AWS Big Data Blog
How gaming companies can use Amazon Redshift Serverless to build scalable analytical applications faster and easier
This post provides guidance on how to build scalable analytical solutions for gaming industry use cases using Amazon Redshift Serverless. It covers how to use a conceptual, logical architecture for some of the most popular gaming industry use cases like event analysis, in-game purchase recommendations, measuring player satisfaction, telemetry data analysis, and more. This post also discusses the art of the possible with newer innovations in AWS services around streaming, machine learning (ML), data sharing, and serverless capabilities.
Our gaming customers tell us that their key business objectives include the following:
- Increased revenue from in-app purchases
- High average revenue per user and lifetime value
- Improved stickiness with better gaming experience
- Improved event productivity and high ROI
Our gaming customers also tell us that while building analytics solutions, they want the following:
- Low-code or no-code model – Out-of-the-box solutions are preferred to building customized solutions.
- Decoupled and scalable – Serverless, auto scaled, and fully managed services are preferred over manually managed services. Each service should be easily replaceable, enhanced with little or no dependency. Solutions should be flexible to scale up and down.
- Portability to multiple channels – Solutions should be compatible with most of endpoint channels like PC, mobile, and gaming platforms.
- Flexible and easy to use – The solutions should provide less restrictive, easy-to-access, and ready-to-use data. They should also provide optimal performance with low or no tuning.
Analytics reference architecture for gaming organizations
In this section, we discuss how gaming organizations can use a data hub architecture to address the analytical needs of an enterprise, which requires the same data at multiple levels of granularity and different formats, and is standardized for faster consumption. A data hub is a center of data exchange that constitutes a hub of data repositories and is supported by data engineering, data governance, security, and monitoring services.
