AWS for Industries
Building Blocks for Modern Retail Ecommerce and Media Search With AWS
The challenge and value of online discovery
The power of cloud elasticity helps online retailers expose large volumes of digital content catalogs for shoppers to browse and purchase products. However, it’s a challenge for many retailers to manage their vast online catalogs. And at the same time, with so much content, customers can become overwhelmed or miss products that they didn’t realize were available.
This conundrum leads to an important question: How can retailers easily manage a large catalog and provide shoppers with effortless product visibility while matching relevant items with shopper intent?
The answer: retailers should use a search system to help customers discover items that match their interests to increase online sales and boost customer satisfaction.
Here are a few interesting stats to validate this thought:
- According to Sorokina and Cantú-Paz in “Amazon Search: The Joy of Ranking Products,” the majority of Amazon sales come from Amazon Search.
- In the article “Machine Learning–Powered Search Ranking of Airbnb Experiences,” Mihajlo Grbovic et al. found through an A/B testing experiment that a machine learning (ML)–based search algorithm increased bookings by more than 13 percent compared to a random ranking baseline approach.
- Jewel James wrote in “The Secret Sauce Behind Search Personalisation“ that Gojek observed a more than 20 percent search-to-order conversion on its GoFood service using A/B testing driven by personalized search ranking.
- According to the article “Bringing Personalized Search to Etsy,” Lucia Yu said users “click around less with personalized results, index to fewer pages, and buy more items compared to the control model.”
For business owners, search comes with many challenges, such as
- how to match structured product data to natural text queries with grammatical errors in various languages;
- how to rank results to achieve business goals, such as click-through rates (CTR) and conversions;
- how to adapt results to the specific context of a user session; and
- how to keep infrastructure costs under control.
At a high level, a search system is composed of three modules: query handling, matching, and ranking. Each of these modules include an online component to serve user requests and an offline workflow that keeps the online component up to date. Traditional search engines based on inverted indexes and lexical matching have been delivering value for decades. However, modern ML techniques take search to the next level by adding a deeper understanding of user queries and preferences to deliver a more relevant, personalized search experience. In this blog post, we’ll explain the building blocks of a modern search system in the context of the three modules. We will also showcase the services from Amazon Web Services (AWS) that support a scalable, secure, and cost-effective search functionality.

I. Query handling
The purpose of query auto-completion is to propose full and detailed queries based on what the user types into the search bar. Longer, more detailed queries increase the likelihood of relevant matches. From an ML perspective, auto-complete queries can be viewed as a text generation challenge. With a few characters, the system has to predict the entire query. Due to low-latency requirements, generating suggested queries has traditionally relied on precomputed, in-memory lookup mechanisms (“Auto-Complete for Improving Reliability on Semantic Web Service Framework,” Jung et al.). More recently, however, real-time natural language models trained with historical queries have become more popular, as described in “Personalized Neural Language Models for Real-World Query Auto Completion” (Fiorini and Lu) and “Realtime Query Completion via Deep Language Models” (Wang et al.). Furthermore, because shoppers usually look at the first few suggestions, as observed in “An Eye-Tracking Study of User Interactions with Query Auto Completion,” by Hoffman et al., it is crucial to rank the final suggestions by relevance based on contextual and behavioral features. This step is usually implemented as a shallow ML model (see an example in “Deep Pairwise Learning to Rank for Search Autocomplete,” Wang and Huang).
According to an article by Cucerzan and Brill, more than 10 percent of search engine queries are misspelled. A standard query correction approach is to rewrite input tokens with variants that are close according to edit distance and then rank the entire query likelihood. The ranking and classification steps are both framed as ML problems with features, such as language fluency, pronunciation similarity, and keyboard character distance. The last step is to decide whether to substitute the top candidate query or not. Alternatively, some modern spelling correction modules rely on complete deep learning (DL) architectures, such as denoising encoder-decoder networks as noted in Kuznetsov and Urdiales and Etoori et al., or sequence-to-sequence models, such as the T5 transformer mentioned by Amazon scientists in “How Amazon Search achieves low-latency, high-throughput T5 inference with NVIDIA Triton on AWS” (RJ et al.).
The attribute extraction module helps the search query to be understood, which improves search quality and efficiency by routing requests to only relevant index shards. This module usually has lexical processing steps to produce canonical forms of search terms and a semantic parsing step to understand the meaning of the terms. The latter can be framed as a multilabel classification or a named-entity recognition ML problem (Gupta et al.). For example, Ibotta says it uses BlazingText from Amazon SageMaker—which companies use to build, train, and deploy ML models for virtually any use case—to classify the product category related to a search query according to the article “Powering a search engine with Amazon SageMaker.”
The AWS Cloud provides strong support for the training and inference of custom natural language processing (NLP) models. Amazon Comprehend, an NLP service that uses machine learning, provides auto-ML capacities to develop custom entity extraction and text classification models, and Amazon SageMaker provides full freedom on scientific code and helps developers to create custom training and inference scripts. In 2021, AWS notably added dedicated, managed containers and SDK classes for the Hugging Face NLP library, which is considered state of the art for deep-learning NLP. The managed intelligent search service Amazon Kendra, an intelligent search service powered by ML, and the managed search service Amazon OpenSearch Service—which makes it easy to perform interactive log analytics, real-time application monitoring, website search, and more—both come with query auto-completion included.

