AWS Big Data Blog
Category: Amazon Simple Storage Service (S3)
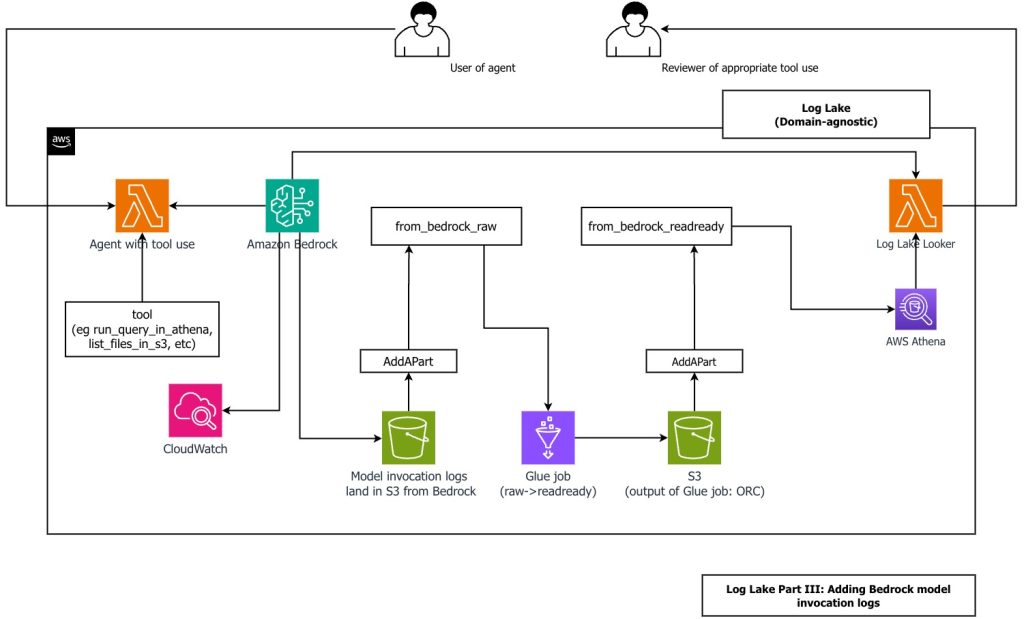
Create a customizable cross-company log lake, Part II: Build and add Amazon Bedrock
In this post, you learn how to build Log Lake, a customizable cross-company data lake for compliance-related use cases that combines AWS CloudTrail and Amazon CloudWatch logs. You’ll discover how to set up separate tables for writing and reading, implement event-driven partition management using AWS Lambda, and transform raw JSON files into read-optimized Apache ORC format using AWS Glue jobs. Additionally, you’ll see how to extend Log Lake by adding Amazon Bedrock model invocation logs to enable human review of agent actions with elevated permissions, and how to use an AI agent to query your log data without writing SQL.
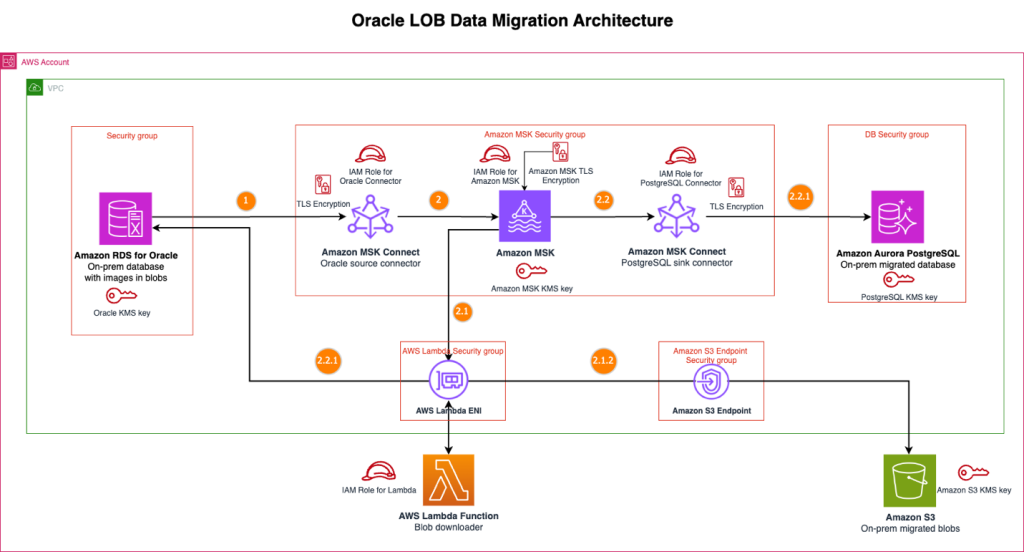
Streamline large binary object migrations: A Kafka-based solution for Oracle to Amazon Aurora PostgreSQL and Amazon S3
In this post, we present a scalable solution that addresses the challenge of migrating your large binary objects (LOBs) from Oracle to AWS by using a streaming architecture that separates LOB storage from structured data. This approach avoids size constraints, reduces Oracle licensing costs, and preserves data integrity throughout extended migration periods.

