AWS for Industries
Building a privacy-first contextual-intelligence solution for advertising on AWS
Introduction
Advertisers and ad publishers have traditionally relied on third-party cookies, device identifiers, and enriched data from data-management platforms to deliver personalized experiences based on user preferences. With the deprecation of third-party cookies planned for early 2024, changes in device identifiers, and more stringent privacy laws (such as the General Data Protection Regulation [GDPR] and the California Consumer Privacy Act [CCPA]), it becomes challenging to understand customer preferences and behavior. This blog post describes how to use audience interest, gathered from consumed content, to target audiences without the use of third-party cookies. The blog includes a reference architecture, a review of different solution components, and a link to sample code for getting started on contextual insights using machine learning (ML) capabilities.
Evolving advertising addressability through privacy by default
In the Third-party cookies are going away: What should retailers do about it? blog post, Amazon Web Services (AWS) industry experts discuss first-party and third-party cookies and what retailers could do to build a first-party data platform. There are a number of initiatives that provide guidelines for privacy-first advertising solutions, such as Project Rearc by IAB Tech Lab. Project Rearc aims to build systems and standards that preserve addressability with consumer privacy and security at the heart. It describes different approaches, including seller-defined audiences, that allow publishers, data-management platforms, and data providers to scale first-party data responsibly and reliably without data leakage.
There are five important questions that inform an advertisement bid request: what, where, when, how, and why. With the absence of third-party cookies, what and why are unknown. These two questions identify target audiences and significantly influence the personalized experience. As shown in the diagram below, contextual intelligence helps inform advertisers on what and why using the advancements in computer vision and natural-language processing capabilities. Companies can extract contextual metadata and then use it to inform the ad bid request. Advertisers create targeted campaigns for specific audience segments, and the contextual ad request is matched with campaign goals.
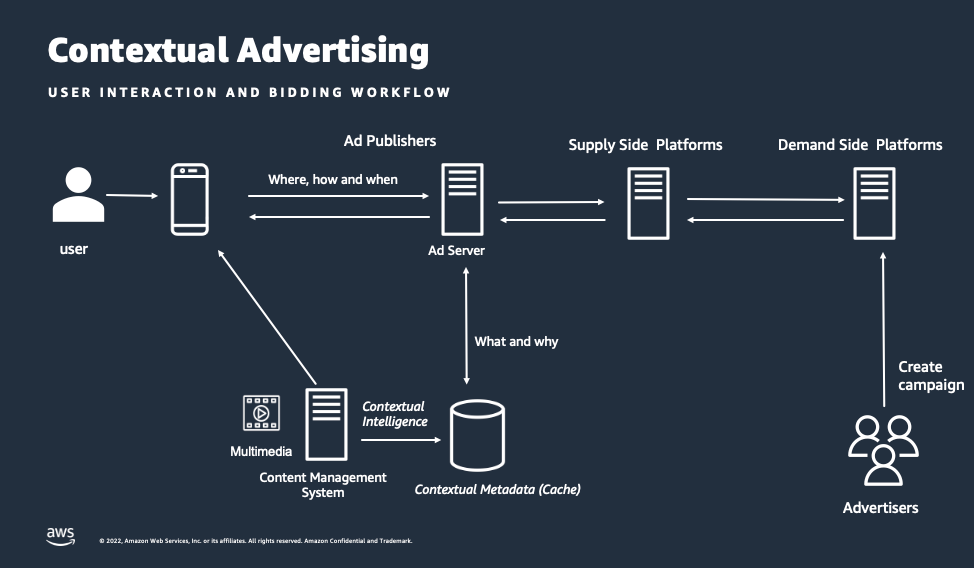
Figure 1.
Contextual advertising use cases
Before we talk about the solution, let’s look at the third-party-environment impact and some contextual targeting use cases. At the time of writing, Google and Apple combined have a browser market share of 85 percent according to StatCounter. When third-party cookies are deprecated by those browser companies, it will mean around 85 percent of the page views might not generate behavioral insights, and an alternative approach of contextual signals in combination with first-party data is needed to reach target audiences.

Figure 2.
At the same time, ad publishers need alternate ways to better monetize their content to get higher cost per thousand impression (CPM). Now, let’s look at some of the contextual advertising use cases.
Reaching anonymous audiences
Seller-defined audiences can be enhanced with a combination of first-party data and contextual signals that use the content consumed, instead of aggregating and normalizing data points across publisher domains. Contextual signaling can be useful for both ad publishers and advertisers. In the absence of third-party cookies, ad publishers can use contextual metadata to generate higher CPMs, and advertisers can reach the target audience that they couldn’t reach previously due to privacy regulations. For any contextual-targeting solution, it’s important to classify the content for creating audience segments. Also, using industry-standard taxonomies can reduce conversion overhead across different systems and parties as well as create more value for both the ad buyers and sellers. Using contextual signals can bring more value for ad publishers to monetize audience segments.
