AWS Big Data Blog
Tag: Amazon S3
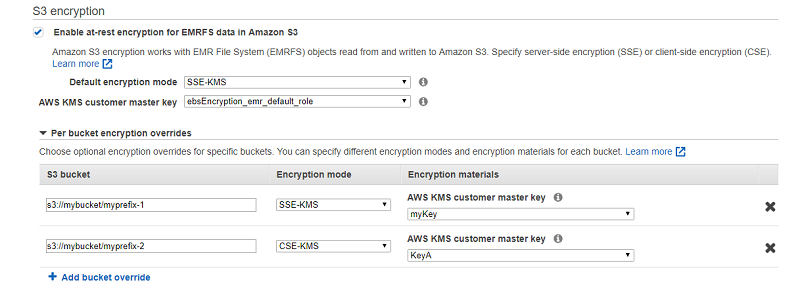
Secure your data on Amazon EMR using native EBS and per bucket S3 encryption options
This post provides a detailed walkthrough of two new encryption options to help you secure your EMR cluster that handles sensitive data. The first option is native EBS encryption to encrypt volumes attached to EMR clusters. The second option is an Amazon S3 encryption that allows you to use different encryption modes and customer master keys (CMKs) for individual S3 buckets with Amazon EMR.
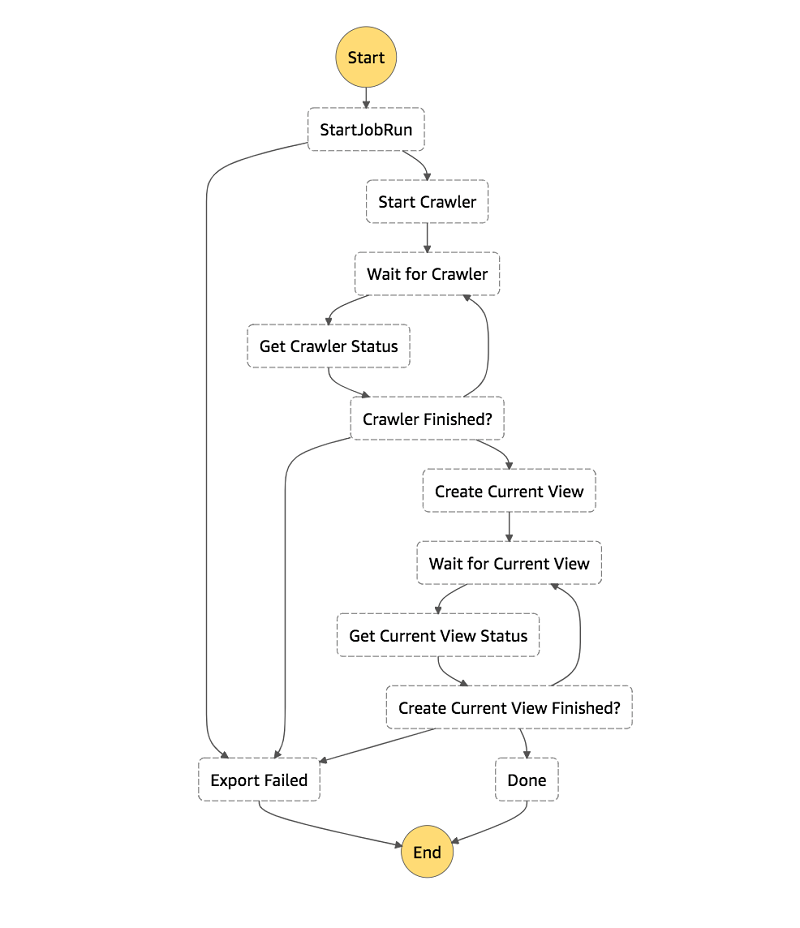
How to export an Amazon DynamoDB table to Amazon S3 using AWS Step Functions and AWS Glue
In this post, I show you how to use AWS Glue’s DynamoDB integration and AWS Step Functions to create a workflow to export your DynamoDB tables to S3 in Parquet. I also show how to create an Athena view for each table’s latest snapshot, giving you a consistent view of your DynamoDB table exports.