A data hub contains data at multiple levels of granularity and is often not integrated. It differs from a data lake by offering data that is pre-validated and standardized, allowing for simpler consumption by users. Data hubs and data lakes can coexist in an organization, complementing each other. Data hubs are more focused around enabling businesses to consume standardized data quickly and easily. Data lakes are more focused around storing and maintaining all the data in an organization in one place. And unlike data warehouses, which are primarily analytical stores, a data hub is a combination of all types of repositories—analytical, transactional, operational, reference, and data I/O services, along with governance processes. A data warehouse is one of the components in a data hub.
The following diagram is a conceptual analytics data hub reference architecture. This architecture resembles a hub-and-spoke approach. Data repositories represent the hub. External processes are the spokes feeding data to and from the hub. This reference architecture partly combines a data hub and data lake to enable comprehensive analytics services.
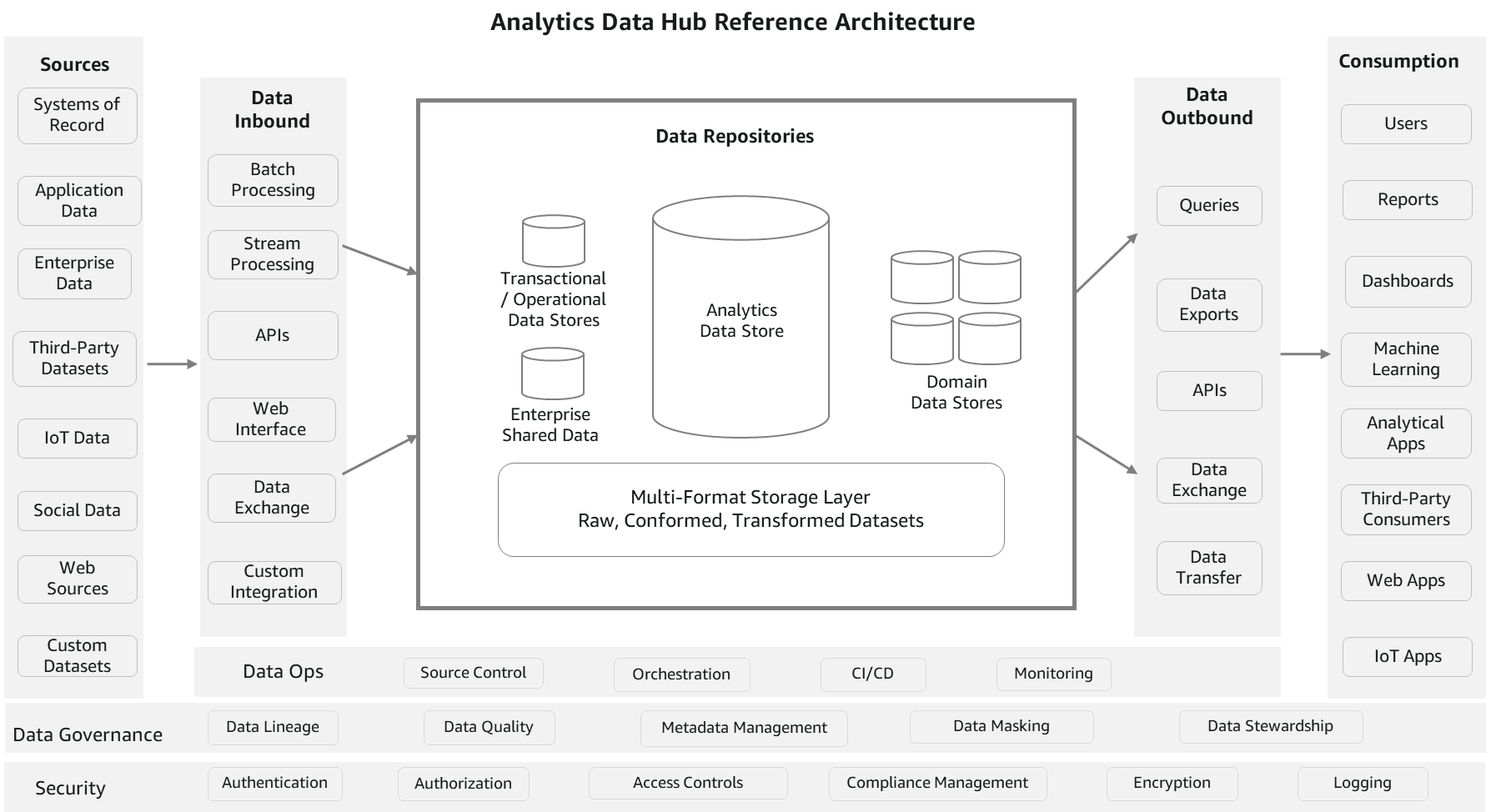
Let’s look at the components of the architecture in more detail.
Sources
Data can be loaded from multiple sources, such as systems of record, data generated from applications, operational data stores, enterprise-wide reference data and metadata, data from vendors and partners, machine-generated data, social sources, and web sources. The source data is usually in either structured or semi-structured formats, which are highly and loosely formatted, respectively.
Data inbound
This section consists of components to process and load the data from multiple sources into data repositories. It can be in batch mode, continuous, pub/sub, or any other
custom integration. ETL (extract, transform, and load) technologies, streaming services, APIs, and data exchange interfaces are the core components of this pillar. Unlike ingestion processes, data can be transformed as per business rules before loading. You can apply technical or business data quality rules and load raw data as well. Essentially, it provides the flexibility to get the data into repositories in its most usable form.
Data repositories
This section consists of a group of data stores, which includes data warehouses, transactional or operational data stores, reference data stores, domain data stores housing purpose-built business views, and enterprise datasets (file storage). The file storage component is usually a common component between a data hub and a data lake to avoid data duplication and provide comprehensiveness. Data can also be shared among all these repositories without physically moving with features, such as data sharing and federated queries. However, data copy and duplication are allowed considering various consumption needs in terms of formats and latency.
