AWS Big Data Blog
Category: Amazon Simple Storage Service (S3)
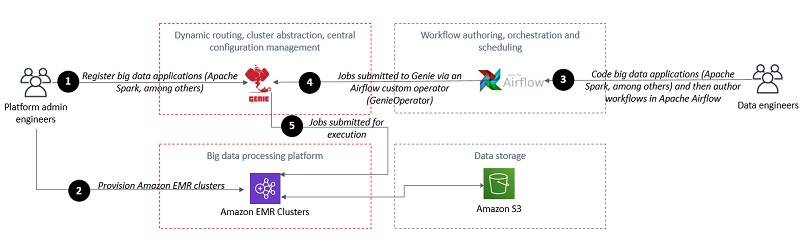
Dream11’s journey to building their Data Highway on AWS
This is a guest post co-authored by Pradip Thoke of Dream11. In their own words, “Dream11, the flagship brand of Dream Sports, is India’s biggest fantasy sports platform, with more than 100 million users. We have infused the latest technologies of analytics, machine learning, social networks, and media technologies to enhance our users’ experience. Dream11 […]

How FanDuel Group secures personally identifiable information in a data lake using AWS Lake Formation
This post is co-written with Damian Grech from FanDuel FanDuel Group is an innovative sports-tech entertainment company that is changing the way consumers engage with their favorite sports, teams, and leagues. The premier gaming destination in the US, FanDuel Group consists of a portfolio of leading brands across gaming, sports betting, daily fantasy sports, advance-deposit […]

Ingesting Jira data into Amazon S3
Consolidating data from a work management tool like Jira and integrating this data with other data sources like ServiceNow, GitHub, Jenkins, and Time Entry Systems enables end-to-end visibility of different aspects of the software development lifecycle and helps keep your projects on schedule and within budget. Amazon Simple Storage Service (Amazon S3) is an object […]

Creating a source to Lakehouse data replication pipe using Apache Hudi, AWS Glue, AWS DMS, and Amazon Redshift
February 2021 update – Please refer to the post Writing to Apache Hudi tables using AWS Glue Custom Connector to learn about an easier mechanism to write to Hudi tables using AWS Glue Custom Connector. In this post, we include the modified Apache Hudi JARs as an external dependency. The AWS Glue Custom Connector feature […]
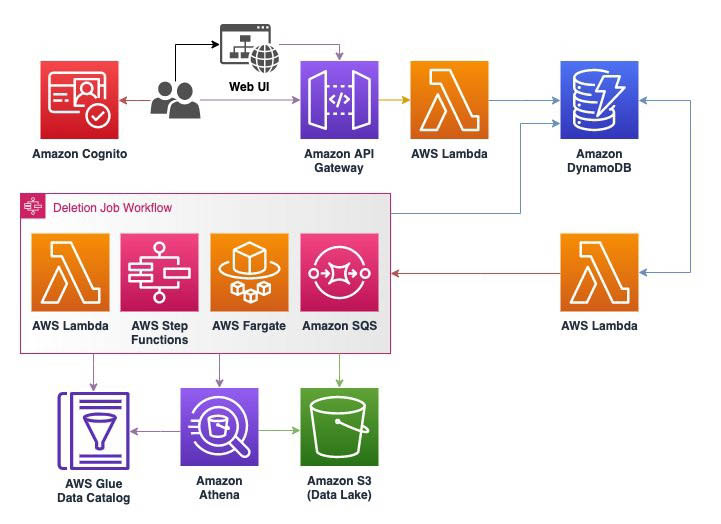
Handling data erasure requests in your data lake with Amazon S3 Find and Forget
February 2024: This post was reviewed and updated for accuracy. Data lakes are a popular choice for organizations to store data around their business activities. Best practice design of data lakes impose that data is immutable once stored, but new regulations such as the European General Data Protection Regulation (GDPR), California Consumer Privacy Act (CCPA), […]

