Artificial Intelligence
Category: Advanced (300)

Personalize your generative AI applications with Amazon SageMaker Feature Store
In this post, we elucidate the simple yet powerful idea of combining user profiles and item attributes to generate personalized content recommendations using LLMs. As demonstrated throughout the post, these models hold immense potential in generating high-quality, context-aware input text, which leads to enhanced recommendations. To illustrate this, we guide you through the process of integrating a feature store (representing user profiles) with an LLM to generate these personalized recommendations.

Build an image-to-text generative AI application using multimodality models on Amazon SageMaker
In this post, we provide an overview of popular multimodality models. We also demonstrate how to deploy these pre-trained models on Amazon SageMaker. Furthermore, we discuss the diverse applications of these models, focusing particularly on several real-world scenarios, such as zero-shot tag and attribution generation for ecommerce and automatic prompt generation from images.

Automate prior authorization using CRD with CDS Hooks and AWS HealthLake
Prior authorization is a crucial process in healthcare that involves the approval of medical treatments or procedures before they are carried out. This process is necessary to ensure that patients receive the right care and that healthcare providers are following the correct procedures. However, prior authorization can be a time-consuming and complex process that requires […]

Build a crop segmentation machine learning model with Planet data and Amazon SageMaker geospatial capabilities
In this analysis, we use a K-nearest neighbors (KNN) model to conduct crop segmentation, and we compare these results with ground truth imagery on an agricultural region. Our results reveal that the classification from the KNN model is more accurately representative of the state of the current crop field in 2017 than the ground truth classification data from 2015. These results are a testament to the power of Planet’s high-cadence geospatial imagery. Agricultural fields change often, sometimes multiple times a season, and having high-frequency satellite imagery available to observe and analyze this land can provide immense value to our understanding of agricultural land and quickly-changing environments.
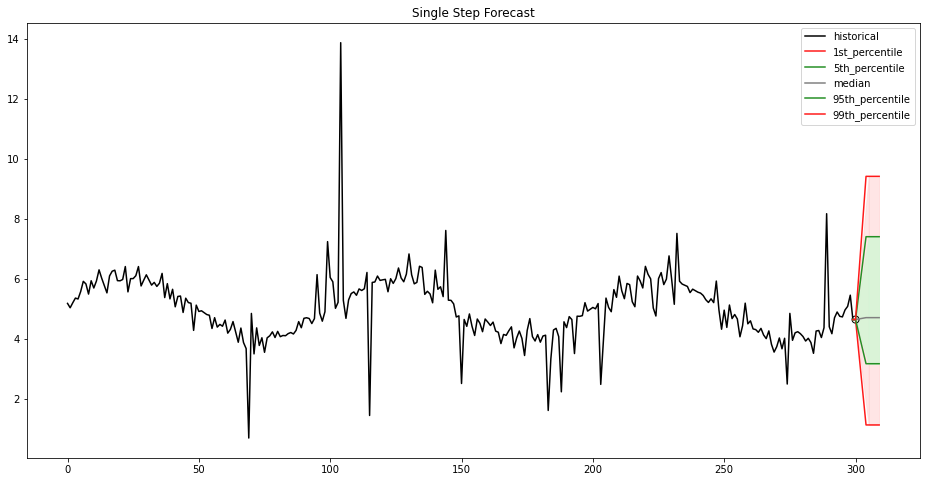
Robust time series forecasting with MLOps on Amazon SageMaker
In the world of data-driven decision-making, time series forecasting is key in enabling businesses to use historical data patterns to anticipate future outcomes. Whether you are working in asset risk management, trading, weather prediction, energy demand forecasting, vital sign monitoring, or traffic analysis, the ability to forecast accurately is crucial for success. In these applications, […]

Create a Generative AI Gateway to allow secure and compliant consumption of foundation models
In the rapidly evolving world of AI and machine learning (ML), foundation models (FMs) have shown tremendous potential for driving innovation and unlocking new use cases. However, as organizations increasingly harness the power of FMs, concerns surrounding data privacy, security, added cost, and compliance have become paramount. Regulated and compliance-oriented industries, such as financial services, […]

A generative AI-powered solution on Amazon SageMaker to help Amazon EU Design and Construction
The Amazon EU Design and Construction (Amazon D&C) team is the engineering team designing and constructing Amazon Warehouses across Europe and the MENA region. The design and deployment processes of projects involve many types of Requests for Information (RFIs) about engineering requirements regarding Amazon and project-specific guidelines. These requests range from simple retrieval of baseline […]

Build and deploy ML inference applications from scratch using Amazon SageMaker
As machine learning (ML) goes mainstream and gains wider adoption, ML-powered inference applications are becoming increasingly common to solve a range of complex business problems. The solution to these complex business problems often requires using multiple ML models and steps. This post shows you how to build and host an ML application with custom containers […]
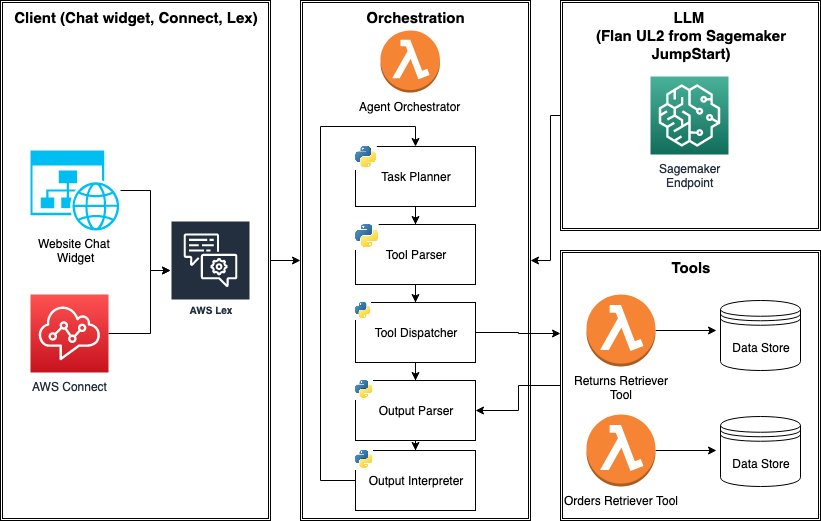
Learn how to build and deploy tool-using LLM agents using AWS SageMaker JumpStart Foundation Models
Large language model (LLM) agents are programs that extend the capabilities of standalone LLMs with 1) access to external tools (APIs, functions, webhooks, plugins, and so on), and 2) the ability to plan and execute tasks in a self-directed fashion. Often, LLMs need to interact with other software, databases, or APIs to accomplish complex tasks. […]

Build a classification pipeline with Amazon Comprehend custom classification (Part I)
In first part of this multi-series blog post, you will learn how to create a scalable training pipeline and prepare training data for Comprehend Custom Classification models. We will introduce a custom classifier training pipeline that can be deployed in your AWS account with few clicks.