Brand safety
A well-known use case for contextual signals is brand safety. Advertisers want to ensure that the ads get placed on content that doesn’t negatively impact their brand value. The technical challenge is understanding the context in real time for the large volume of content available on the internet. The contextual-intelligence solution can map your content to a standard content taxonomy (such as IAB) or your own custom taxonomy to understand brand safety. The content-taxonomy information is used to inform an advertiser about the content. Advertisers can create campaigns with rules to filter the content that doesn’t match with their brand value. To read more about brand safety in advertising, you can go to IAB brand safety. Some of the IAB categories (provided by contextual signals) that can inform about brand safety include death, injury, substance abuse, adult content, politics, arms and ammunitions, and others. You can find the list of categories added in the content taxonomy for brand safety in the IAB press release article.
Connected TV
Contextual advertising also presents an important opportunity for connected TV (CTV). In 2022, an eMarketer article mentioned that CTV will account for more than one-fifth of total programmatic video ad spending. For advertising purposes, CTV uses contextual signals of the content along with device ID, IP address, and more; however, cookies are not available. As an example, think of a movie scene in which an actor or actress is driving a car to reunite with their family. The driving scene would typically be a couple of minutes. If ML can be used to detect the driving scene with a car, identify the logo of the manufacturer and other associated metadata (such as sentiment), you can place a targeted ad within the time frame of the driving scene. Ad publishers can create a catalog of metadata for each video to define audience segments. Another challenge with contextual ads for video streaming is that context is bound within a scene, and when the scene changes, context changes. This makes placement of ads as important as identifying the ad. It is possible that the same video can have a nursing scene appropriate for a diaper ad placement and can also have an explicit scene not suitable for ads. If you are interested in how an ad can be inserted into your content, read the How to implement reliable dynamic ad insertion using AWS Media Services blog.
Let’s discuss how you can build a contextual-intelligence solution on AWS for generating advanced contextual insights on news articles, podcasts, video on-demand, and other media assets. In this blog, we talk about identifying contextual metadata from your content to decorate ad bid requests.
Building a contextual-intelligence solution for advertising on AWS
Programmatic advertising requires low latency (under 20 ms) and highly scalable and cost-effective solutions. We have developed an event-driven architecture that uses serverless services that make it cost effective and can scale to millions of requests, and you pay only when an ad request is served. These services include
- AWS Step Functions, a visual workflow service that helps developers use AWS services to build distributed applications, automate processes, orchestrate microservices, and create data and (ML) pipelines;
- AWS Lambda, a serverless, event-driven compute service that lets you run code for virtually any type of application or backend service without provisioning or managing servers; and
- Amazon DynamoDB, a fully managed, serverless, key-value NoSQL database designed to run high-performance applications at nearly any scale.
Solution components
In figure 3 below, we depict the overall architecture. The architecture consists of six high-level components.
Typically, ad publishers (1) have a content management system (CMS) or content repository that contains the content (such as video, webpages, and podcasts.). The content-discovery (2) component discovers the content to store assets (such as videos, images, text, and audio files) on a cost-effective data store. In our example, we used a web crawler (3) to discover the content. The discovered content is stored on Amazon Simple Storage Service (Amazon S3), an object storage service (4), for processing. After the content is available on Amazon S3, it initiates an asynchronous workflow in the controller (5) component. The controller component initiates the content-analysis (6) component to extract metadata for all the files on Amazon S3. After the content analysis is complete, the controller gets notified through an event. It then initiates a process to map extracted metadata to an IAB content taxonomy using the Contextual Intelligence Taxonomy Mapper (CITM) (8). After the mapping is identified, IAB categories and metadata are stored in the category service (9) database. Each piece of content is referred to as an asset that has an asset ID, associated metadata, and IAB categories. When a bid request (10) is placed, a transient identifier (short-lived identifier) that’s mapped to asset ID is provided in the bid. When advertisers need more information about the asset, category service provides associated IAB categories for the transient identifier. This helps ad publishers keep the exclusive information about asset mapping to IAB categories while providing necessary information to advertisers to place an ad. Ad publishers can reuse the metadata and IAB categories for real-time bidding, until there are changes to the content or they have updated ML models to extract more metadata. This makes it highly cost-effective to place different ads using the same metadata over time.
