyond caching that will be a good fit for these use cases. For example, having a real-time count of the number of products in the inventory for a given SKU, ordered by store.
We will be using the built-in SORTED SET data structure provided by Redis.
Conclusion
In this post, we outlined a hypothetical use case that required both durability of events and ultra-low latency reads. Ultimately, we satisfied our hard requirements using Amazon ElastiCache for Redis to get sub-millisecond reads and Confluent Cloud for persistence. Both are easy to use and fully managed on AWS.
To try this solution using ElastiCache for Redis, sign up for Confluent Cloud in AWS Marketplace. Once you’ve logged into the Confluent Cloud UI, go to Billing & payment > Payment details & contracts > + Promo code. Use CL60BLOG to get an additional $60 credit for Confluent Cloud usage.
.

.
Confluent – AWS Partner Spotlight
Confluent is an AWS ISV Partner that provides a serverless way to help you build event-driven applications that ingest real- or near real-time data into cloud data warehouses.
Contact Confluent | Partner Overview | AWS Marketplace
*Already worked with Confluent? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.