AWS Big Data Blog
Category: Serverless

Introducing AWS Glue serverless Spark UI for better monitoring and troubleshooting
Today, we are pleased to announce serverless Spark UI built into the AWS Glue console. You can now use Spark UI easily as it’s a built-in component of the AWS Glue console, enabling you to access it with a single click when examining the details of any given job run. There’s no infrastructure setup or teardown required. AWS Glue serverless Spark UI is a fully-managed serverless offering and generally starts up in a matter of seconds. Serverless Spark UI makes it significantly faster and easier to get jobs working in production because you have ready access to low level details for your job runs.

Clean up your Excel and CSV files without writing code using AWS Glue DataBrew
Managing data within an organization is complex. Handling data from outside the organization adds even more complexity. As the organization receives data from multiple external vendors, it often arrives in different formats, typically Excel or CSV files, with each vendor using their own unique data layout and structure. In this blog post, we’ll explore a […]

How Wallapop improved performance of analytics workloads with Amazon Redshift Serverless and data sharing
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it straightforward and cost-effective to analyze all your data at petabyte scale, using standard SQL and your existing business intelligence (BI) tools. Today, tens of thousands of customers run business-critical workloads on Amazon Redshift. Amazon Redshift Serverless makes it effortless to run and […]

How Gilead used Amazon Redshift to quickly and cost-effectively load third-party medical claims data
This post was co-written with Rajiv Arora, Director of Data Science Platform at Gilead Life Sciences. Gilead Sciences, Inc. is a biopharmaceutical company committed to advancing innovative medicines to prevent and treat life-threatening diseases, including HIV, viral hepatitis, inflammation, and cancer. A leader in virology, Gilead historically relied on these drugs for growth but now […]

GoDaddy benchmarking results in up to 24% better price-performance for their Spark workloads with AWS Graviton2 on Amazon EMR Serverless
This is a guest post co-written with Mukul Sharma, Software Development Engineer, and Ozcan IIikhan, Director of Engineering from GoDaddy. GoDaddy empowers everyday entrepreneurs by providing all the help and tools to succeed online. With more than 20 million customers worldwide, GoDaddy is the place people come to name their ideas, build a professional website, […]

Unlock scalable analytics with AWS Glue and Google BigQuery
Data integration is the foundation of robust data analytics. It encompasses the discovery, preparation, and composition of data from diverse sources. In the modern data landscape, accessing, integrating, and transforming data from diverse sources is a vital process for data-driven decision-making. AWS Glue, a serverless data integration and extract, transform, and load (ETL) service, has […]

SmugMug’s durable search pipelines for Amazon OpenSearch Service
SmugMug operates two very large online photo platforms, SmugMug and Flickr, enabling more than 100 million customers to safely store, search, share, and sell tens of billions of photos. Customers uploading and searching through decades of photos helped turn search into critical infrastructure, growing steadily since SmugMug first used Amazon CloudSearch in 2012, followed by […]

Network connectivity patterns for Amazon OpenSearch Serverless
Amazon OpenSearch Serverless is an on-demand, auto-scaling configuration for Amazon OpenSearch Service. OpenSearch Serverless enables a broad set of use cases, such as real-time application monitoring, log analytics, and website search. OpenSearch Serverless lets you use OpenSearch without having to worry about scaling and managing an OpenSearch cluster. A collection can be accessed over the […]
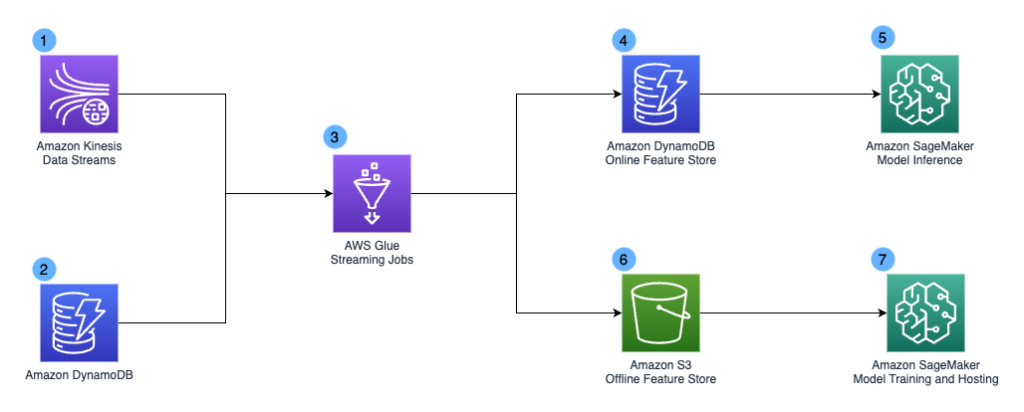
How Chime Financial uses AWS to build a serverless stream analytics platform and defeat fraudsters
This is a guest post by Khandu Shinde, Staff Software Engineer and Edward Paget, Senior Software Engineering at Chime Financial. Chime is a financial technology company founded on the premise that basic banking services should be helpful, easy, and free. Chime partners with national banks to design member first financial products. This creates a more […]

Build streaming data pipelines with Amazon MSK Serverless and IAM authentication
Amazon’s serverless Apache Kafka offering, Amazon Managed Streaming for Apache Kafka (Amazon MSK) Serverless, is attracting a lot of interest. It’s appreciated for its user-friendly approach, ability to scale automatically, and cost-saving benefits over other Kafka solutions. However, a hurdle encountered by many users is the requirement of MSK Serverless to use AWS Identity and Access Management (IAM) access control. At the time of writing, the Amazon MSK library for IAM is exclusive to Kafka libraries in Java, creating a challenge for users of other programming languages. In this post, we aim to address this issue and present how you can use Amazon API Gateway and AWS Lambda to navigate around this obstacle.