Artificial Intelligence
Automate classification of IT service requests with an Amazon Comprehend custom classifier
Enterprises often deal with large volumes of IT service requests. Traditionally, the burden is put on the requester to choose the correct category for every issue. A manual error or misclassification of a ticket usually means a delay in resolving the IT service request. This can result in reduced productivity, a decrease in customer satisfaction, an impact to service level agreements (SLAs), and broader operational impacts. As your enterprise grows, the problem of getting the right service request to the right team becomes even more important. Using an approach based on machine learning (ML) and artificial intelligence can help with your enterprise’s ever-evolving needs.
Supervised ML is a process that uses labeled datasets and outputs to train learning algorithms on how to classify data or predict an outcome. Amazon Comprehend is a natural language processing (NLP) service that uses ML to uncover valuable insights and connections in text. It provides APIs powered by ML to extract key phrases, entities, sentiment analysis, and more.
In this post, we show you how to implement a supervised ML model that can help classify IT service requests automatically using Amazon Comprehend custom classification. Amazon Comprehend custom classification helps you customize Amazon Comprehend for your specific requirements without the skillset required to build ML-based NLP solutions. With automatic ML, or AutoML, Amazon Comprehend custom classification builds customized NLP models on your behalf, using the training data that you provide.
Overview of solution
To illustrate the IT service request classification, this solution uses the SEOSS dataset. This dataset is a systematically retrieved dataset consisting of 33 open-source software projects that contains a large number of typed artifacts and trace links between them. This solution uses the issue data from these 33 open-source projects, summaries, and descriptions as reported by end-users to build a custom classifier model using Amazon Comprehend.
This post demonstrates how to implement and deploy the solution using the AWS Cloud Development Kit (AWS CDK) in an isolated Amazon Virtual Private Cloud (Amazon VPC) environment consisting of only private subnets. We also use the code to demonstrate how you can use the AWS CDK provider framework, a mini-framework for implementing a provider for AWS CloudFormation custom resources to create, update, or delete a custom resource, such as an Amazon Comprehend endpoint. The Amazon Comprehend endpoint includes managed resources that make your custom model available for real-time inference to a client machine or third-party applications. The code for this solution is available on Github.
You use the AWS CDK to deploy the infrastructure, application code, and configuration for the solution. You also need an AWS account and the ability to create AWS resources. You use the AWS CDK to create AWS resources such as a VPC with private subnets, Amazon VPC endpoints, Amazon Elastic File System (Amazon EFS), an Amazon Simple Notification Service (Amazon SNS) topic, an Amazon Simple Storage Service (Amazon S3) bucket, Amazon S3 event notifications, and AWS Lambda functions. Collectively, these AWS resources constitute the training stack, which you use to build and train the custom classifier model.
After you create these AWS resources, you download the SEOSS dataset and upload the dataset to the S3 bucket created by the solution. If you’re deploying this solution in AWS Region us-east-2, the format of the S3 bucket name is comprehendcustom-<AWS-ACCOUNT-NUMBER>-us-east-2-s3stack. The solution uses the Amazon S3 multi-part upload trigger to invoke a Lambda function that starts the pre-processing of the input data, and uses the preprocessed data to train the Amazon Comprehend custom classifier to create the custom classifier model. You then use the Amazon Resource Name (ARN) of the custom classifier model to create the inference stack, which creates an Amazon Comprehend endpoint using the AWS CDK provider framework, which you can then use for inferences from a third-party application or client machine.
The following diagram illustrates the architecture of the training stack.

The workflow steps are as follows:
- Upload the SEOSS dataset to the S3 bucket created as part of the training stack deployment process. This creates an event trigger that invokes the
etl_lambdafunction. - The
etl_lambdafunction downloads the raw data set from Amazon S3 to Amazon EFS. - The
etl_lambdafunction performs the data preprocessing task of the SEOSS dataset. - When the function execution completes, it uploads the transformed data with
prepped_dataprefix to the S3 bucket. - After the upload of the transformed data is complete, a successful ETL completion message is send to Amazon SNS.
