AWS Big Data Blog
Category: Database

Orchestrate Amazon Redshift-Based ETL workflows with AWS Step Functions and AWS Glue
In this post, I show how to use AWS Step Functions and AWS Glue Python Shell to orchestrate tasks for those Amazon Redshift-based ETL workflows in a completely serverless fashion. AWS Glue Python Shell is a Python runtime environment for running small to medium-sized ETL tasks, such as submitting SQL queries and waiting for a response. Step Functions lets you coordinate multiple AWS services into workflows so you can easily run and monitor a series of ETL tasks. Both AWS Glue Python Shell and Step Functions are serverless, allowing you to automatically run and scale them in response to events you define, rather than requiring you to provision, scale, and manage servers.

Protect and Audit PII data in Amazon Redshift with DataSunrise Security
This post focuses on active security for Amazon Redshift, in particular DataSunrise’s capabilities for masking and access control of personally identifiable information (PII), which you can back with DataSunrise’s passive security offerings such as auditing access of sensitive information. This post discusses DataSunrise security for Amazon Redshift, how it works, and how to get started.

Automate Amazon Redshift cluster creation using AWS CloudFormation
In this post, I explain how to automate the deployment of an Amazon Redshift cluster in an AWS account. AWS best practices for security and high availability drive the cluster’s configuration, and you can create it quickly by using AWS CloudFormation. I walk you through a set of sample CloudFormation templates, which you can customize as per your needs.
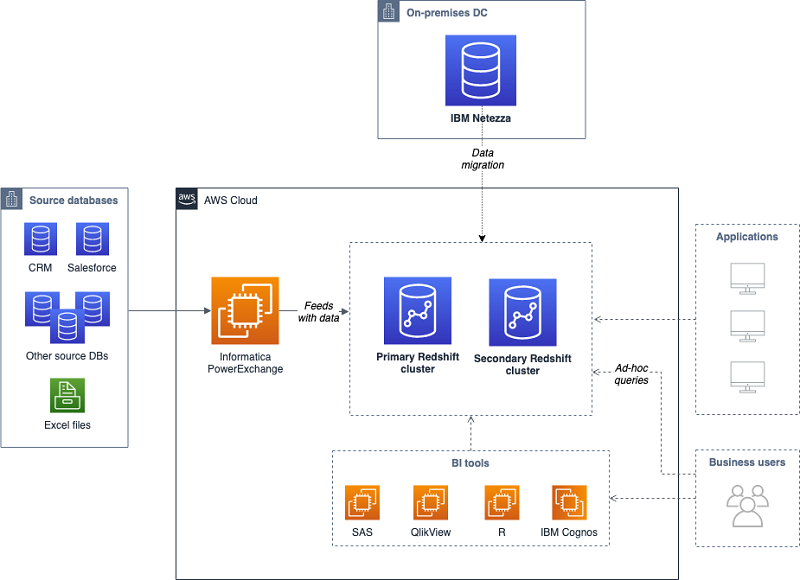
How to migrate a large data warehouse from IBM Netezza to Amazon Redshift with no downtime
In this article, we explain how this customer performed a large-scale data warehouse migration from IBM Netezza to Amazon Redshift without downtime, by following a thoroughly planned migration process, and leveraging AWS Schema Conversion Tool (SCT) and Amazon Redshift best practices.
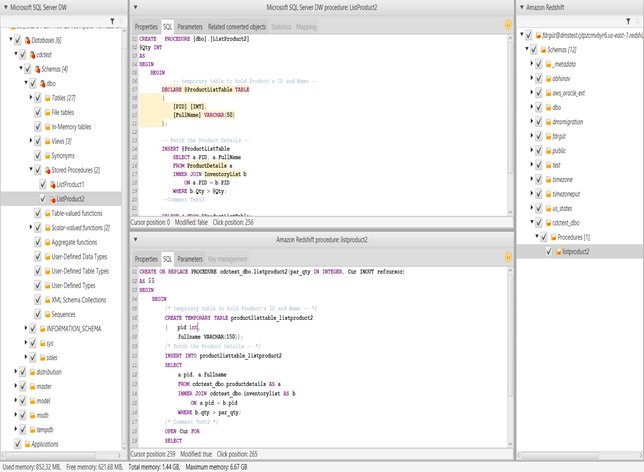
Bringing your stored procedures to Amazon Redshift
Amazon always works backwards from the customer’s needs. Customers have made strong requests that they want stored procedures in Amazon Redshift, to make it easier to migrate their existing workloads from legacy, on-premises data warehouses.
With that primary goal in mind, AWS chose to implement PL/pqSQL stored procedure to maximize compatibility with existing procedures and simplify migrations. In this post, we discuss how and where to use stored procedures to improve operational efficiency and security. We also explain how to use stored procedures with AWS Schema Conversion Tool.