Data outbound
Data is often consumed using structured queries for analytical needs. Also, datasets are accessed for ML, data exporting, and publishing needs. This section consists of components to query the data, export, exchange, and APIs. In terms of implementation, the same technologies may be used for both inbound and outbound, but the functions are different. However, it’s not mandatory to use the same technologies. These processes aren’t transformation heavy because the data is already standardized and almost ready to consume. The focus is on the ease of consumption and integration with consuming services.
Consumption
This pillar consists of various consumption channels for enterprise analytical needs. It includes business intelligence (BI) users, canned and interactive reports, dashboards, data science workloads, Internet of Things (IoT), web apps, and third-party data consumers. Popular consumption entities in many organizations are queries, reports, and data science workloads. Because there are multiple data stores maintaining data at different granularity and formats to service consumer needs, these consumption components depend on data catalogs for finding the right source.
Data governance
Data governance is key to the success of a data hub reference architecture. It constitutes components like metadata management, data quality, lineage, masking, and stewardship, which are required for organized maintenance of the data hub. Metadata management helps organize the technical and business metadata catalog, and consumers can reference this catalog to know what data is available in which repository and at what granularity, format, owners, refresh frequency, and so on. Along with metadata management, data quality is important to increase confidence for consumers. This includes data cleansing, validation, conformance, and data controls.
Security and monitoring
Users and application access should be controlled at multiple levels. It starts with authentication, then authorizing who and what should be accessed, policy management, encryption, and applying data compliance rules. It also includes monitoring components to log the activity for auditing and analysis.
Analytics data hub solution architecture on AWS
The following reference architecture provides an AWS stack for the solution components.
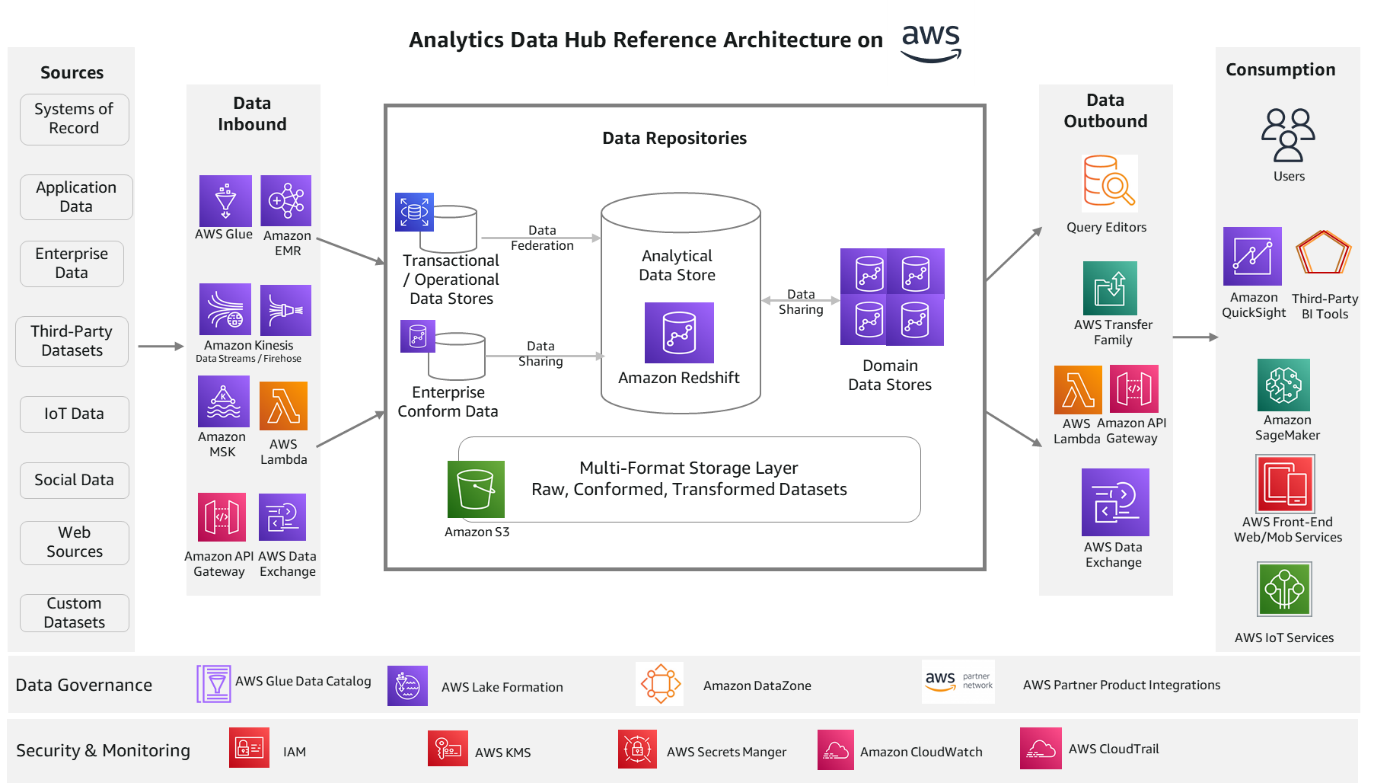
Let’s look at each component again and the relevant AWS services.
Data inbound services
AWS Glue and Amazon EMR services are ideal for batch processing. They scale automatically and are able to process most of the industry standard data formats. Amazon Kinesis Data Streams, Amazon Kinesis Data Firehose, and Amazon Managed Streaming for Apache Kafka (Amazon MSK) enables you to build streaming process applications. These streaming services integrate well with the Amazon Redshift streaming feature. This helps you process real-time sources, IoT data, and data from online channels. You can also ingest data with third-party tools like Informatica, dbt, and Matallion.
