AWS Big Data Blog
Category: Technical How-to

Stream Amazon EMR on EKS logs to third-party providers like Splunk, Amazon OpenSearch Service, or other log aggregators
Spark jobs running on Amazon EMR on EKS generate logs that are very useful in identifying issues with Spark processes and also as a way to see Spark outputs. You can access these logs from a variety of sources. On the Amazon EMR virtual cluster console, you can access logs from the Spark History UI. […]

Use Amazon Athena parameterized queries to provide data as a service
Amazon Athena now provides you more flexibility to use parameterized queries, and we recommend you use them as the best practice for your Athena queries moving forward so you benefit from the security, reusability, and simplicity they offer. In a previous post, Improve reusability and security using Amazon Athena parameterized queries, we explained how parameterized […]

Accelerate machine learning with AWS Data Exchange and Amazon Redshift ML
July 2023: This post was reviewed for accuracy and updated. Amazon Redshift ML makes it easy for SQL users to create, train, and deploy ML models using familiar SQL commands. Redshift ML allows you to use your data in Amazon Redshift with Amazon SageMaker, a fully managed ML service, without requiring you to become an […]

Analyze logs with Dynatrace Davis AI Engine using Amazon Kinesis Data Firehose HTTP endpoint delivery
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. This blog post is co-authored with Erick Leon, Sr. Technical Alliance Manager from Dynatrace. Amazon Kinesis Data Firehose is the easiest way to reliably load streaming data into data lakes, data stores, and […]

Sink Amazon Kinesis Data Analytics Apache Flink output to Amazon Keyspaces using Apache Cassandra Connector
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Amazon Keyspaces (for Apache Cassandra) is a scalable, highly available, and managed Apache Cassandra–compatible database service. With Amazon Keyspaces you don’t have to provision, patch, or manage […]

Build an Apache Iceberg data lake using Amazon Athena, Amazon EMR, and AWS Glue
March 2024: This post was reviewed and updated for accuracy. Most businesses store their critical data in a data lake, where you can bring data from various sources to a centralized storage. The data is processed by specialized big data compute engines, such as Amazon Athena for interactive queries, Amazon EMR for Apache Spark applications, […]
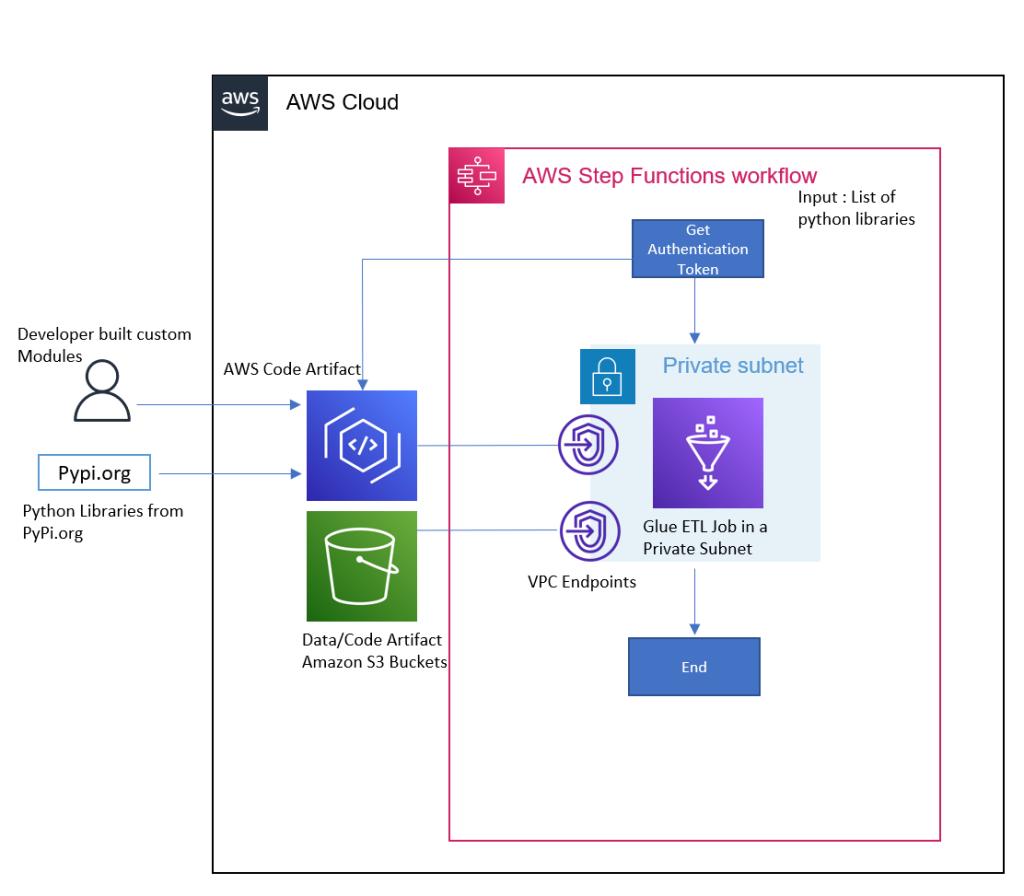
Simplify and optimize Python package management for AWS Glue PySpark jobs with AWS CodeArtifact
Data engineers use various Python packages to meet their data processing requirements while building data pipelines with AWS Glue PySpark Jobs. Languages like Python and Scala are commonly used in data pipeline development. Developers can take advantage of their open-source packages or even customize their own to make it easier and faster to perform use […]

Build a multilingual dashboard with Amazon Athena and Amazon QuickSight
Amazon QuickSight is a serverless business intelligence (BI) service used by organizations of any size to make better data-driven decisions. QuickSight dashboards can also be embedded into SaaS apps and web portals to provide interactive dashboards, natural language query or data analysis capabilities to app users seamlessly. The QuickSight Demo Central contains many dashboards, feature showcase […]

Orchestrate big data jobs on on-premises clusters with AWS Step Functions
Customers with specific needs to run big data compute jobs on an on-premises infrastructure often require a scalable orchestration solution. For large-scale distributed compute clusters, the orchestration of jobs must be scalable to maximize their utilization, while at the same time remain resilient to any failures to prevent blocking the ever-growing influx of data and […]

Access Apache Livy using a Network Load Balancer on a Kerberos-enabled Amazon EMR cluster
Amazon EMR is a cloud big data platform for running large-scale distributed data processing jobs, interactive SQL queries, and machine learning (ML) applications using open-source analytics frameworks such as Apache Spark, Apache Hive, and Presto. Amazon EMR supports Kerberos for authentication; you can enable Kerberos on Amazon EMR and put the cluster in a private […]