- In Amazon Comprehend, you can classify your documents using two modes: multi-class or multi-label. Multi-class mode identifies one and only one class for each document, and multi-label mode identifies one or more labels for each document. Because we want to identify a single class to each document, we train the custom classifier model in multi-class mode. Amazon SNS triggers the
train_classifier_lambdafunction, which initiates the Amazon Comprehend classifier training in a multi-class mode. - The
train_classifier_lambdafunction initiates the Amazon Comprehend custom classifier training. - Amazon Comprehend downloads the transformed data from the
prepped_dataprefix in Amazon S3 to train the custom classifier model. - When the model training is complete, Amazon Comprehend uploads the
model.tar.gzfile to theoutput_dataprefix of the S3 bucket. The average completion time to train this custom classifier model is approximately 10 hours. - The Amazon S3 upload trigger invokes the
extract_comprehend_model_name_lambdafunction, which retrieves the custom classifier model ARN. - The function extracts the custom classifier model ARN from the S3 event payload and the response of
list-document-classifierscall. - The function sends the custom classifier model ARN to the email address that you had subscribed earlier as part of the training stack creation process. You then use this ARN to deploy the inference stack.
This deployment creates the inference stack, as shown in the following figure. The inference stack provides you with a REST API secured by an AWS Identity and Access Management (IAM) authorizer, which you can then use to generate confidence scores of the labels based on the input text supplied from a third-party application or client machine.

Prerequisites
For this demo, you should have the following prerequisites:
- An AWS account.
- Python 3.7 or later, Node.js, and Git in the development machine. The AWS CDK uses specific versions of Node.js (>=10.13.0, except for version 13.0.0 – 13.6.0). A version in active long-term support (LTS) is recommended.
To install the active LTS version of Node.js, you can use the following install script fornvmand usenvmto install the Node.js LTS version. You can also install the current active LTS Node.js via package manager depending on the operating system of your choice.For macOS, you can install the Node.js via package manager using the following instructions.
For Windows, you can install the Node.js via package manager using the following instructions.
- AWS CDK v2 is pre-installed if you’re using an AWS Cloud9 IDE. If you’re using AWS Cloud9 IDE, you can skip this step.If you don’t have the AWS CDK installed in the development machine, install AWS CDK v2 globally using the Node Package Manager command
npm install -g aws-cdk. This step requires Node.js to be installed in the development machine. - Configure your AWS credentials to access and create AWS resources using the AWS CDK. For instructions, refer to Specifying credentials and region.
- Download the SEOSS dataset consisting of requirements, bug reports, code history, and trace links of 33 open-source software projects. Save the file
dataverse_files.zipon your local machine.

Deploy the AWS CDK training stack
For AWS CDK deployment, we start with the training stack. Complete the following steps:
- Clone the GitHub repository:
- Navigate to the
amazon-comprehend-custom-automate-classification-it-service-requestfolder:
All the following commands are run within the amazon-comprehend-custom-automate-classification-it-service-request directory.
- In the amazon-comprehend-custom-automate-classification-it-service-request directory, initialize the Python virtual environment and install requirements.txt with pip:
- If you’re using the AWS CDK in a specific AWS account and Region for the first time, see the instructions for bootstrapping your AWS CDK environment:
- Synthesize the CloudFormation templates for this solution using
cdk synthand usecdk deployto create the AWS resources mentioned earlier:
After you enter cdk deploy, the AWS CDK prompts whether you want to deploy changes for each of the stacks called out in the cdk deploy command.
- Enter
yfor each of the stack creation prompts, then the cdk deploy step creates these stacks. Subscribe the email address provide by you to the SNS topic created as part of the cdk deploy. - After cdk deploy completes successfully, create a folder called
raw_datain the S3 bucketcomprehendcustom-<AWS-ACCOUNT-NUMBER>-<AWS-REGION>-s3stack. - Upload the SEOSS dataset
dataverse_files.zipthat you downloaded earlier to this folder.