You can build RESTful APIs and WebSocket APIs using Amazon API Gateway and AWS Lambda, which will enable real-time two-way communication with web sources, social, and IoT sources. AWS Data Exchange helps with subscribing to third-party data in AWS Marketplace. Data subscription and access is fully managed with this service. Refer to the respective service documentation for further details.
Data repository services
Amazon Redshift is the recommended data storage service for OLAP (Online Analytical Processing) workloads such as cloud data warehouses, data marts, and other analytical data stores. This service is the core of this reference architecture on AWS and can address most analytical needs out of the box. You can use simple SQL to analyze structured and semi-structured data across data warehouses, data marts, operational databases, and data lakes to deliver the best price performance at any scale. The Amazon Redshift data sharing feature provides instant, granular, and high-performance access without data copies and data movement across multiple Amazon Redshift data warehouses in the same or different AWS accounts, and across Regions.
For ease of use, Amazon Redshift offers a serverless option. Amazon Redshift Serverless automatically provisions and intelligently scales data warehouse capacity to deliver fast performance for even the most demanding and unpredictable workloads, and you pay only for what you use. Just load your data and start querying right away in Amazon Redshift Query Editor or in your favorite BI tool and continue to enjoy the best price performance and familiar SQL features in an easy-to-use, zero administration environment.
Amazon Relational Database Service (Amazon RDS) is a fully managed service for building transactional and operational data stores. You can choose from many popular engines such as MySQL, PostgreSQL, MariaDB, Oracle, and SQL Server. With the Amazon Redshift federated query feature, you can query transactional and operational data in place without moving the data. The federated query feature currently supports Amazon RDS for PostgreSQL, Amazon Aurora PostgreSQL-Compatible Edition, Amazon RDS for MySQL, and Amazon Aurora MySQL-Compatible Edition.
Amazon Simple Storage Service (Amazon S3) is the recommended service for multi-format storage layers in the architecture. It offers industry-leading scalability, data availability, security, and performance. Organizations typically store data in Amazon S3 using open file formats. Open file formats enable analysis of the same Amazon S3 data using multiple processing and consumption layer components. Data in Amazon S3 can be easily queried in place using SQL with Amazon Redshift Spectrum. It helps you query and retrieve structured and semi-structured data from files in Amazon S3 without having to load the data. Multiple Amazon Redshift data warehouses can concurrently query the same datasets in Amazon S3 without the need to make copies of the data for each data warehouse.
