AWS Big Data Blog
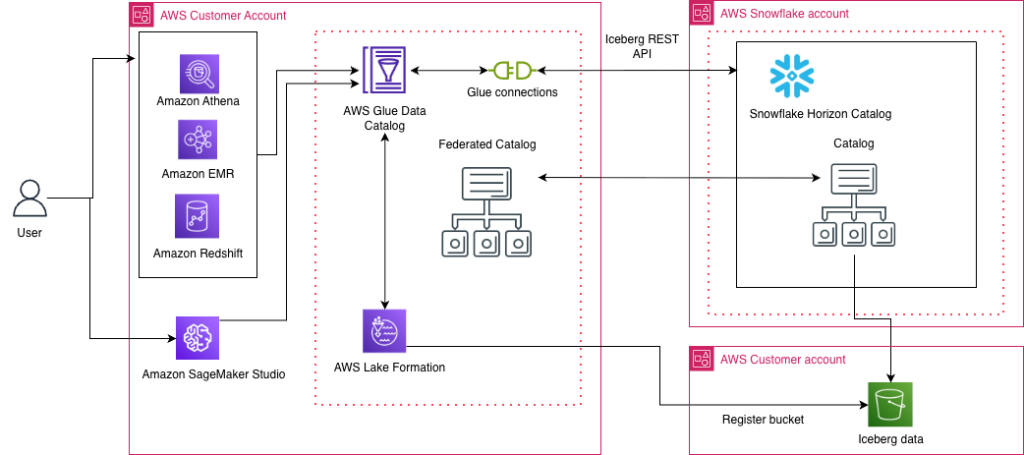
Access Snowflake Horizon Catalog data using catalog federation in the AWS Glue Data Catalog
AWS has introduced a new catalog federation feature that enables direct access to Snowflake Horizon Catalog data through AWS Glue Data Catalog. This integration allows organizations to discover and query data in Iceberg format while maintaining security through AWS Lake Formation. This post provides a step-by-step guide to establishing this integration, including configuring Snowflake Horizon Catalog, setting up authentication, creating necessary IAM roles, and implementing AWS Lake Formation permissions. Learn how to enable cross-platform analytics while maintaining robust security and governance across your data environment.
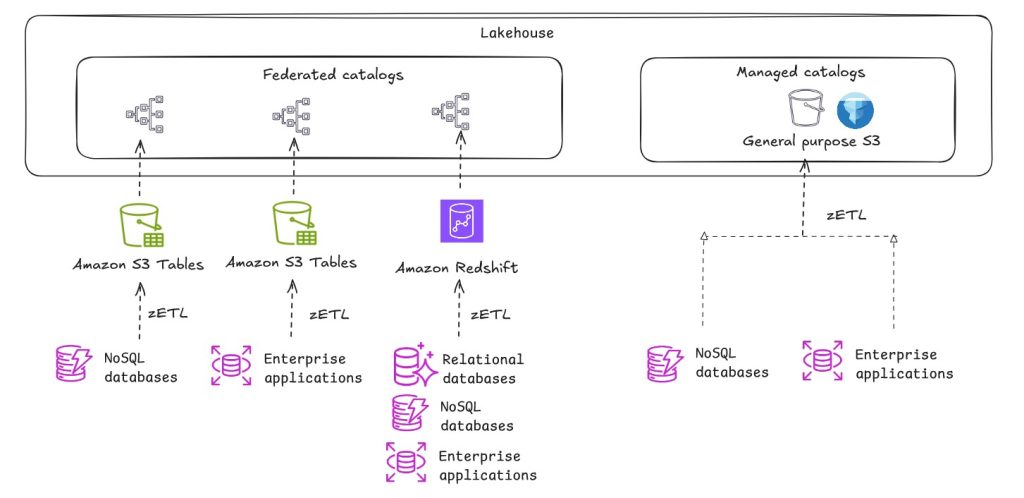
Navigating architectural choices for a lakehouse using Amazon SageMaker
Over time, several distinct lakehouse approaches have emerged. In this post, we show you how to evaluate and choose the right lakehouse pattern for your needs. A lakehouse architecture isn’t about choosing between a data lake and a data warehouse. Instead, it’s an approach to interoperability where both frameworks coexist and serve different purposes within a unified data architecture. By understanding fundamental storage patterns, implementing effective catalog strategies, and using native storage capabilities, you can build scalable, high-performance data architectures that support both your current analytics needs and future innovation.
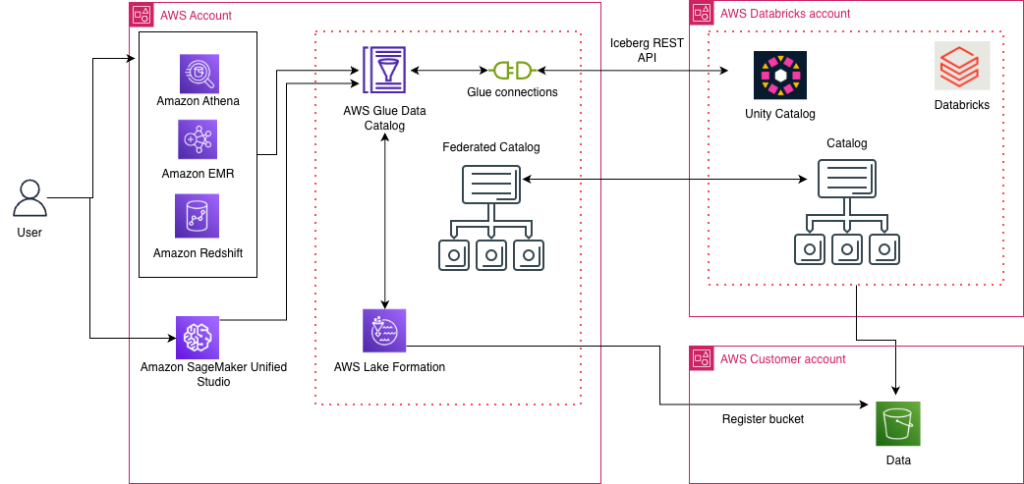
Access Databricks Unity Catalog data using catalog federation in the AWS Glue Data Catalog
AWS has launched the catalog federation capability, enabling direct access to Apache Iceberg tables managed in Databricks Unity Catalog through the AWS Glue Data Catalog. With this integration, you can discover and query Unity Catalog data in Iceberg format using an Iceberg REST API endpoint, while maintaining granular access controls through AWS Lake Formation. In this post, we demonstrate how to set up catalog federation between the Glue Data Catalog and Databricks Unity Catalog, enabling data querying using AWS analytics services.