II. Matching
The goal of matching is to reduce the size of the search space from millions of documents to a few thousand potentially relevant documents. Various types of matching exist, including lexical matching as well as ML-based matching with behavioral and semantic aspects.
Lexical matching
To find a product in a catalog, scanning and reading through every item would be a computationally expensive operation. Instead, search engines, like Apache Lucene, which underpins Elasticsearch and Amazon OpenSearch Service, use an inverted index to easily find products or documents that include a specific term or keyword. You can refine search queries by using different constraints in the match expression—for example, logical expressions like “and” or “or.” Lexical search has two limitations: (1) it matches product-related text, like title or product page, which may not correlate with customer preferences or long-term business metrics, and (2) it has limited robustness to syntactical variations, like hypernyms, synonyms, antonyms, and plurals, as well as query token order. To bypass these issues, it is possible to learn a matching function.
ML-based matching
ML-based matching can be roughly divided into two mutually nonexclusive paradigms: behavioral and semantic matching. Behavioral matching tries to associate queries with past user behavior. For example, if a query was associated with a specific product purchase or media content request in a current or past user session, it makes sense to return this item again in subsequent similar queries. On the other hand, semantic matching tries to bring humanlike understanding to matching, using generic language modeling techniques and may not need behavioral data. For example, the AWS blog “Building an NLU-powered search application with Amazon SageMaker and the Amazon OpenSearch Service KNN feature” showcases an instance of semantic matching using BERT pretrained sentence embeddings. Semantic search is helpful in subjective queries (“best running shoes”) and functional queries (“award-winning movies,” “winter camping equipment”).
You can implement a behavior or semantic ML-based matching algorithm in many ways. Similarity learning and extreme multilabel classification are popular implementation techniques. Although many articles also describe the use of knowledge graphs to precompile similarity maps, we will not cover them in this blog post.
K-nearest neighbors algorithm in metric space
In metric matching, a model is trained to represent queries and products in a vector space, and the relevance of products or documents to a search query vector is determined by a similarity function, such as cosine similarity or L2 distance. Representing search queries and products as dense vectors recasts the matching problem into a k-nearest neighbor (kNN) search. There are numerous techniques to learn appropriate dense vector representations, such as word2vec-like techniques (Hamad et al.) or Siamese networks with triplet or contrastive loss functions (Nigam et al.). To make kNN searches fast and scalable, it is common to use optimized, approximate nearest neighbor (ANN) libraries, such as FAISS, Annoy, or Hnswlib. This search design is documented by teams at Amazon (Nigam et al.), Monzo (Nigel Null), Microsoft Bing (Chakrabarti et al.), and Facebook (Huang et al.). AWS can support metric-matching workloads with these services:
-
- Amazon SageMaker—for custom representation learning models
- Amazon SageMaker kNN—for high-performance approximate kNN solutions
- Amazon OpenSearch kNN extension—for the HNSW algorithm and FAISS in OpenSearch 1.2