Data outbound services
Amazon Redshift comes with the web-based analytics workbench Query Editor V2.0, which helps you run queries, explore data, create SQL notebooks, and collaborate on data with your teams in SQL through a common interface. AWS Transfer Family helps securely transfer files using SFTP, FTPS, FTP, and AS2 protocols. It supports thousands of concurrent users and is a fully managed, low-code service. Similar to inbound processes, you can utilize Amazon API Gateway and AWS Lambda for data pull using the Amazon Redshift Data API. And AWS Data Exchange helps publish your data to third parties for consumption through AWS Marketplace.
Consumption services
Amazon QuickSight is the recommended service for creating reports and dashboards. It enables you to create interactive dashboards, visualizations, and advanced analytics with ML insights. Amazon SageMaker is the ML platform for all your data science workload needs. It helps you build, train, and deploy models consuming the data from repositories in the data hub. You can use Amazon front-end web and mobile services and AWS IoT services to build web, mobile, and IoT endpoint applications to consume data out of the data hub.
Data governance services
The AWS Glue Data Catalog and AWS Lake Formation are the core data governance services AWS currently offers. These services help manage metadata centrally for all the data repositories and manage access controls. They also help with data classification and can automatically handle schema changes. You can use Amazon DataZone to discover and share data at scale across organizational boundaries with built-in governance and access controls. AWS is investing in this space to provide more a unified experience for AWS services. There are many partner products such as Collibra, Alation, Amorphic, Informatica, and more, which you can use as well for data governance functions with AWS services.
Security and monitoring services
AWS Identity and Access Management (AWS IAM) manages identities for AWS services and resources. You can define users, groups, roles, and policies for fine-grained access management of your workforce and workloads. AWS Key Management Service (AWS KMS) manages AWS keys or customer managed keys for your applications. Amazon CloudWatch and AWS CloudTrail help provide monitoring and auditing capabilities. You can collect metrics and events and analyze them for operational efficiency.
In this post, we’ve discussed the most common AWS services for the respective solution components. However, you aren’t limited to only these services. There are many other AWS services for specific use cases that may be more appropriate for your needs than what we discussed here. You can reach to AWS Analytics Solutions Architects for appropriate guidance.
Example architectures for gaming use cases
In this section, we discuss example architectures for two gaming use cases.
Game event analysis
In-game events (also called timed or live events) encourage player engagement through excitement and anticipation. Events entice players to interact with the game, increasing player satisfaction and revenue with in-game purchases. Events have become more and more important, especially as games shift from being static pieces of entertainment to be played as is to offering dynamic and changing content through the use of services that use information to make decisions about game play as the game is being played. This enables games to change as the players play and influence what works and what doesn’t, and gives any game a potentially infinite lifespan.
This capability of in-game events to offer fresh content and activities within a familiar framework is how you keep players engaged and playing for months to years. Players can enjoy new experiences and challenges within the familiar framework or world that they have grown to love.
The following example shows how such an architecture might appear, including changes to support various sections of the process like breaking the data into separate containers to accommodate scalability, charge-back, and ownership.