Apply record level changes from relational databases to Amazon S3 data lake using Apache Hudi on Amazon EMR and AWS Database Migration Service
Data lakes give organizations the ability to harness data from multiple sources in less time. Users across different roles are now empowered to collaborate and analyze data in different ways, leading to better, faster decision-making. Amazon Simple Storage Service (Amazon S3) is the highly performant object storage service for structured and unstructured data and the […]
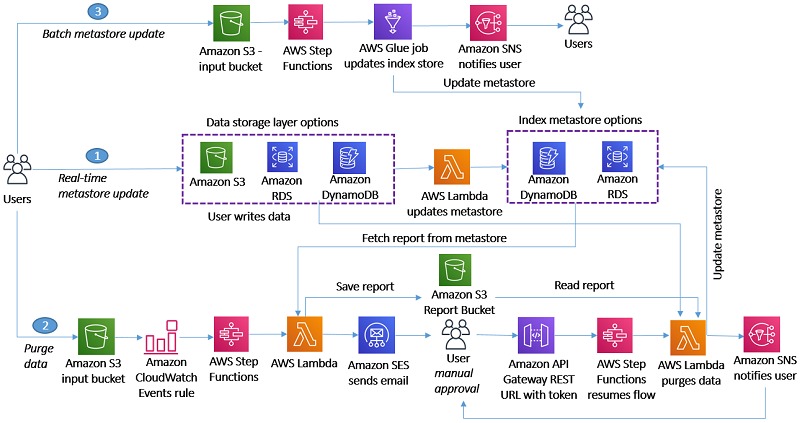
How to delete user data in an AWS data lake
General Data Protection Regulation (GDPR) is an important aspect of today’s technology world, and processing data in compliance with GDPR is a necessity for those who implement solutions within the AWS public cloud. One article of GDPR is the “right to erasure” or “right to be forgotten” which may require you to implement a solution […]

Streaming data from Amazon S3 to Amazon Kinesis Data Streams using AWS DMS
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. December 2022: This post was reviewed for accuracy. Stream processing is very useful in use cases where we need to detect a problem quickly and improve the […]

Analyzing Amazon S3 server access logs using Amazon OpenSearch Service
This blog post was last reviewed and updated April, 2022. When you use Amazon Simple Storage Service (Amazon S3) to store corporate data and host websites, you need additional logging to monitor access to your data and the performance of your application. An effective logging solution enhances security and improves the detection of security incidents. […]
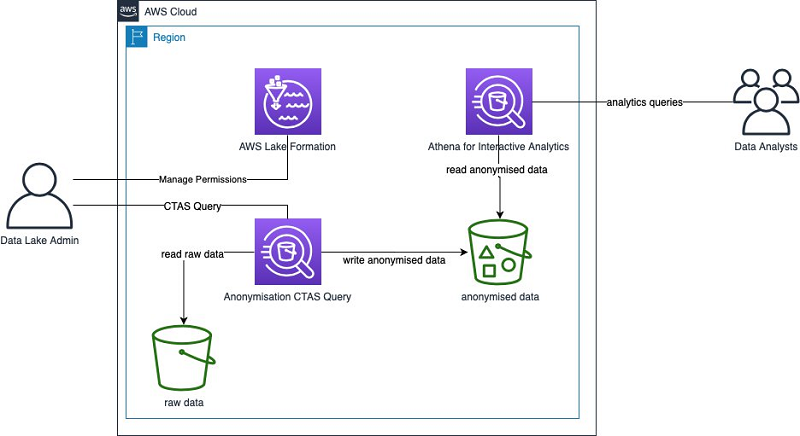
Anonymize and manage data in your data lake with Amazon Athena and AWS Lake Formation
Most organizations have to comply with regulations when dealing with their customer data. For that reason, datasets that contain personally identifiable information (PII) is often anonymized. A common example of PII can be tables and columns that contain personal information about an individual (such as first name and last name) or tables with columns that, if joined with another table, can trace back to an individual. You can use AWS Analytics services to anonymize your datasets. In this post, I describe how to use Amazon Athena to anonymize a dataset. You can then use AWS Lake Formation to provide the right access to the right personas.