AWS Big Data Blog
Category: AWS Glue

Copy and mask PII between Amazon RDS databases using visual ETL jobs in AWS Glue Studio
In this post, I’ll walk you through how to copy data from one Amazon Relational Database Service (Amazon RDS) for PostgreSQL database to another, while scrubbing PII along the way using AWS Glue. You will learn how to prepare a multi-account environment to access the databases from AWS Glue, and how to model an ETL data flow that automatically masks PII as part of the transfer process, so that no sensitive information will be copied to the target database in its original form.

Unlock scalable analytics with a secure connectivity pattern in AWS Glue to read from or write to Snowflake
In today’s data-driven world, the ability to seamlessly integrate and utilize diverse data sources is critical for gaining actionable insights and driving innovation. As organizations increasingly rely on data stored across various platforms, such as Snowflake, Amazon Simple Storage Service (Amazon S3), and various software as a service (SaaS) applications, the challenge of bringing these […]

Implement data quality checks on Amazon Redshift data assets and integrate with Amazon DataZone
In this post, we show how to capture the data quality metrics for data assets produced in Amazon Redshift. With Amazon DataZone, the data owner can directly import the technical metadata of a Redshift database table and views to the Amazon DataZone project’s inventory. As these data assets gets imported into Amazon DataZone, it bypasses the AWS Glue Data Catalog, creating a gap in data quality integration. This post proposes a solution to enrich the Amazon Redshift data asset with data quality scores and KPI metrics.
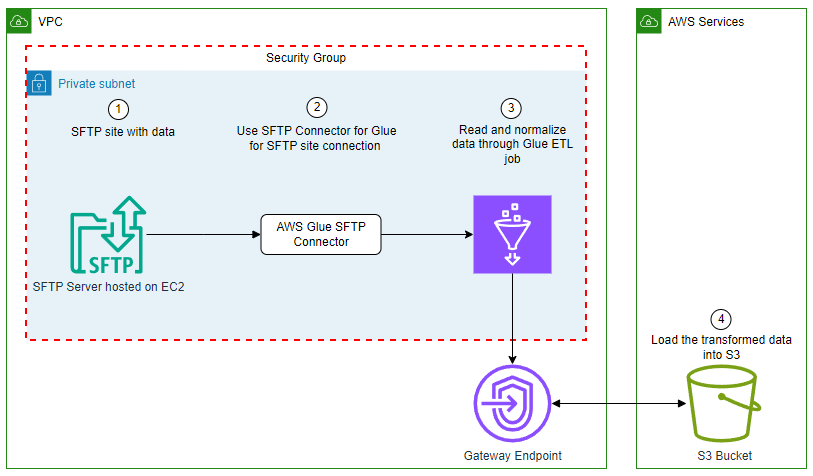
Use AWS Glue to streamline SFTP data processing
In this blog post, we explore how to use the SFTP Connector for AWS Glue from the AWS Marketplace to efficiently process data from Secure File Transfer Protocol (SFTP) servers into Amazon Simple Storage Service (Amazon S3), further empowering your data analytics and insights.

Query AWS Glue Data Catalog views using Amazon Athena and Amazon Redshift
Glue Data Catalog views is a new feature of the AWS Glue Data Catalog that customers can use to create a common view schema and single metadata container that can hold view-definitions in different dialects that can be used across engines such as Amazon Redshift and Amazon Athena. In this blog post, we will show how you can define and query a Data Catalog view on top of open source table formats such as Iceberg across Athena and Amazon Redshift. We will also show you the configurations needed to restrict access to the underlying database and tables. To follow along, we have provided an AWS CloudFormation template.

Introducing AWS Glue Data Quality anomaly detection
We are excited to announce the general availability of anomaly detection capabilities in AWS Glue Data Quality. In this post, we demonstrate how this feature works with an example. We provide an AWS Cloud Formation template to deploy this setup and experiment with this feature.

AWS Glue mutual TLS authentication for Amazon MSK
In today’s landscape, data streams continuously from countless sources such as social media interactions to Internet of Things (IoT) device readings. This torrent of real-time information presents both a challenge and an opportunity for businesses. To harness the power of this data effectively, organizations need robust systems for ingesting, processing, and analyzing streaming data at […]

Set up cross-account AWS Glue Data Catalog access using AWS Lake Formation and AWS IAM Identity Center with Amazon Redshift and Amazon QuickSight
In this post, we cover how to enable trusted identity propagation with AWS IAM Identity Center, Amazon Redshift, and AWS Lake Formation residing on separate AWS accounts and set up cross-account sharing of an S3 data lake for enterprise identities using AWS Lake Formation to enable analytics using Amazon Redshift. Then we use Amazon QuickSight to build insights using Redshift tables as our data source.

Create a customizable cross-company log lake for compliance, Part I: Business Background
As builders, sometimes you want to dissect a customer experience, find problems, and figure out ways to make it better. That means going a layer down to mix and match primitives together to get more comprehensive features and more customization, flexibility, and freedom. In this post, we introduce Log Lake, a do-it-yourself data lake based on logs from CloudWatch and AWS CloudTrail.

Synchronize data lakes with CDC-based UPSERT using open table format, AWS Glue, and Amazon MSK
The post illustrates the construction of a comprehensive CDC system, enabling the processing of CDC data sourced from Amazon Relational Database Service (Amazon RDS) for MySQL. Initially, we’re creating a raw data lake of all modified records in the database in near real time using Amazon MSK and writing to Amazon S3 as raw data. Later, we use an AWS Glue exchange, transform, and load (ETL) job for batch processing of CDC data from the S3 raw data lake.