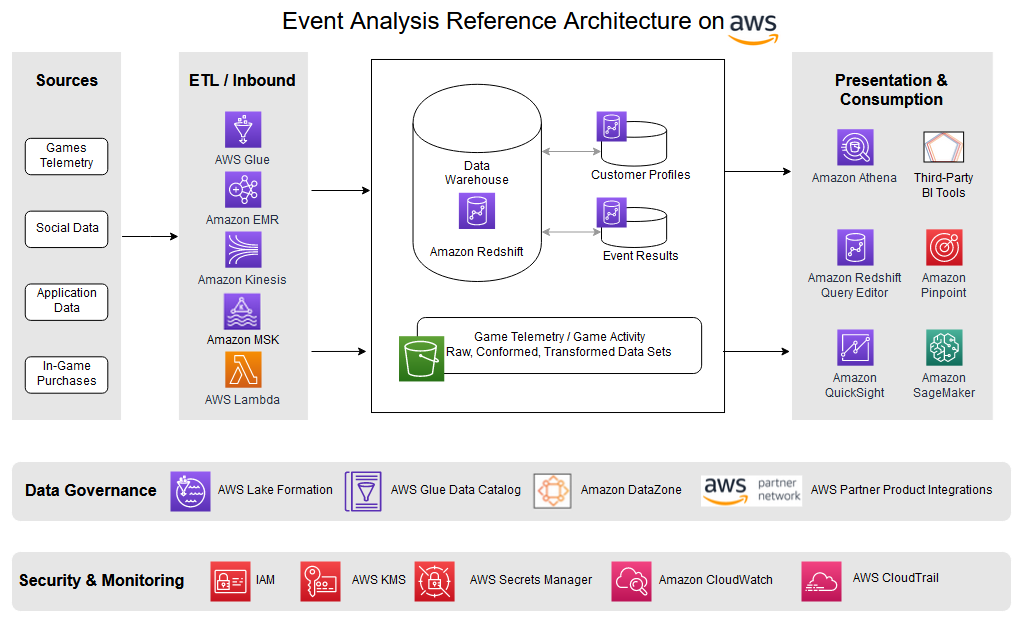
To fully understand how events are viewed by the players and to make decisions about future events requires information on how the latest event was actually performed. This means gathering a lot of data as the players play to build key performance indicators (KPIs) that measure the effectiveness and player satisfaction with each event. This requires analytics that specifically measure each event and capture, analyze, report on, and measure player experience for each event. These KPIs include the following:
- Initial user flow interactions – What actions users are taking after they first receive or download an event update in a game. Are there any clear drop-off points or bottlenecks that are turning people off the event?
- Monetization – When, what, and where users are spending money on in the event, whether it’s buying in-game currencies, answering ads, specials, and so on.
- Game economy – How can users earn and spend virtual currencies or goods during an event, using in-game money, trades, or barter.
- In-game activity – Player wins, losses, leveling up, competition wins, or player achievements within the event.
- User to user interactions – Invitations, gifting, chats (private and group), challenges, and so on during an event.
These are just some of the KPIs and metrics that are key for predictive modeling of events as the game acquires new players while keeping existing users involved, engaged, and playing.
In-game activity analysis
In-game activity analysis essentially looks at any meaningful, purposeful activity the player might show, with the goal of trying to understand what actions are taken, their timing, and outcomes. This includes situational information about the players, including where they are playing (both geographical and cultural), how often, how long, what they undertake on each login, and other activities.
The following example shows how such an architecture might appear, including changes to support various sections of the process like breaking the data into separate warehouses. The multi-cluster warehouse approach helps scale the workload independently, provides flexibility to the implemented charge-back model, and supports decentralized data ownership.