Trigger cross-region replication of pre-existing objects using Amazon S3 inventory, Amazon EMR, and Amazon Athena
In Amazon Simple Storage Service (Amazon S3), you can use cross-region replication (CRR) to copy objects automatically and asynchronously across buckets in different AWS Regions. CRR is a bucket-level configuration, and it can help you meet compliance requirements and minimize latency by keeping copies of your data in different Regions. CRR replicates all objects in […]

Improve Apache Spark write performance on Apache Parquet formats with the EMRFS S3-optimized committer
November 2024: This post was reviewed and updated for accuracy. The EMRFS S3-optimized committer is a new output committer available for use with Apache Spark jobs as of Amazon EMR 5.19.0. This committer improves performance when writing Apache Parquet files to Amazon S3 using the EMR File System (EMRFS). In this post, we run a performance […]
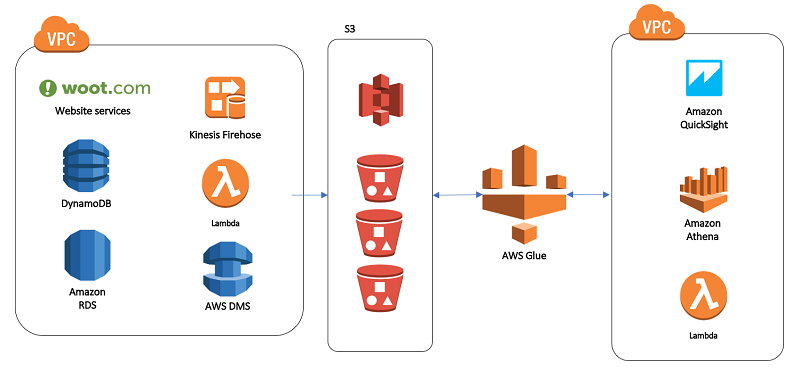
Our data lake story: How Woot.com built a serverless data lake on AWS
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. In this post, we talk about designing a cloud-native data warehouse as a replacement for our legacy data warehouse built on a relational database. At the beginning of the design process, the […]
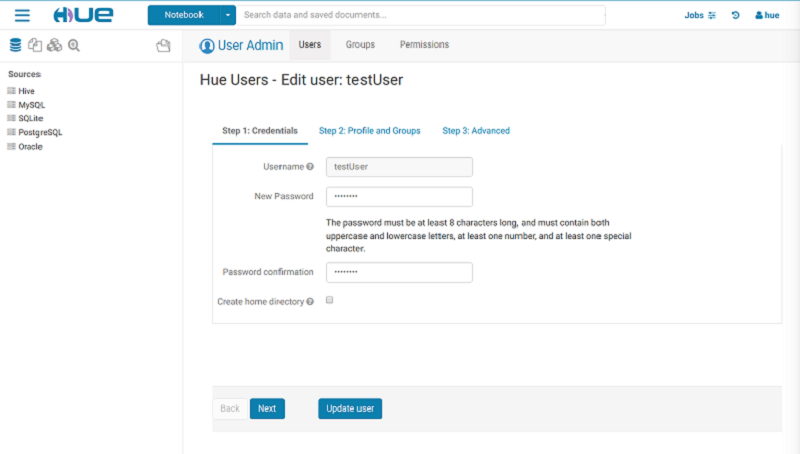
How to migrate a Hue database from an existing Amazon EMR cluster
This post describes the step-by-step process for migrating the Hue database from an existing EMR cluster.

Best Practices for Running Apache Kafka on AWS
The best practices described in this post are based on our experience in running and operating large-scale Kafka clusters on AWS for more than two years. Our intent for this post is to help AWS customers who are currently running Kafka on AWS, and also customers who are considering migrating on-premises Kafka deployments to AWS.
Best Practices for Running Apache Cassandra on Amazon EC2
In this post, we outline three Cassandra deployment options, as well as provide guidance about determining the best practices for your use case.

Build a Multi-Tenant Amazon EMR Cluster with Kerberos, Microsoft Active Directory Integration and IAM Roles for EMRFS
In this post, we will discuss what EMRFS authorization is (Amazon S3 storage-level access control) and show how to configure the role mappings with detailed examples.

Dynamically Create Friendly URLs for Your Amazon EMR Web Interfaces
This solution provides a serverless approach to automatically assigning a friendly name for your EMR cluster for easy access to popular notebooks and other web interfaces.