AWS Big Data Blog
Category: Technical How-to
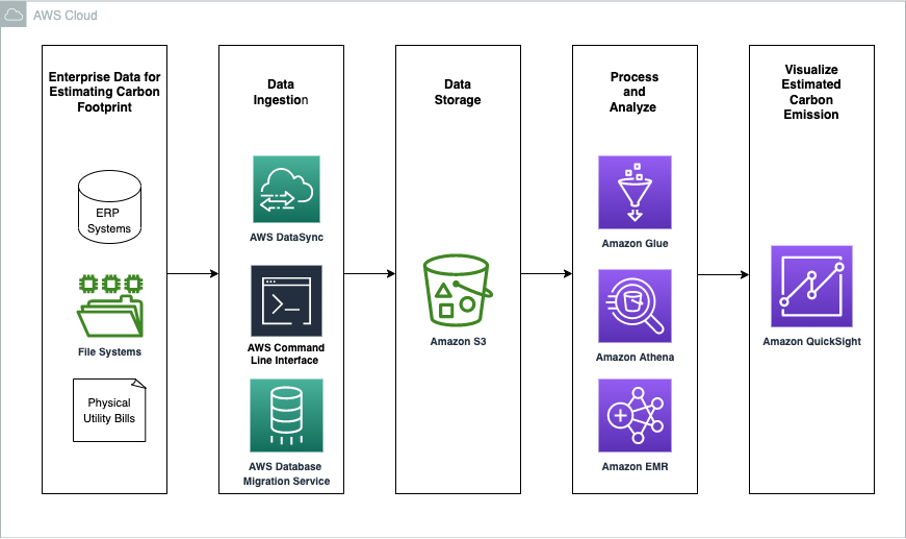
Estimating Scope 1 Carbon Footprint with Amazon Athena
Today, more than 400 organizations have signed The Climate Pledge, a commitment to reach net-zero carbon by 2040. Some of the drivers that lead to setting explicit climate goals include customer demand, current and anticipated government relations, employee demand, investor demand, and sustainability as a competitive advantage. AWS customers are increasingly interested in ways to […]

How FIS ingests and searches vector data for quick ticket resolution with Amazon OpenSearch Service
This post was co-written by Sheel Saket, Senior Data Science Manager at FIS, and Rupesh Tiwari, Senior Architect at Amazon Web Services. Do you ever find yourself grappling with multiple defect logging mechanisms, scattered project management tools, and fragmented software development platforms? Have you experienced the frustration of lacking a unified view, hindering your ability […]

Amazon Kinesis Data Streams on-demand capacity mode now scales up to 1 GB/second ingest capacity
Amazon Kinesis Data Streams is a serverless data streaming service that makes it easy to capture, process, and store streaming data at any scale. As customers collect and stream more types of data, they have asked for simpler, elastic data streams that can handle variable and unpredictable data traffic. In November 2021, Amazon Web Services […]

Empower your Jira data in a data lake with Amazon AppFlow and AWS Glue
In the world of software engineering and development, organizations use project management tools like Atlassian Jira Cloud. Managing projects with Jira leads to rich datasets, which can provide historical and predictive insights about project and development efforts. Although Jira Cloud provides reporting capability, loading this data into a data lake will facilitate enrichment with other […]

Migrate your existing SQL-based ETL workload to an AWS serverless ETL infrastructure using AWS Glue
Data has become an integral part of most companies, and the complexity of data processing is increasing rapidly with the exponential growth in the amount and variety of data. Data engineering teams are faced with the following challenges: Manipulating data to make it consumable by business users Building and improving extract, transform, and load (ETL) […]

Extend your data mesh with Amazon Athena and federated views
Amazon Athena is a serverless, interactive analytics service built on the Trino, PrestoDB, and Apache Spark open-source frameworks. You can use Athena to run SQL queries on petabytes of data stored on Amazon Simple Storage Service (Amazon S3) in widely used formats such as Parquet and open-table formats like Apache Iceberg, Apache Hudi, and Delta […]

Use AWS Glue DataBrew recipes in your AWS Glue Studio visual ETL jobs
AWS Glue Studio is now integrated with AWS Glue DataBrew. AWS Glue Studio is a graphical interface that makes it easy to create, run, and monitor extract, transform, and load (ETL) jobs in AWS Glue. DataBrew is a visual data preparation tool that enables you to clean and normalize data without writing any code. The […]

Dimensional modeling in Amazon Redshift
Amazon Redshift is a fully managed and petabyte-scale cloud data warehouse that is used by tens of thousands of customers to process exabytes of data every day to power their analytics workload. You can structure your data, measure business processes, and get valuable insights quickly can be done by using a dimensional model. Amazon Redshift […]

Migrate data from Google Cloud Storage to Amazon S3 using AWS Glue
Today, we are pleased to announce a new AWS Glue connector for Google Cloud Storage that allows you to move data bi-directionally between Google Cloud Storage and Amazon Simple Storage Service (Amazon S3). In this post, we go over how the new connector works, introduce the connector’s functions, and provide you with key steps to set it up. We provide you with prerequisites, share how to subscribe to this connector in AWS Marketplace, and describe how to create and run AWS Glue for Apache Spark jobs with it.

Automate secure access to Amazon MWAA environments using existing OpenID Connect single-sign-on authentication and authorization
Customers use Amazon Managed Workflows for Apache Airflow (Amazon MWAA) to run Apache Airflow at scale in the cloud. They want to use their existing login solutions developed using OpenID Connect (OIDC) providers with Amazon MWAA; this allows them to provide a uniform authentication and single sign-on (SSO) experience using their adopted identity providers (IdP) […]