AWS Big Data Blog
Tag: Amazon Athena
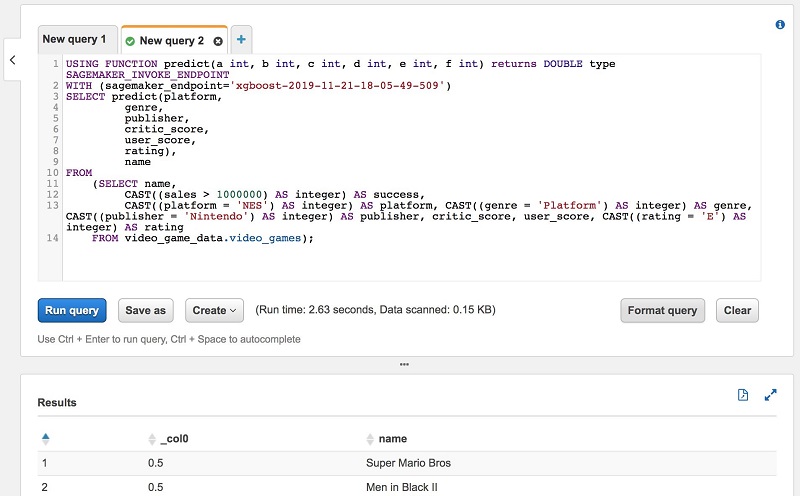
Prepare data for model-training and invoke machine learning models with Amazon Athena
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. Amazon Athena has announced a public preview of a new feature that provides an easy […]

Query any data source with Amazon Athena’s new federated query
April 2024: This post was reviewed for accuracy. Organizations today use data stores that are the best fit for the applications they build. For example, for an organization building a social network, a graph database such as Amazon Neptune is likely the best fit when compared to a relational database. Similarly, for workloads that require […]
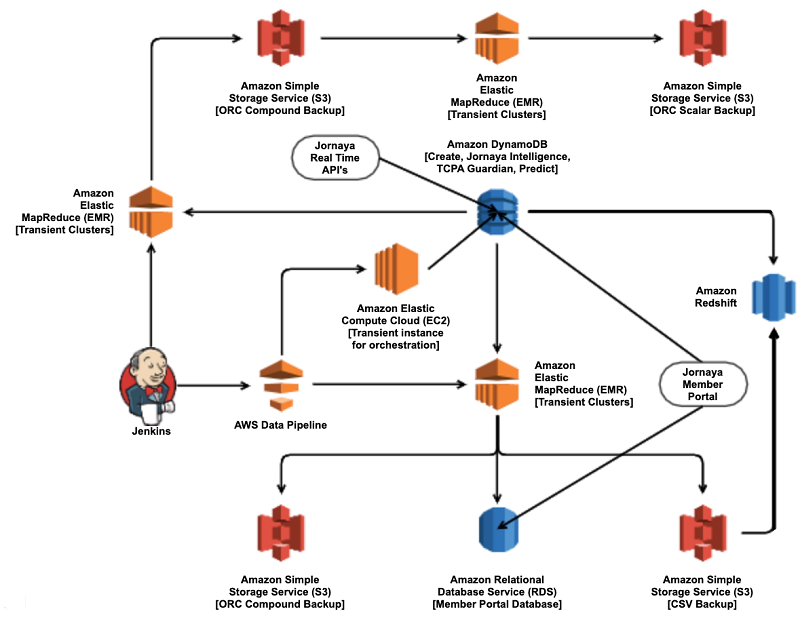
Simplify ETL data pipelines using Amazon Athena’s federated queries and user-defined functions
Amazon Athena recently added support for federated queries and user-defined functions (UDFs), both in Preview. See Query any data source with Amazon Athena’s new federated query for more details. Jornaya helps marketers intelligently connect consumers who are in the market for major life purchases such as homes, mortgages, cars, insurance, and education. Jornaya collects data […]

Access and manage data from multiple accounts from a central AWS Lake Formation account
his post shows how to access and manage data in multiple accounts from a central AWS Lake Formation account. The walkthrough demonstrates a centralized catalog residing in the master Lake Formation account, with data residing in the different accounts. The post shows how to grant access permissions from the Lake Formation service to read, write and update the catalog and access data in different accounts.