After the upload is complete, the solution invokes the etl_lambda function using an Amazon S3 event trigger to start the extract, transform, and load (ETL) process. After the ETL process completes successfully, a message is sent to the SNS topic, which invokes the train_classifier_lambda function. This function triggers an Amazon Comprehend custom classifier model training. Depending on whether you train your model on the complete SEOSS dataset, training could take up to 10 hours. When the training process is complete, Amazon Comprehend uploads the model.tar.gz file to the output_data prefix in the S3 bucket.
This upload triggers the extract_comprehend_model_name_lambda function using a S3 event trigger that extracts the custom classifier model ARN and sends it to the email address you had subscribed earlier. This custom classifier model ARN is then used to create the inference stack. When the model training is complete, you can view the performance metrics of the custom classifier model by navigating to the version details section in the Amazon Comprehend console (see the following screenshot), or by using the Amazon Comprehend Boto3 SDK.
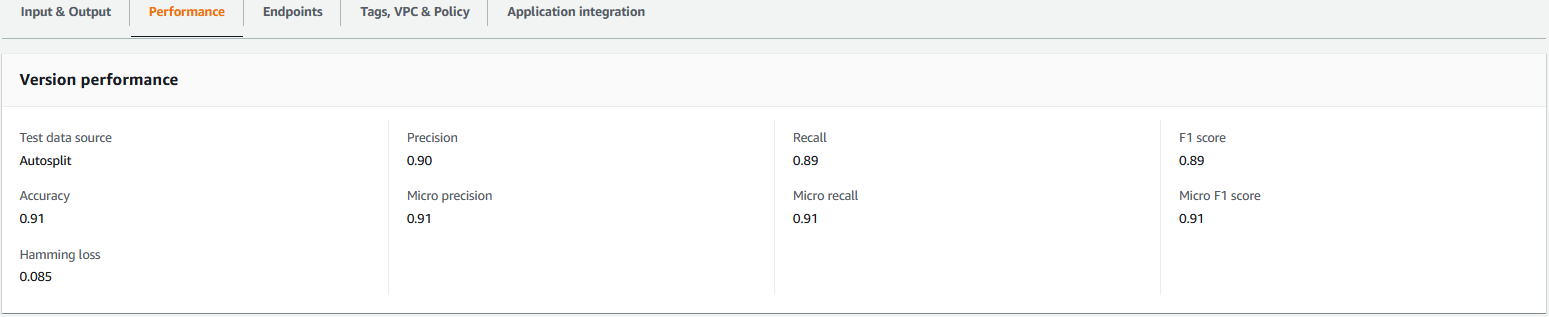
Deploy the AWS CDK inference stack
Now you’re ready to deploy the inference stack.
- Copy the custom classifier model ARN from the email you received and use the following
cdk deploycommand to create the inference stack.
This command deploys an API Gateway REST API secured by an IAM authorizer, which you use for inference with an AWS user ID or IAM role that just has the execute-api:Invoke IAM privilege. The following cdk deploy command deploys the inference stack. This stack uses the AWS CDK provider framework to create the Amazon Comprehend endpoint as a custom resource, so that creating, deleting, and updating of the Amazon Comprehend endpoint can be done as part of the inference stack lifecycle using the cdk deploy and cdk destroy commands.
Because you need to run the following command after model training is complete, which could take up to 10 hours, ensure that you’re in the Python virtual environment that you initialized in an earlier step and in the amazon-comprehend-custom-automate-classification-it-service-request directory:
For example:
- After the
cdk deploycommand completes successfully, copy theAPIGWInferenceStack.ComprehendCustomClassfierInvokeAPIvalue from the console output, and use this REST API to generate inferences from a client machine or a third-party application that hasexecute-api:InvokeIAM privilege. If you’re running this solution in us-east-2, the format of this REST API ishttps://<restapi-id>.execute-api.us-east-2.amazonaws.com/prod/invokecomprehendV1.
