Artificial Intelligence
Category: Artificial Intelligence

Generate dashboards from natural language prompts in Amazon Quick
Building meaningful dashboards demands hours of manual setup, even for experienced BI professionals. Amazon Quick now generates complete multi-sheet dashboards from natural language prompts, taking you from one or more datasets to a production-ready analysis in minutes. Data analysts building recurring operations reports, program managers preparing a leadership review, or engineers exploring a new dataset can […]
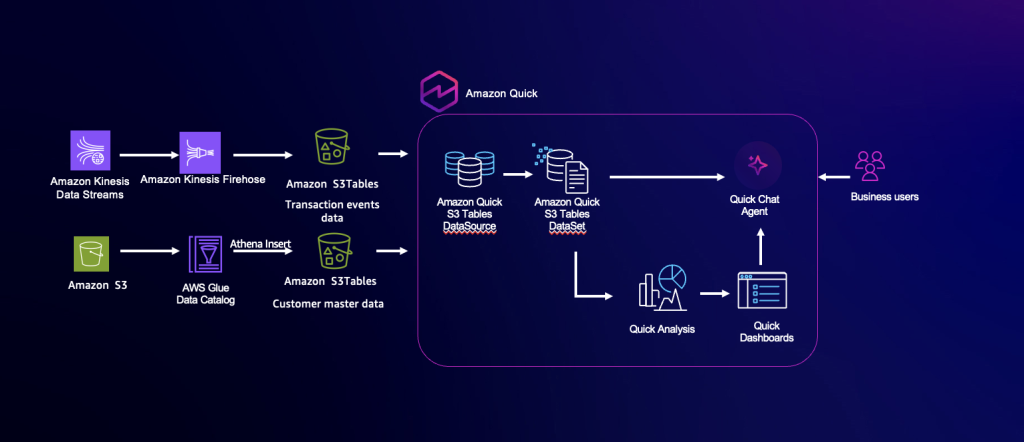
From data lake to AI-ready analytics: Introducing new data source with S3 Tables in Amazon Quick
Amazon Quick introduces Amazon S3 Tables (Apache Iceberg tables) as a new data source. With this feature, customers can directly query and visualize Apache Iceberg tables stored in an Amazon S3 table bucket without the need for intermediate data layers. In this post, we explored how Amazon Quick’s new Amazon S3 Tables data source enables near real-time analytics while streamlining modern data architectures.
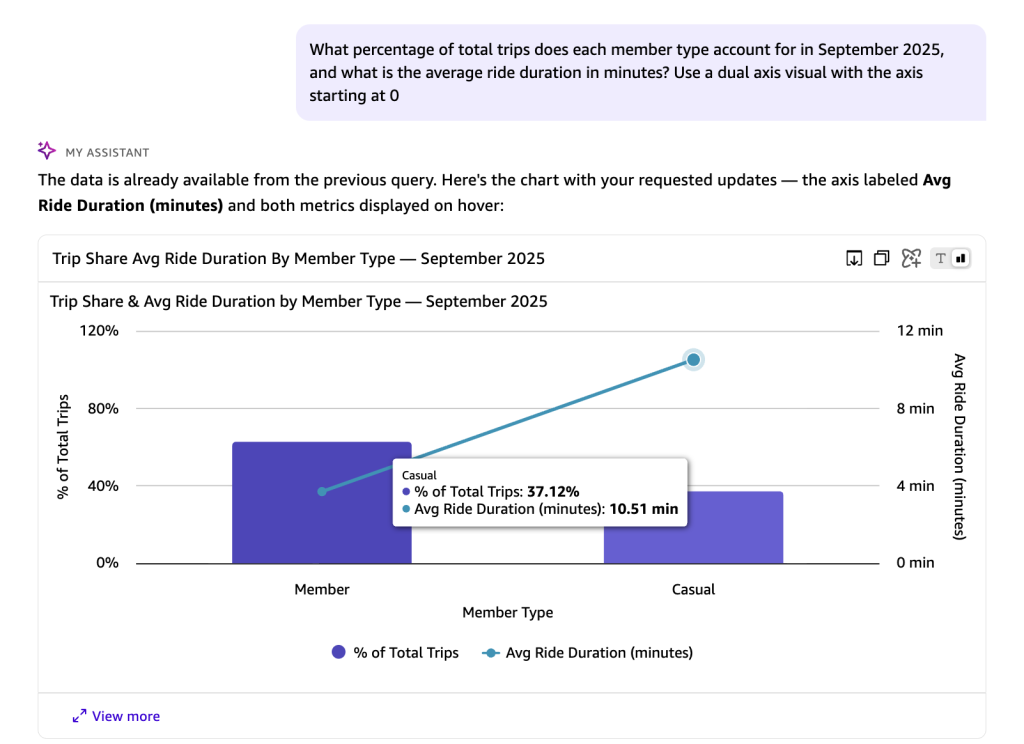
Introducing Dataset Q&A: Expanding natural language querying for structured datasets in Amazon Quick
In this post, you learn how to get started with Dataset Q&A, explore real-world use cases with hands-on examples, and discover advanced capabilities like auto-discovery across all your data assets and multi-dataset querying in a single conversation.