Medidata’s journey to a modern lakehouse architecture on AWS
In this post, we show you how Medidata created a unified, scalable, real-time data platform that serves thousands of clinical trials worldwide with AWS services, Apache Iceberg, and a modern lakehouse architecture.

Accelerate data lake operations with Apache Iceberg V3 deletion vectors and row lineage
In this post, we walk you through the new capabilities in Iceberg V3, explain how deletion vectors and row lineage address these challenges, explore real-world use cases across industries, and provide practical guidance on implementing Iceberg V3 features across AWS analytics, catalog, and storage services.

Amazon SageMaker introduces Amazon S3 based shared storage for enhanced project collaboration
AWS recently announced that Amazon SageMaker now offers Amazon Simple Storage Service (Amazon S3) based shared storage as the default project file storage option for new Amazon SageMaker Unified Studio projects. This feature addresses the deprecation of AWS CodeCommit while providing teams with a straightforward and consistent way to collaborate on project files across the […]

Break down data silos and seamlessly query Iceberg tables in Amazon SageMaker from Snowflake
This blog post discusses how to create a seamless integration between Amazon SageMaker Lakehouse and Snowflake for modern data analytics. It specifically demonstrates how organizations can enable Snowflake to access tables in AWS Glue Data Catalog (stored in S3 buckets) through SageMaker Lakehouse Iceberg REST Catalog, with security managed by AWS Lake Formation. The post provides a detailed technical walkthrough of implementing this integration, including creating IAM roles and policies, configuring Lake Formation access controls, setting up catalog integration in Snowflake, and managing data access permissions. While four different patterns exist for accessing Iceberg tables from Snowflake, the blog focuses on the first pattern using catalog integration with SigV4 authentication and Lake Formation credential vending.

Optimizing vector search using Amazon S3 Vectors and Amazon OpenSearch Service
We now have a public preview of two integrations between Amazon Simple Storage Service (Amazon S3) Vectors and Amazon OpenSearch Service that give you more flexibility in how you store and search vector embeddings. In this post, we walk through this seamless integration, providing you with flexible options for vector search implementation.

Compaction support for Avro and ORC file formats in Apache Iceberg tables in Amazon S3
In this post, we explore how Amazon S3 Tables has expanded its automatic compaction capabilities to include Avro and ORC file formats for Apache Iceberg tables, alongside the previously supported Parquet format. Through performance testing with over 20 billion events, the capability demonstrates significant query performance improvements ranging from 12% to 40% when using compacted tables compared to non-compacted tables across different file formats.

How Stifel built a modern data platform using AWS Glue and an event-driven domain architecture
In this post, we show you how Stifel implemented a modern data platform using AWS services and open data standards, building an event-driven architecture for domain data products while centralizing the metadata to facilitate discovery and sharing of data products.

Stream data from Amazon MSK to Apache Iceberg tables in Amazon S3 and Amazon S3 Tables using Amazon Data Firehose
In this post, we walk through two solutions that demonstrate how to stream data from your Amazon MSK provisioned cluster to Iceberg-based data lakes in Amazon S3 using Amazon Data Firehose.