AWS DevOps Blog
Tag: Best practices

Best practices for managing Terraform State files in AWS CI/CD Pipeline
Introduction Today customers want to reduce manual operations for deploying and maintaining their infrastructure. The recommended method to deploy and manage infrastructure on AWS is to follow Infrastructure-As-Code (IaC) model using tools like AWS CloudFormation, AWS Cloud Development Kit (AWS CDK) or Terraform. One of the critical components in terraform is managing the state file which […]

Strategies to optimize the costs of your builds on AWS CodeBuild
AWS CodeBuild is a fully managed continuous integration service that compiles source code, runs tests, and produces ready-to-deploy software packages. With CodeBuild, you don’t need to provision, manage, and scale your own build servers. You just specify the location of your source code and choose your build settings, and CodeBuild will run your build scripts […]

Hazard analysis and Chaos engineering at Vanguard Group
Anticipating events that can cause a disruption to your system’s service is critical to building highly available, reliable systems. Hazard analysis gives you a method to identify such events. Chaos engineering gives you a method to confirm that a system behaves as expected in adverse conditions. By combining these methods, Vanguard is building reliability into […]

Improve the performance of Lambda applications with Amazon CodeGuru Profiler
Amazon CodeGuru Profiler recently began providing recommendations for applications written in Python. Additionally, the new automated onboarding process for Lambda functions makes it even easier to use CodeGuru Profiler with serverless applications built on Lambda. This post highlights these new features by explaining how to set up and utilize Codeguru Profiler on an AWS Lambda function written in Python.

Deploy data lake ETL jobs using CDK Pipelines
This post is co-written with Isaiah Grant, Cloud Consultant at 2nd Watch. Many organizations are building data lakes on AWS, which provides the most secure, scalable, comprehensive, and cost-effective portfolio of services. Like any application development project, a data lake must answer a fundamental question: “What is the DevOps strategy?” Defining a DevOps strategy for […]
Best practices for developing cloud applications with AWS CDK
April 20, 2022: Updates are available in the Best practices topic of the AWS CDK documentation. The documentation is the most up-to-date resource going forward. In this post, we discuss strategies for organizing the development of complex cloud applications with large teams, using the AWS Cloud Development Kit (AWS CDK) as a central technology. AWS […]

Improving AWS Java applications with Amazon CodeGuru Reviewer
Amazon CodeGuru Reviewer is a machine learning (ML)-based AWS service for providing automated code reviews comments on your Java and Python applications. Powered by program analysis and ML, CodeGuru Reviewer detects hard-to-find bugs and inefficiencies in your code and leverages best practices learned from across millions of lines of open-source and Amazon code. You can […]
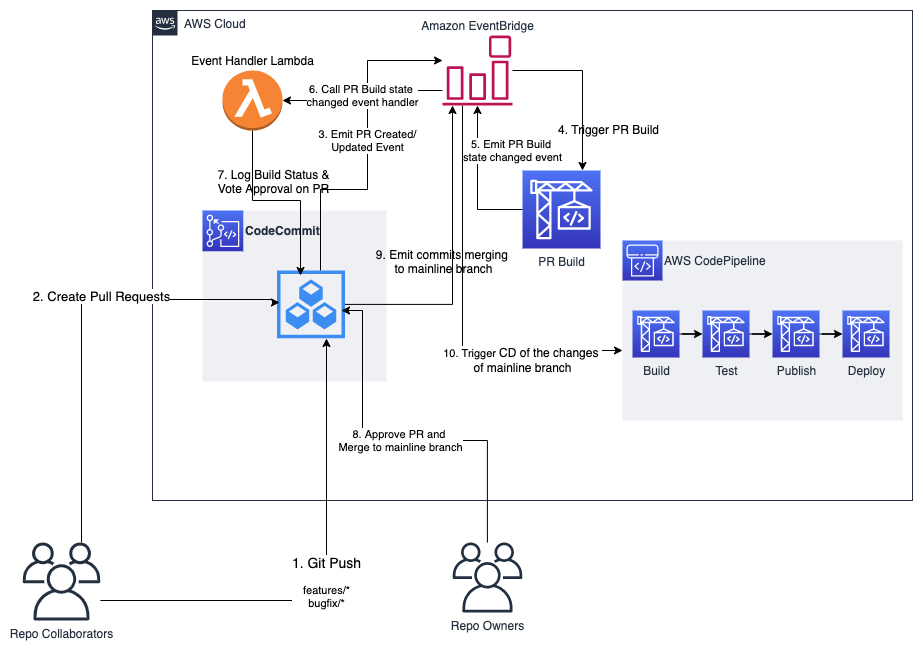
Scalable agile development practices based on AWS CodeCommit
Development teams use agile development processes based on Git services extensively. AWS provides AWS CodeCommit, a managed, Git protocol-based, secure, and highly available code service. The capabilities of CodeCommit combined with other developer tools, like AWS CodeBuild and AWS CodePipeline, make it easy to manage collaborative, scalable development process with fine-grained permissions and on-demand resources.

Identifying and resolving security code vulnerabilities using Snyk in AWS CI/CD Pipeline
The majority of companies have embraced open-source software (OSS) at an accelerated rate even when building proprietary applications. Some of the obvious benefits for this shift include transparency, cost, flexibility, and a faster time to market. Snyk’s unique combination of developer-first tooling and best in class security depth enables businesses to easily build security into […]

Transforming DevOps at Broadridge on AWS
with Tom Koukourdelis (Broadridge – Vice President, Head of Global Cloud Platform Development and Engineering), Sreedhar Reddy (Broadridge – Vice President, Enterprise Cloud Architecture) We have seen large enterprises in all industry segments meaningfully utilizing AWS to build new capabilities and deliver business value. While doing so, enterprises have to balance existing systems, processes, tools, […]