Capacity-aware inference: Automatic instance fallback for SageMaker AI endpoints
Today, Amazon SageMaker AI introduces capacity aware instance pool for new and existing inference endpoints. You define a prioritized list of instance types, and SageMaker AI automatically works through your list whenever capacity is constrained at creation, during scale-out, and during scale-in. Your endpoint provisions on available AI Infrastructure without manual intervention. This capability is available for Single Model Endpoints, Inference Component-based endpoints, and Asynchronous Inference endpoints.

AWS Transform now automates BI migration to Amazon Quick in days
In this post, we walk through the full journey, from setting up your migration workspace in AWS Transform to subscribing to partner agents through AWS Marketplace to unlocking Amazon Quick capabilities that change how your organization consumes data.

Reinforcement fine-tuning with LLM-as-a-judge
In this post, we take a deeper look at how RLAIF or RL with LLM-as-a-judge works with Amazon Nova models effectively.
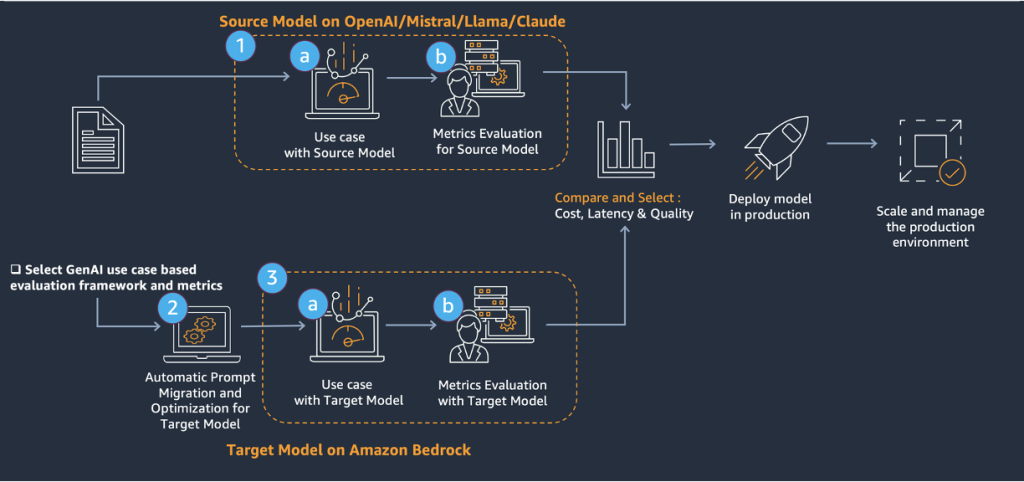
AWS Generative AI Model Agility Solution: A comprehensive guide to migrating LLMs for generative AI production
In this post, we introduce a systematic framework for LLM migration or upgrade in generative AI production, encompassing essential tools, methodologies, and best practices. The framework facilitates transitions between different LLMs by providing robust protocols for prompt conversion and optimization.

Sun Finance automates ID extraction and fraud detection with generative AI on AWS
In this post, we show how Sun Finance used Amazon Bedrock, Amazon Textract, and Amazon Rekognition to build an AI-powered identity verification (IDV) pipeline. The solution improved extraction accuracy from 79.7% to 90.8%, cut per-document costs by 91%, and reduced processing time from up to 20 hours to under 5 seconds. You’ll learn how combining specialized OCR with large language model (LLM) structuring outperformed using either tool alone. You’ll also learn how to architect a serverless fraud detection system using vector similarity search.

Unleashing Agentic AI Analytics on Amazon SageMaker with Amazon Athena and Amazon Quick
This post demonstrates how agentic AI assistant from Amazon Quick transform data analytics into a self-service capability by using Amazon Simple Storage Service (Amazon S3) as a storage, Amazon SageMaker and AWS Glue for lakehouse, Amazon Athena for serverless SQL querying across multiple storage formats (S3 Table, Iceberg, and Parquet).

Configuring Amazon Bedrock AgentCore Gateway for secure access to private resources
In this post, you will configure Amazon Bedrock AgentCore Gateway to access private endpoints using Resource Gateway, a managed construct that provisions Elastic Network Interfaces (ENIs) directly inside your Amazon VPC, one per subnet. You will explore two implementation modes (managed and self-managed) and walk through three practical scenarios: connecting to a private Amazon API Gateway endpoint, integrating with a MCP server on Amazon Elastic Kubernetes Service (Amazon EKS), and accessing a private REST API.