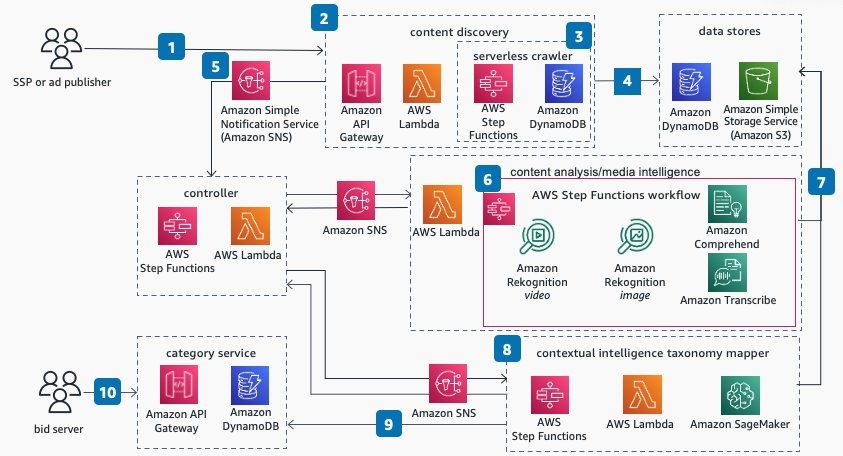
Figure 3. Contextual-intelligence solution for advertising reference architecture
Content discovery
The content discovery gets initiated whenever new content is available at the content source (such as a website, CMS, and others). You can use CMS plugins, web crawlers, or any other method to discover content. In the reference architecture, we used a crawler mechanism to get content from websites. If you want to use a crawler to get content from websites, read this blog post on Scaling up a Serverless Web Crawler and Search Engine. You would need to adjust the crawler business logic to filter unrelated content on webpages. A better approach is to use CMS integration to fetch content from webpages. When using crawlers, you can use HTML structure to identify the relevant text, images, and videos.
Data stores
After you have discovered the content, you can store it on cost-effective storage, such as Amazon S3, and keep multiple assets to a webpage relationship in a flexible schema database, such as Amazon DynamoDB. During content analysis, it’s important to have the data organized by media type to apply relevant ML algorithms to extract metadata. You need to have all text-related files within an Amazon S3 prefix to apply Amazon Comprehend, a natural-language processing service that uses ML, to analyze text in all files. Similarly, having all audio and video files within separate Amazon S3 prefixes for audio and video ensures related media types are grouped and can be easily referenced for processing by different AWS services. The relationship between content (for example, webpages) and assets (for example, text, image, audio, and video) is stored in Amazon DynamoDB to keep the overall context of a content together. You can enrich the information in Amazon DynamoDB table with other metadata, such as existing HTML tags, URLs, time stamps, and other data.
Controller/orchestrator
The controller is designed to orchestrate content analysis for different media types using different AWS services. AWS Step Functions provides a serverless state machine to manage workflow of content analysis. Topics in Amazon Simple Notification Service (Amazon SNS), a fully managed Pub/Sub service for A2A and A2P messaging, provides an asynchronous communication method to pause and resume the state machine as the content analysis completes for different media types, making it cost-effective. It optimizes resource usage and uses compute only when state machine is running. You can run analysis for different media types in parallel, optimizing the overall duration, and manage failures independently. The decoupled design also allows for changes to any subcomponent without impacting the workflow and facilitates running content analysis for a particular media type, such as image or audio, instead of running it for all media types. This makes it more cost-effective to rerun workflows in the case of updates to specific parts of the content.
Content analysis
Content-analysis components use AWS Media Intelligence (AWS MI), a combination of services that empower you to easily integrate artificial intelligence (AI) into your media-content workflows, to design guidelines to generate insights. It uses Amazon AI services for content analysis as follows:
- Amazon Rekognition, offering pretrained and customizable computer vision capabilities to extract information and insights from your images and videos for analysis of images and video;
- Amazon Transcribe, which automatically converts speech to text; and
- Amazon Comprehend for natural-language understanding of the text.
Together the services provide valuable insights into objects, actions, sentiment, context, places, activities, and more. AWS AI services provide trained ML models, making it easy to use and cost-effective due to the reuse of large pretrained models. For more detail on how the solutions use AI and ML services for content analysis, you can read the Build taxonomy-based contextual targeting using AWS Media Intelligence and Hugging Face BERT blog post. It describes how to use Amazon Comprehend and Amazon Rekognition to extract metadata and then map the media assets (text, image, audio, and more) to IAB content taxonomy. It also provides sample code that you can use to get started on a proof of concept.