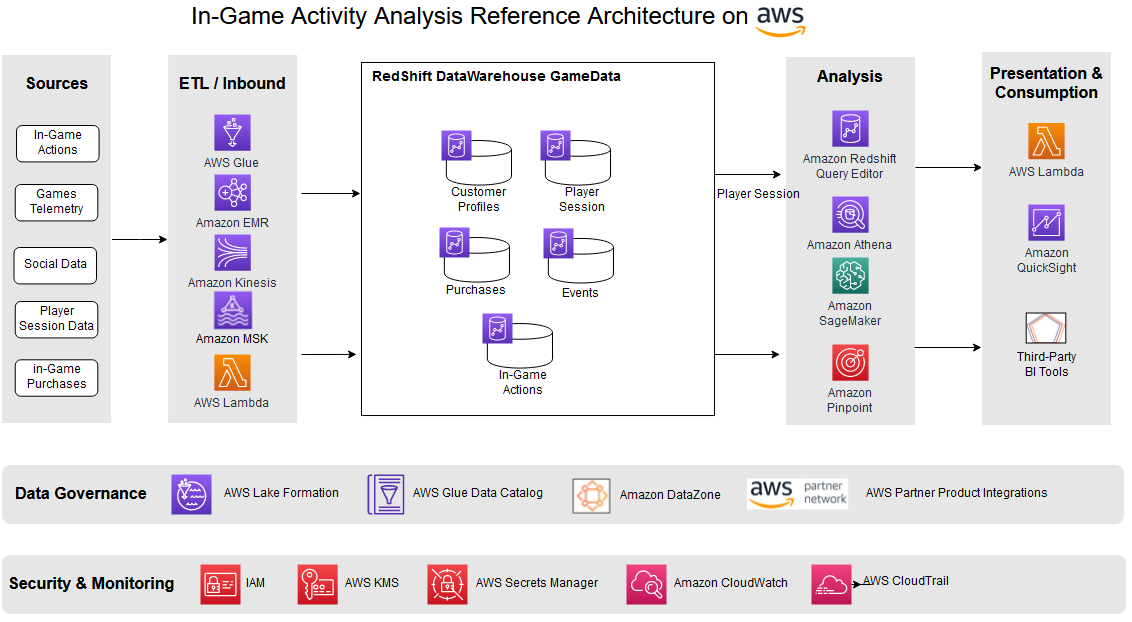
The solution essentially logs information to help understand the behavior of your players, which can lead to insights that increase retention of existing players, and acquisition of new ones. This can provide the ability to do the following:
- Provide in-game purchase recommendations
- Measure player trends in the short term and over time
- Plan events the players will engage in
- Understand what parts of your game are most successful and which are less so
You can use this understanding to make decisions about future game updates, make in-game purchase recommendations, determine when and how your game economy may need to be balanced, and even allow players to change their character or play as the game progresses by injecting this information and accompanying decisions back into the game.
Conclusion
This reference architecture, while showing examples of only a few analysis types, provides a faster technology path for enabling game analytics applications. The decoupled, hub/spoke approach brings the agility and flexibility to implement different approaches to analytics and understanding the performance of game applications. The purpose-built AWS services described in this architecture provide comprehensive capabilities to easily collect, store, measure, analyze, and report game and event metrics. This helps you efficiently perform in-game analytics, event analysis, measure player satisfaction, and provide tailor-made recommendations to game players, efficiently organize events, and increase retention rates.
Thanks for reading the post. If you have any feedback or questions, please leave them in the comments.
About the authors
 Satesh Sonti is a Sr. Analytics Specialist Solutions Architect based out of Atlanta, specialized in building enterprise data platforms, data warehousing, and analytics solutions. He has over 16 years of experience in building data assets and leading complex data platform programs for banking and insurance clients across the globe.
Satesh Sonti is a Sr. Analytics Specialist Solutions Architect based out of Atlanta, specialized in building enterprise data platforms, data warehousing, and analytics solutions. He has over 16 years of experience in building data assets and leading complex data platform programs for banking and insurance clients across the globe.
 Tanya Rhodes is a Senior Solutions Architect based out of San Francisco, focused on games customers with emphasis on analytics, scaling, and performance enhancement of games and supporting systems. She has over 25 years of experience in enterprise and solutions architecture specializing in very large business organizations across multiple lines of business including games, banking, healthcare, higher education, and state governments.
Tanya Rhodes is a Senior Solutions Architect based out of San Francisco, focused on games customers with emphasis on analytics, scaling, and performance enhancement of games and supporting systems. She has over 25 years of experience in enterprise and solutions architecture specializing in very large business organizations across multiple lines of business including games, banking, healthcare, higher education, and state governments.