AWS Big Data Blog
Category: AWS Glue
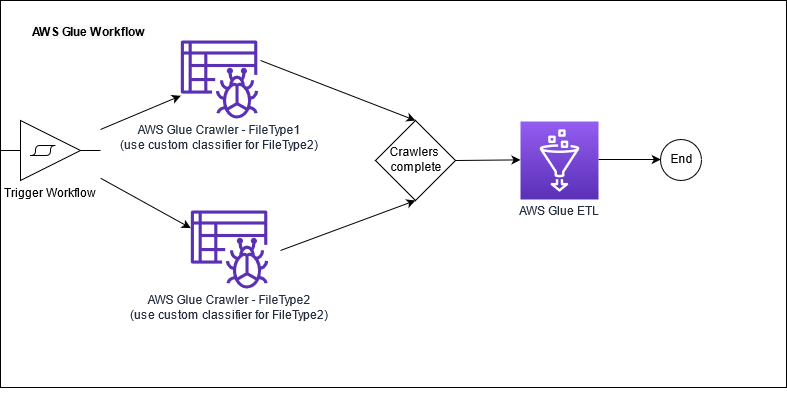
Orchestrate an ETL pipeline using AWS Glue workflows, triggers, and crawlers with custom classifiers
Extract, transform, and load (ETL) orchestration is a common mechanism for building big data pipelines. Orchestration for parallel ETL processing requires the use of multiple tools to perform a variety of operations. To simplify the orchestration, you can use AWS Glue workflows. This post demonstrates how to accomplish parallel ETL orchestration using AWS Glue workflows […]

Create a serverless event-driven workflow to ingest and process Microsoft data with AWS Glue and Amazon EventBridge
Microsoft SharePoint is a document management system for storing files, organizing documents, and sharing and editing documents in collaboration with others. Your organization may want to ingest SharePoint data into your data lake, combine the SharePoint data with other data that’s available in the data lake, and use it for reporting and analytics purposes. AWS […]

Introducing Amazon S3 shuffle in AWS Glue
Nov 2022: Newer version of the product is now available to be used for this post. AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning (ML), and application development. In AWS Glue, you can use Apache Spark, which is an open-source, distributed processing […]

Now Available: Updated guidance on the Data Analytics Lens for AWS Well-Architected Framework
Nearly all businesses today require some form of data analytics processing, from auditing user access to generating sales reports. For all your analytics needs, the Data Analytics Lens for AWS Well-Architected Framework provides prescriptive guidance to help you assess your workloads and identify best practices aligned to the AWS Well-Architected Pillars: Operational Excellence, Security, Reliability, […]

Accelerate large-scale data migration validation using PyDeequ
March 2023: You can now use AWS Glue Data Quality to measure and manage the quality of your data. AWS Glue Data Quality is built on DeeQu and it offers a simplified user experience for customers who want to this open-source package. Refer to the blog and documentation for additional details. Many enterprises are migrating their […]

Stream data from relational databases to Amazon Redshift with upserts using AWS Glue streaming jobs
Traditionally, read replicas of relational databases are often used as a data source for non-online transactions of web applications such as reporting, business analysis, ad hoc queries, operational excellence, and customer services. Due to the exponential growth of data volume, it became common practice to replace such read replicas with data warehouses or data lakes […]

Build operational metrics for your enterprise AWS Glue Data Catalog at scale
Over the last several years, enterprises have accumulated massive amounts of data. Data volumes have increased at an unprecedented rate, exploding from terabytes to petabytes and sometimes exabytes of data. Increasingly, many enterprises are building highly scalable, available, secure, and flexible data lakes on AWS that can handle extremely large datasets. After data lakes are […]

How Amazon Transportation Service enabled near-real-time event analytics at petabyte scale using AWS Glue with Apache Hudi
This post is co-written with Madhavan Sriram and Diego Menin from Amazon Transportation Services (ATS). The transportation and logistics industry covers a wide range of services, such as multi-modal transportation, warehousing, fulfillment, freight forwarding, and delivery. At Amazon Transportation Service (ATS), the lifecycle of the shipment is digitally tracked and appended to tens of tracking […]

Simplify data integration pipeline development using AWS Glue custom blueprints
June 2023: This post was reviewed and updated for accuracy. August 2021: AWS Glue custom blueprints are now generally available. Please visit https://docs.aws.amazon.com/glue/latest/dg/blueprints-overview.html to learn more. Organizations spend significant time developing and maintaining data integration pipelines that hydrate data warehouses, data lakes, and lake houses. As data volume increases, data engineering teams struggle to keep up with […]

Use Amazon Athena and Amazon QuickSight in a cross-account environment
This blog post was last reviewed and updated in June 2025. Many AWS customers use a multi-account strategy to host applications for different departments within the same company. However, you might deploy services like Amazon QuickSight using a single-account approach, which raises challenges when you need to use QuickSight in combination with Amazon Athena to […]