AWS Big Data Blog
Category: Technical How-to

Multi-tenancy Apache Kafka clusters in Amazon MSK with IAM access control and Kafka quotas – Part 2
Kafka quotas are integral to multi-tenant Kafka clusters. They prevent Kafka cluster performance from being negatively affected by poorly behaved applications overconsuming cluster resources. Furthermore, they enable the central streaming data platform to be operated as a multi-tenant platform and used by downstream and upstream applications across multiple business lines. Kafka supports two types of quotas: […]

Optimize queries using dataset parameters in Amazon QuickSight
Amazon QuickSight powers data-driven organizations with unified business intelligence (BI) at hyperscale. With QuickSight, all users can meet varying analytic needs from the same source of truth through modern interactive dashboards, paginated reports, embedded analytics and natural language queries. We have introduced dataset parameters, a new kind of parameter in QuickSight that can help you […]

Best practices for enabling business users to answer questions about data using natural language in Amazon QuickSight
In this post, we explain how you can enable business users to ask and answer questions about data using their everyday business language by using the Amazon QuickSight natural language query function, Amazon QuickSight Q. QuickSight is a unified BI service providing modern interactive dashboards, natural language querying, paginated reports, machine learning (ML) insights, and […]

Enable data collaboration among public health agencies with AWS Clean Rooms – Part 1
In this post, we show how you can use AWS Clean Rooms to enable data collaboration between public health agencies. Public health governmental agencies need to understand trends related to a variety of health conditions and care across populations in order to create policies and treatments with the goal of improving the well-being of the […]
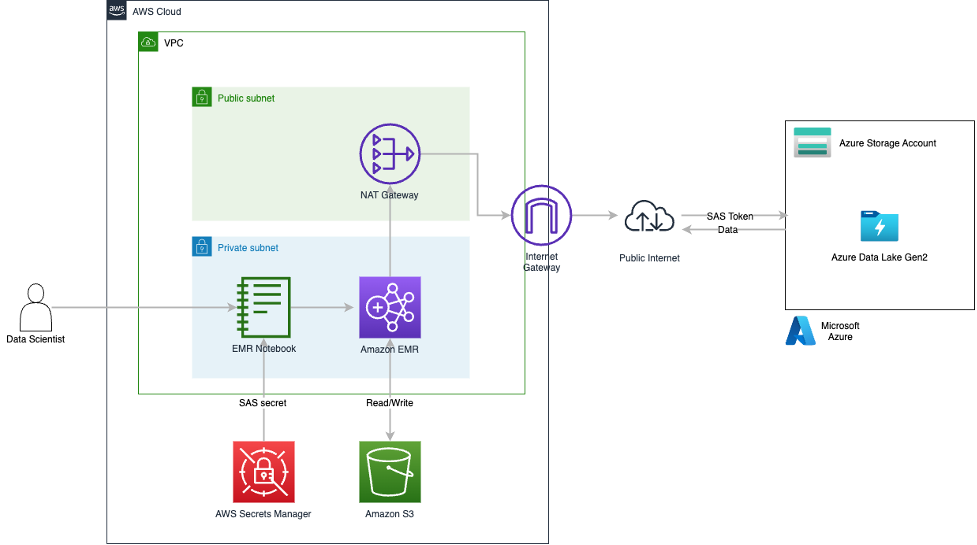
Enable remote reads from Azure ADLS with SAS tokens using Spark in Amazon EMR
Organizations use data from many sources to understand, analyze, and grow their business. These data sources are often spread across various public cloud providers. Enterprises may also expand their footprint by mergers and acquisitions, and during such events they often end up with data spread across different public cloud providers. These scenarios can create the […]

Federate Amazon QuickSight access with open-source identity provider Keycloak
Amazon QuickSight is a scalable, serverless, embeddable, machine learning (ML) powered business intelligence (BI) service built for the cloud that supports identity federation in both Standard and Enterprise editions. Organizations are working toward centralizing their identity and access strategy across all their applications, including on-premises and third-party. Many organizations use Keycloak as their identity provider […]

AWS Glue streaming application to process Amazon MSK data using AWS Glue Schema Registry
Organizations across the world are increasingly relying on streaming data, and there is a growing need for real-time data analytics, considering the growing velocity and volume of data being collected. This data can come from a diverse range of sources, including Internet of Things (IoT) devices, user applications, and logging and telemetry information from applications, […]
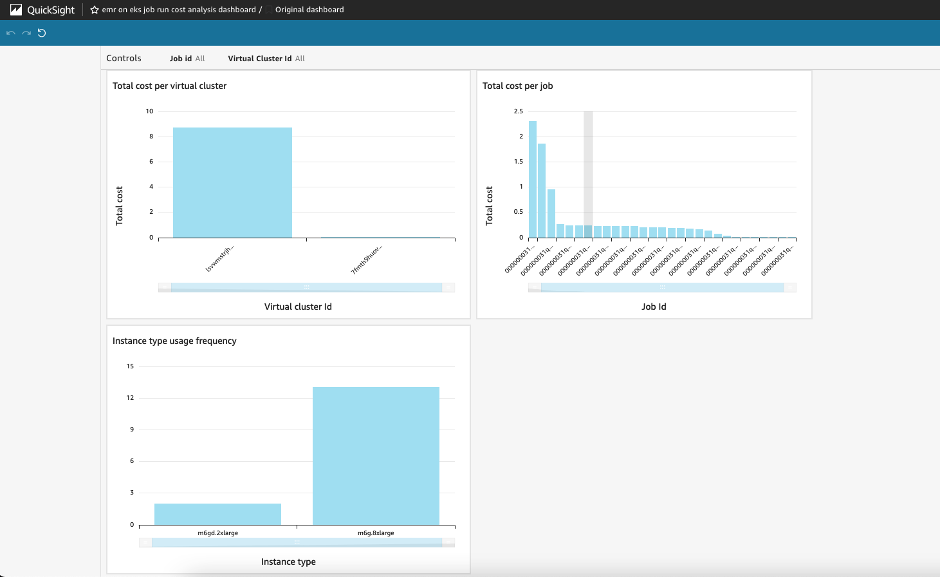
Cost monitoring for Amazon EMR on Amazon EKS
Amazon EMR is the industry-leading cloud big data solution, providing a collection of open-source frameworks such as Spark, Hive, Hudi, and Presto, fully managed and with per-second billing. Amazon EMR on Amazon EKS is a deployment option allowing you to deploy Amazon EMR on the same Amazon Elastic Kubernetes Service (Amazon EKS) clusters that is […]

Implement alerts in Amazon OpenSearch Service with PagerDuty
In today’s fast-paced digital world, businesses rely heavily on their data to make informed decisions. This data is often stored and analyzed using various tools, such as Amazon OpenSearch Service, a powerful search and analytics service offered by AWS. OpenSearch Service provides real-time insights into your data to support use cases like interactive log analytics, […]

How Cargotec uses metadata replication to enable cross-account data sharing
This is a guest blog post co-written with Sumesh M R from Cargotec and Tero Karttunen from Knowit Finland. Cargotec (Nasdaq Helsinki: CGCBV) is a Finnish company that specializes in cargo handling solutions and services. They are headquartered in Helsinki, Finland, and operates globally in over 100 countries. With its leading cargo handling solutions and […]