Alternatively, you can use the test client apiclientinvoke.py from the GitHub repository to send a request to the custom classifier model. Before using the apiclientinvoke.py, ensure that the following prerequisites are in place:
- You have the
boto3andrequestsPython package installed using pip on the client machine. - You have configured Boto3 credentials. By default, the test client assumes that a profile named default is present and it has the
execute-api:InvokeIAM privilege on the REST API. - SigV4Auth points to the Region where the REST API is deployed. Update the
<AWS-REGION>value tous-east-2inapiclientinvoke.pyif your REST API is deployed in us-east-2. - You have assigned the
raw_datavariable with the text on which you want to make the class prediction or the classification request:
- You have assigned the
restapivariable with the REST API copied earlier:
restapi="https://<restapi-id>.execute-api.us-east-2.amazonaws.com/prod/invokecomprehendV1"
- Run the
apiclientinvoke.pyafter the preceding updates:
You get the following response from the custom classifier model:
Amazon Comprehend returns confidence scores for each label that it has attributed correctly. If the service is highly confident about a label, the score will be closer to 1. Therefore, for the Amazon Comprehend custom classifier model that was trained using the SEOSS dataset, the custom classifier model predicts that the text belongs to class SPARK. This classification returned by the Amazon Comprehend custom classifier model can then be used to classify the IT service requests or predict the correct category of the IT service requests, thereby reducing manual errors or misclassification of service requests.
Clean up
To clean up all the resources created in this post that were created as part of the training stack and inference stack, use the following command. This command deletes all the AWS resources created as part of the previous cdk deploy commands:
Conclusion
In this post, we showed you how enterprises can implement a supervised ML model using Amazon Comprehend custom classification to predict the category of IT service requests based on either the subject or the description of the request submitted by the end-user. After you build and train a custom classifier model, you can run real-time analysis for custom classification by creating an endpoint. After you deploy this model to an Amazon Comprehend endpoint, it can be used to run real-time inference by third-party applications or other client machines, including IT service management tools. You can then use this inference to predict the defect category and reduce manual errors or misclassifications of tickets. This helps reduce delays for ticket resolution and increases resolution accuracy and customer productivity, which ultimately results in increased customer satisfaction.
You can extend the concepts in this post to other use cases, such as routing business or IT tickets to various internal teams such as business departments, customer service agents, and Tier 2/3 IT support, created either by end-users or through automated means.
References
- Rath, Michael; Mäder, Patrick, 2019, “The SEOSS Dataset – Requirements, Bug Reports, Code History, and Trace Links for Entire Projects”, https://doi.org/10.7910/DVN/PDDZ4Q, Harvard Dataverse, V1
About the Authors
 Arnab Chakraborty is a Sr. Solutions Architect at AWS based out of Cincinnati, Ohio. He is passionate about topics in Enterprise & Solution architecture, Data analytics, Serverless and Machine Learning. In his spare time, he enjoys watching movies , travel shows and sports.
Arnab Chakraborty is a Sr. Solutions Architect at AWS based out of Cincinnati, Ohio. He is passionate about topics in Enterprise & Solution architecture, Data analytics, Serverless and Machine Learning. In his spare time, he enjoys watching movies , travel shows and sports.
Viral Desai is a Principal Solutions Architect at AWS. With more than 25 years of experiences in information technology, he has been helping customers adopt AWS and modernize their architectures. He likes hiking, and enjoys diving deep with customers on all things AWS.
Desai is a Principal Solutions Architect at AWS. With more than 25 years of experiences in information technology, he has been helping customers adopt AWS and modernize their architectures. He likes hiking, and enjoys diving deep with customers on all things AWS.