Contextual Intelligence Taxonomy Mapper (CITM)
After you have extracted metadata from media assets, you need to map it to a standard taxonomy to inform advertisement bid requests. This requires you to build an ML technique that maps metadata from media assets to taxonomy terms without losing the context. For this purpose, we developed the CITM to map the metadata generated during content analysis to a standardized content taxonomy. It uses a deep learning ML algorithm that is specifically designed to represent contextual meaning within text. Because the metadata from content analysis is in the form of text, CITM contextually maps that text to the taxonomy. For example, it can map metadata tags from a video segment about healthy cooking to keywords from the industry taxonomy, such as “Healthy Cooking and Eating” and more, based on the items seen in the video and the topics discussed in the video’s audio. If you are interested in more details on how CITM works, you can read on Build taxonomy-based contextual targeting using AWS Media Intelligence and Hugging Face BERT blog post. You can also choose to map extracted metadata to your own taxonomy. The content-analysis and contextual-intelligence taxonomy mapper components of the solution can be initiated on-demand whenever content is updated, or when the ML algorithm for the content analysis changes.
Category service
Once you have extracted contextual metadata in the form of standard taxonomy, you can store it for the programmatic bidding process. The other information about the content, such as URL, unique ID, and others, can be stored along with contextual metadata and IAB categories. You can use a flexible schema table (such as Amazon DynamoDB table) to store this information and can scale to serving millions of requests per second. To provide near-real-time performance, you can use a combination of Amazon API Gateway—in which developers can create, maintain, and secure APIs at nearly any scale—and an AWS Lambda function to query the Amazon DynamoDB table to decorate the bid request.
The category service also acts as a caching layer for the contextual signals on the content. This decouples the process of analyzing the content from serving bid requests. A single content analysis can serve many bid requests for a content until the content changes or you need to extract more metadata. This improves the value generated from performing content analysis because ad publishers can place ads for different ad requests without having to extract metadata again and again. Most of the cost of running the solution comes from content analysis, but the scale and reusability of metadata makes it cost effective.
Example: Contextual metadata for a video
Now that we have discussed the solution components, let’s see how the solution works for a CTV use case. In this example, we analyze a sample video and show how CITM categorizes video content into IAB categories.
Let’s take a video, Meridian, from the Netflix Open Content repository. We selected a 45-second clip in the video where two crime investigators are discussing the evidence available for a case. We capture both the scene’s physical setting and the characters’ speech for contextual analysis.
Below is a shot from the scene as well as subtitles from the characters’ speech:

So these guys just disappeared?
Yeah, on that stretch of road right above El Matador. You know it?
With the big rock?
That’s right. Yeah.
Mickey Cohen used to take his associates out there … bid ‘em a bon voyage.
Mob hits? Nah, not this time. One of these guys is a school teacher. Next guy, he sold insurance. Last guy, he was retired.
Any connection?
Mm-mmm. I mean, I checked them all out. There’s no criminal records. No association in any criminal organizations. One of the guys was arrested for drunk driving a long time ago … They were all divorced.
Using the solution, Amazon Rekognition analyzes visual content, and Amazon Transcribe provides a text file with a transcript of the audio. After analyzing the transcript using Amazon Comprehend, it detects key phrases from the characters’ speech. Some examples of detected phrases include El Matador and drunk driving. For visual analysis, let’s look at just one frame (shown above) because there are minimal shot changes in the scene. We use Amazon Rekognition to detect object labels for items in the frame. It detects two object labels: apparel and accessories.
Now, CITM maps all the keywords in characters’ speech and object labels from the physical scene to content taxonomy. This means mapping El Matador, drunk driving, apparel, and accessories to IAB taxonomy categories. CITM maps the keywords to the following categories in the content taxonomy: crime news and political crime, roadside assistance, and auto safety. CITM maps the detected-object labels to the following IAB categories: apparel industry and travel accessories. The crime news and political crime category can inform brand-safety needs for an advertiser, and the auto safety category can inform advertisers about an opportunity to target the audience with an auto insurance ad.
Conclusion
In this blog post, you learned how contextual targeting can be an effective alternate solution in the absence of third-party cookies and inform ads for CTV. You learned about a reference architecture that can be used to get started on a proof of concept for your contextual-targeting use cases. You also learned how AWS serverless and AI services make it cost-effective and highly scalable to meet programmatic advertising requirements. If you are looking to build a contextual-targeting solution, you can reach out to your AWS Account team to engage the AWS Advertising & Marketing technical community.
Learn more about this solution on the AWS Solutions Library and see all solutions for advertising and marketing.