Multilabel classification
Search matching can also be framed as an extreme text classification problem, where the input is the query and the labels are the possible products. Amazon spearheads this innovative approach as described in the article “Prediction for Enormous and Correlated Output Spaces Framework.” Known as PECOS, this approach organizes the output space using a semantic indexing scheme that groups products into clusters. The indexing narrows the output space by orders of magnitude using an ML-based matching scheme to navigate through clusters. Finally, PECOS ranks the matched items using a final ranking scheme.
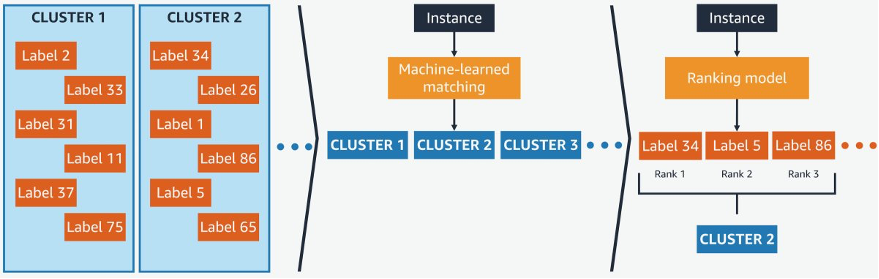
How PECOS works, from https://www.amazon.science/blog/applying-pecos-to-product-retrieval-and-text-autocompletion
Note: When using the managed intelligent search service Amazon Kendra, developers do not need to be highly skilled in matching science or query handling.
III. Personalization and ranking
Once the matching phase selects hundreds to thousands of items, a ranking system narrows the list of suggested items to the top K products shown to the user. Additionally, the ranking system can increase the relevancy and personalize the search results based on user preferences—for example, previous price range choices, user geolocation, or any available information on the customer’s preferred product category, such as movie genre or book format, like physical, ebook, or audible.

The task of ranking products from the match set can also be framed as an ML problem. In this case, there are several approaches to construct a product ranking function, including binary classification and learning to rank (LTR). In binary classification ranking, an ML model is trained to measure the relevance of a given document to a given query. The training data for such a model consists of context from the user query and properties of the product. Labels come from domain-specific interactions that indicate past measurements of query-item relevance. In retail ecommerce situations, which could be click, add-to-cart, or purchase events. In media, which could be clicks, content streams, and add-to-watch list/read list/play list events. At inference, the ranking is produced through sorting, by likelihood of interaction. For example, the article “Amazon Search: The Joy of Ranking Products” describes such ranking systems based on gradient boosting. On the other hand, LTR algorithms are trained to directly output a ranked list of items from an input list of features. LambdaMART (Burges) is a popular LTR algorithm, powering the ranking tasks in XGBoost (objectives rank:pairwise, rank:ndcg, and rank:map). Also in “Amazon Search: The Joy of Ranking Products,” the authors describe a gradient-boosting-based search ranking model using an NDCG objective.
From AWS, Amazon SageMaker supports training, tuning, and serving custom ranking models. Developers familiar with Amazon OpenSearch Service can also use its Learning to Rank extension to deploy search ranking models. Keep in mind that developing and maintaining ranking models requires scientific and engineering skills. To make state-of-the-art personalized ranking accessible to every developer, AWS proposes the Amazon Personalize-Ranking recipe, which generates personalized rankings of items. In addition to proposing an advanced, hierarchical recurrent neural network (HRNN)–based model, the Amazon Personalize-Ranking recipe automates the data engineering, including event ingestion, to learn each user’s intent in real time, feature engineering and serving. As an example, the Amazon Personalize-Ranking recipe is used in the AWS Samples Retail Demo Store. The sample application provides a reference architecture that uses the Amazon Personalize-Ranking recipe with Amazon OpenSearch Service to personalize the order of products displayed in an auto-complete user interface (UI) widget.
Wide variety of services to meet your search needs
A search system is a huge benefit to both retailers and shoppers, and AI is modernizing search at all levels with robust automation and relevance. Per the table below, AWS offers many services to support the three components of a search system: query handling, matching, and ranking. Your account team can help you select the best services for your needs based on cost, speed, scale, science, and other parameters.

AWS is here to help your company achieve your strategic goals with robust automated search capabilities. If you’d like to discuss your search needs, contact your account team today.