Use Amazon SageMaker custom tags for project resource governance and cost tracking
Amazon SageMaker announced a new feature that you can use to add custom tags to resources created through an Amazon SageMaker Unified Studio project. This helps you enforce tagging standards that conform to your organization’s service control policies (SCPs) and helps enable cost tracking reporting practices on resources created across the organization. In this post, we look at use cases for custom tags and how to use the AWS Command Line Interface (AWS CLI) to add tags to project resources.
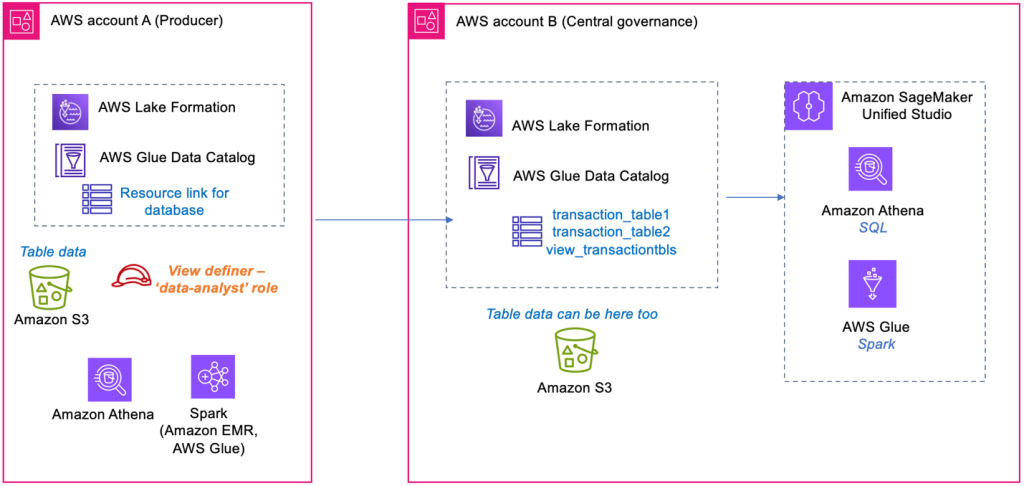
Create AWS Glue Data Catalog views using cross-account definer roles
In this post, we demonstrate how to use cross-account IAM definer roles with AWS Glue Data Catalog views. We show how data owner accounts can create and manage views in a central governance account while maintaining security and control over their data assets.

AWS analytics at re:Invent 2025: Unifying Data, AI, and governance at scale
re:Invent 2025 showcased the bold Amazon Web Services (AWS) vision for the future of analytics, one where data warehouses, data lakes, and AI development converge into a seamless, open, intelligent platform, with Apache Iceberg compatibility at its core. Across over 18 major announcements spanning three weeks, AWS demonstrated how organizations can break down data silos, […]

Amazon EMR Serverless eliminates local storage provisioning, reducing data processing costs by up to 20%
In this post, you’ll learn how Amazon EMR Serverless eliminates the need to configure local disk storage for Apache Spark workloads through a new serverless storage capability. We explain how this feature automatically handles shuffle operations, reduces data processing costs by up to 20%, prevents job failures from disk capacity constraints, and enables elastic scaling by decoupling storage from compute.
Building scalable AWS Lake Formation governed data lakes with dbt and Amazon Managed Workflows for Apache Airflow
Organizations often struggle with building scalable and maintainable data lakes—especially when handling complex data transformations, enforcing data quality, and monitoring compliance with established governance. Traditional approaches typically involve custom scripts and disparate tools, which can increase operational overhead and complicate access control. A scalable, integrated approach is needed to simplify these processes, improve data reliability, […]

Simplify multi-warehouse data governance with Amazon Redshift federated permissions
Amazon Redshift federated permissions simplify permissions management across multiple Redshift warehouses. In this post, we show you how to define data permissions one time and automatically enforce them across warehouses in your AWS account, removing the need to re-create security policies in each warehouse.

Simplified management of Amazon MSK with natural language using Kiro CLI and Amazon MSK MCP Server
In this post, we demonstrate how Kiro CLI and the MSK MCP server can streamline your Kafka management. Through practical examples and demonstrations, we show you how to use these tools to perform common administrative tasks efficiently while maintaining robust security and reliability.