How ironSource built a multi-purpose data lake with Upsolver, Amazon S3, and Amazon Athena
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. This is a guest post co-written by Seva Feldman at ironSource Mobile and Eran Levy at Upsolver. ironSource, in their own words, is the leading in-app monetization and video advertising platform, making free-to-play and free-to-use possible for over 1.5B people around […]

Analyze Google Analytics data using Upsolver, Amazon Athena, and Amazon QuickSight
In this post, we present a solution for analyzing Google Analytics data using Amazon Athena. We’re including a reference architecture built on moving hit-level data from Google Analytics to Amazon S3, performing joins and enrichments, and visualizing the data using Amazon Athena and Amazon QuickSight. Upsolver is used for data lake automation and orchestration, enabling customers to get started quickly.
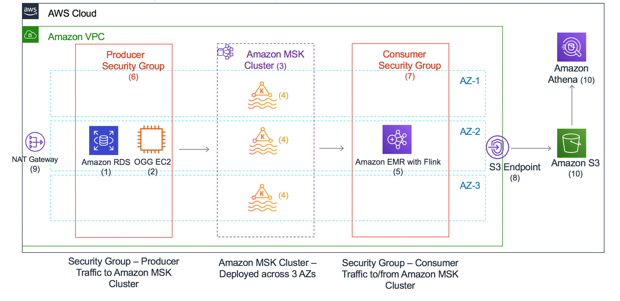
Extract Oracle OLTP data in real time with GoldenGate and query from Amazon Athena
This post describes how you can improve performance and reduce costs by offloading reporting workloads from an online transaction processing (OLTP) database to Amazon Athena and Amazon S3. The architecture described allows you to implement a reporting system and have an understanding of the data that you receive by being able to query it on arrival.
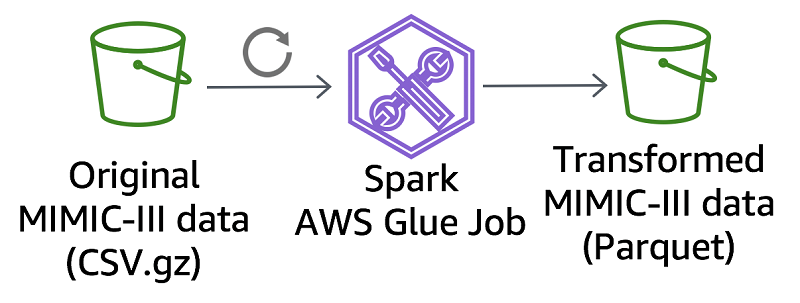
Perform biomedical informatics without a database using MIMIC-III data and Amazon Athena
This post describes how to make the MIMIC-III dataset available in Athena and provide automated access to an analysis environment for MIMIC-III on AWS. We also compare a MIMIC-III reference bioinformatics study using a traditional database to that same study using Athena.

Analyzing AWS WAF logs with Amazon OpenSearch, Amazon Athena, and Amazon QuickSight
This post presents a simple approach to aggregating AWS WAF logs into a central data lake repository, which lets teams better analyze and understand their organization’s security posture. I walk through the steps to aggregate regional AWS WAF logs into a dedicated S3 bucket. I follow that up by demonstrating how you can use Amazon ES to visualize the log data. I also present an option to offload and process historical data using AWS Glue ETL. With the data collected in one place, I finally show you how you can use Amazon Athena and Amazon QuickSight to query historical data and extract business insights.
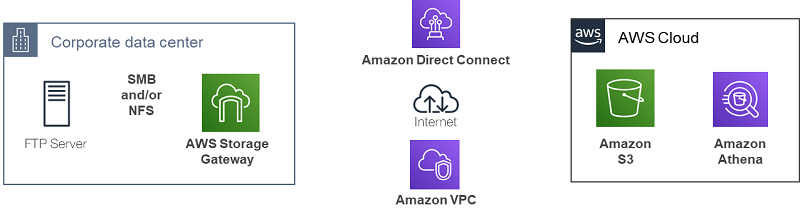
Query your data created on-premises using Amazon Athena and AWS Storage Gateway
In this blog post, I use this architecture to demonstrate the combined capabilities of Storage Gateway and Athena. AWS Storage Gateway is a hybrid storage service that enables your on-premises applications to seamlessly use AWS cloud storage. The File Gateway configuration of the AWS Storage Gateway offers you a seamless way to connect to the cloud in order to store application data files and backup images as durable objects on Amazon S3 cloud storage.