Artificial Intelligence
Category: Artificial Intelligence

Object detection with Amazon Nova 2 Lite
In this post, we’ll walk through implementing object detection with Amazon Nova 2 Lite. You’ll learn how to deploy an object detection application using Amazon Bedrock, AWS Lambda, and Amazon API Gateway. You’ll also learn how to craft effective prompts, process structured JSON output, and visualize results. We explore practical applications across manufacturing, agriculture, and logistics.

How Baz improved its AI Agent Code Review accuracy using Amazon Bedrock AgentCore
This post walks through how Baz built their Spec Review agent using Amazon Bedrock and Amazon Bedrock AgentCore. We’ll cover the architecture decisions, implementation details, and the business outcomes they achieved by leveraging these AWS services to automate their code review process
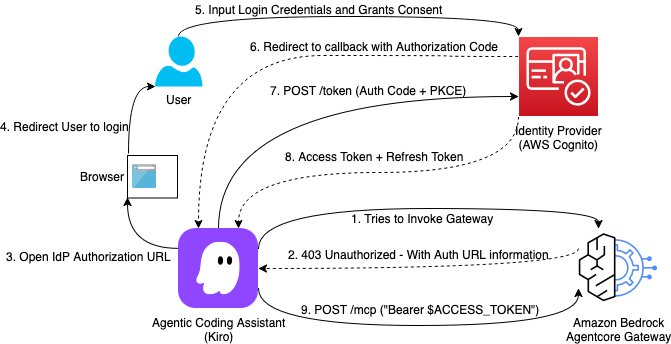
Building a secure auth code flow setup using AgentCore Gateway with MCP clients
This post demonstrates how to implement Open Authorization (OAuth) Code flow as an inbound authorization mechanism for MCP servers hosted on Amazon Bedrock AgentCore Gateway. By the end of this guide, you will have a production-ready setup where each AI assistant request is authenticated with a valid user identity token issued from your organization’s identity provider.

Reference your own AWS Secrets Manager secrets in Amazon Bedrock AgentCore Identity
Today, we’re excited to announce the ability to reference a secret in AWS Secrets Manager for AgentCore Identity, so you can reference your own preconfigured secret from Secrets Manager and retain full control over how it is managed. With this ability, you can extend your organization’s existing secrets governance processes to AgentCore. You can provide an existing, preconfigured AWS Secrets Manager secret to use with your credential provider resources. You retain full control over its encryption configuration, rotation, replication, tags, and resource policies, just as you would manage other secrets in Secrets Manager. You can also choose a secret from another AWS account within the same AWS Region, though cross-Region secret sharing isn’t supported. This also supports secrets brought in through AWS Secrets Manager external connectors, enabling integration with third-party secret managers.

Transforming rare cancer research with Amazon Quick: Integrating biomedical databases for breakthrough discoveries
In this post, we walk through how to use Amazon Quick Research to integrate biomedical data sources for rare cancer research. The walkthrough uses pediatric sarcoma as the research domain and draws on publicly available datasets from PubMed and other open biomedical repositories. It covers the end-to-end workflow: defining a research objective, configuring data sources, reviewing the AI-generated research plan, running the investigation, and iterating on results using the revision and versioning system.

OpenAI models and Codex on Amazon Bedrock are now generally available
GPT-5.5, GPT-5.4, and Codex are now generally available on Amazon Bedrock. Deploy them in production applications and agents today, on Bedrock’s high performance inference engine.

Extending MCP support for Amazon Bedrock AgentCore Gateway
While deploying Model Context Protocol (MCP) servers in production, enterprises need fine-grained access control across servers, observability into which teams use which tools, security guarantees against data exfiltration, and centralized credential management, all at scale. Amazon Bedrock AgentCore Gateway sits between MCP servers and the clients that consume them, centralizing credential management, observability, and secure […]

Secure AI agents with Policy and Lambda interceptors in Amazon Bedrock AgentCore gateway
In this post, we use a lakehouse data agent to demonstrate how you can use Policy for deterministic access control and Lambda interceptors for dynamic validation. We then show how to combine Lambda interceptors and Policy to implement a geography-based access control which requires both dynamic validation and deterministic access control.

Enable safe agentic payments with built-in guardrails using Amazon Bedrock AgentCore payments
In this post, we address several key risks that surface when designing an agentic payment system, and how to address them with the capabilities of AgentCore payments.

AgentOps: Operationalize agentic AI at scale with Amazon Bedrock AgentCore
When you build agentic AI solutions, you face unique operational challenges. Agents make unpredictable decisions, costs spiral unexpectedly, and debugging non-deterministic failures seems impossible. Agentic AI applications don’t just execute predetermined workflows. They reason, adapt, and make autonomous decisions, and DevOps practices need to be adapted. That’s where AgentOps comes in, the operational discipline for deploying, managing, and continuously improving AI agents in production.