Load ongoing data lake changes with AWS DMS and AWS Glue
April 2024: This post was reviewed for accuracy. July 2022: This blog post was reviewed and updated with an additional AWS CloudFormation stack to deploy MySQL database. Building a data lake on Amazon S3 provides an organization with countless benefits. It allows you to access diverse data sources, determine unique relationships, build AI/ML models to […]
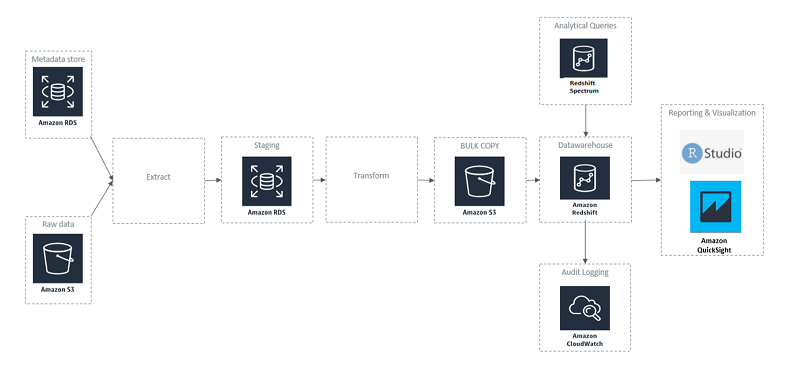
How 3M Health Information Systems built a healthcare data reporting tool with Amazon Redshift
After reviewing many solutions, 3M HIS chose Amazon Redshift as the appropriate data warehouse solution. We concluded Amazon Redshift met our needs; a fast, fully managed, petabyte-scale data warehouse solution that uses columnar storage to minimize I/O, provides high data compression rates, and offers fast performance. We quickly spun up a cluster in our development environment, built out the dimensional model, loaded data, and made it available to perform benchmarking and testing of the user data. An extract, transform, load (ETL) tool was used to process and load the data from various sources into Amazon Redshift.
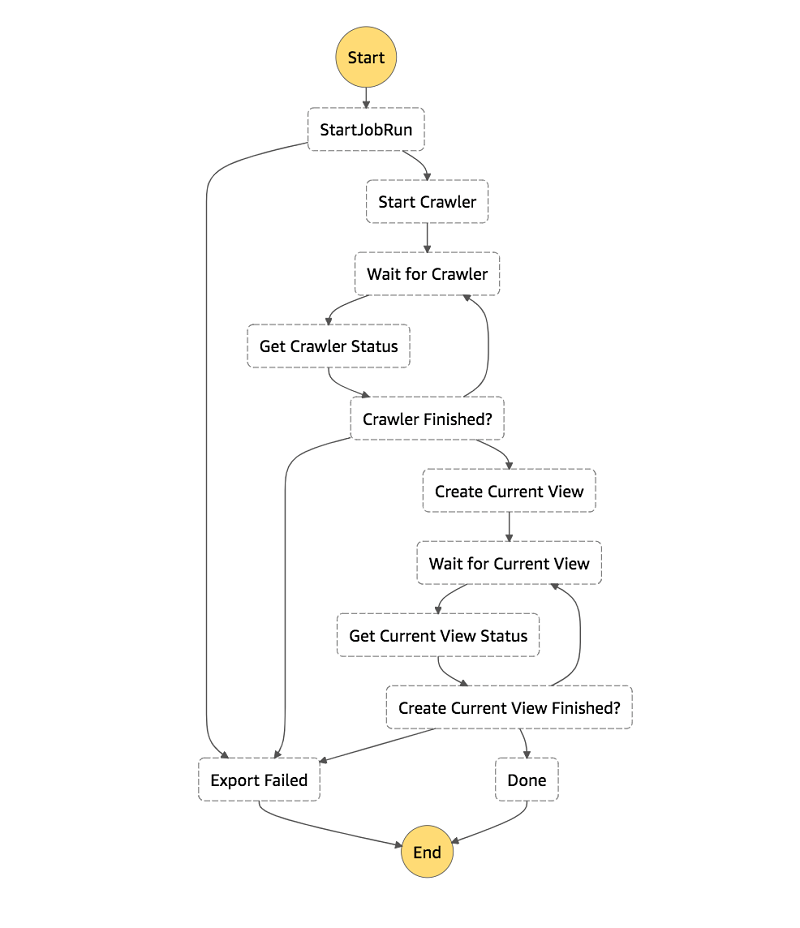
How to export an Amazon DynamoDB table to Amazon S3 using AWS Step Functions and AWS Glue
In this post, I show you how to use AWS Glue’s DynamoDB integration and AWS Step Functions to create a workflow to export your DynamoDB tables to S3 in Parquet. I also show how to create an Athena view for each table’s latest snapshot, giving you a consistent view of your DynamoDB table exports.

Query your Amazon Redshift cluster with the new Query Editor
Data warehousing is a critical component for analyzing and extracting actionable insights from your data. Amazon Redshift is a fast, scalable data warehouse that makes it cost-effective to analyze all of your data across your data warehouse and data lake. The Amazon Redshift console recently launched the Query Editor. The Query Editor is an in-browser […]

How to enable cross-account Amazon Redshift COPY and Redshift Spectrum query for AWS KMS–encrypted data in Amazon S3
This post shows a step-by-step walkthrough of how to set up a cross-account Amazon Redshift COPY and Spectrum query using a sample dataset in Amazon S3. The sample dataset is encrypted at rest using AWS KMS-managed keys (SSE-KMS). About AWS Key Management Service (AWS KMS) With AWS Key Management Service (AWS KMS), you can have […]