Artificial Intelligence
How Amazon Search runs large-scale, resilient machine learning projects with Amazon SageMaker
If you have searched for an item to buy on amazon.com, you have used Amazon Search services. At Amazon Search, we’re responsible for the search and discovery experience for our customers worldwide. In the background, we index our worldwide catalog of products, deploy highly scalable AWS fleets, and use advanced machine learning (ML) to match relevant and interesting products to every customer’s query.
Our scientists regularly train thousands of ML models to improve the quality of search results. Supporting large-scale experimentation presents its own challenges, especially when it comes to improving the productivity of the scientists training these ML models.
In this post, we share how we built a management system around Amazon SageMaker training jobs, allowing our scientists to fire-and-forget thousands of experiments and be notified when needed. They can now focus on high-value tasks and resolving algorithmic errors, saving 60% of their time.
The challenge
At Amazon Search, our scientists solve information retrieval problems by experimenting and running numerous ML model training jobs on SageMaker. To keep up with our team’s innovation, our models’ complexity and number of training jobs have increased over time. SageMaker training jobs allow us to reduce the time and cost to train and tune those models at scale, without the need to manage infrastructure.
Like everything in such large-scale ML projects, training jobs can fail due to a variety of factors. This post focuses on capacity shortages and failures due to algorithm errors.
We designed an architecture with a job management system to tolerate and reduce the probability of a job failing due to capacity unavailability or algorithm errors. It allows scientists to fire-and-forget thousands of training jobs, automatically retry them on transient failure, and get notified of success or failure if needed.
Solution overview
In the following solution diagram, we use SageMaker training jobs as the basic unit of our solution. That is, a job represents the end-to-end training of an ML model.
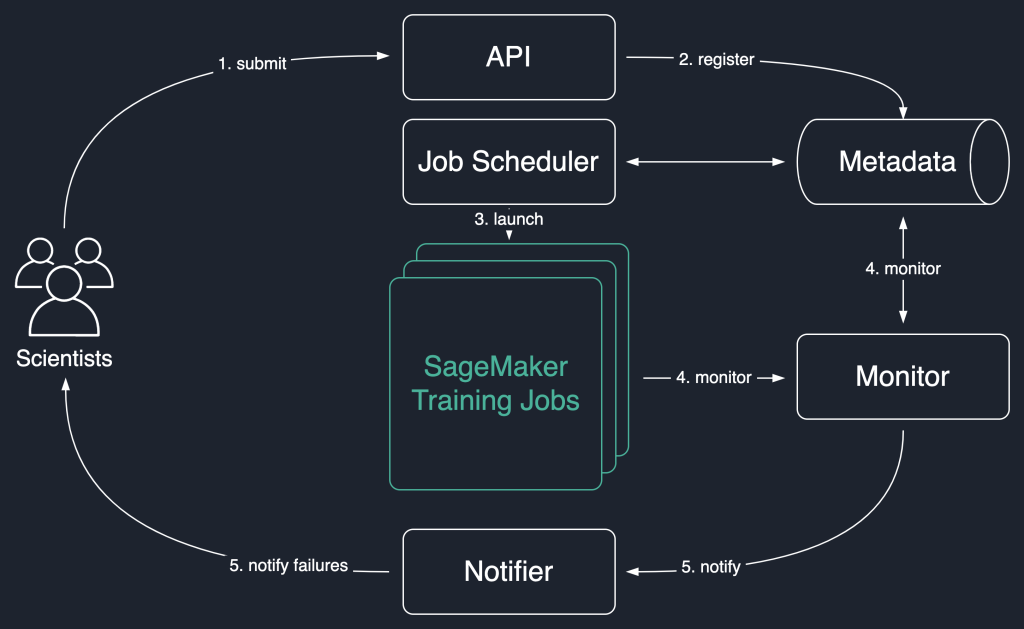
The high-level workflow of this solution is as follows:
- Scientists invoke an API to submit a new job to the system.
- The job is registered with the
Newstatus in a metadata store. - A job scheduler asynchronously retrieves
Newjobs from the metadata store, parses their input, and tries to launch SageMaker training jobs for each one. Their status changes toLaunchedorFaileddepending on success. - A monitor checks the jobs progress at regular intervals, and reports their
Completed,Failed, orInProgressstate in the metadata store. - A notifier is triggered to report
CompletedandFailedjobs to the scientists.
Persisting the jobs history in the metadata store also allows our team to conduct trend analysis and monitor project progress.
This job scheduling solution uses loosely coupled serverless components based on AWS Lambda, Amazon DynamoDB, Amazon Simple Notification Service (Amazon SNS), and Amazon EventBridge. This ensures horizontal scalability, allowing our scientists to launch thousands of jobs with minimal operations effort. The following diagram illustrates the serverless architecture.
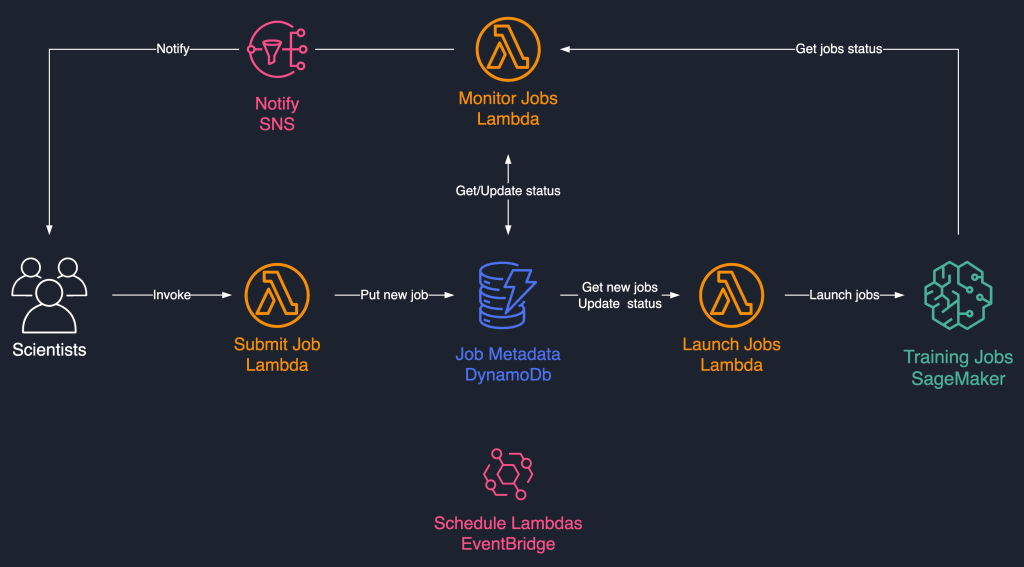
In the following sections, we go into more detail about each service and its components.
DynamoDB as the metadata store for job runs
The ease of use and scalability of DynamoDB made it a natural choice to persist the jobs metadata in a DynamoDB table. This solution stores several attributes of jobs submitted by scientists, thereby helping with progress tracking and workflow orchestration. The most important attributes are as follows:
- JobId – A unique job ID. This can be auto-generated or provided by the scientist.
- JobStatus – The status of the job.
- JobArgs – Other arguments required for creating a training job, such as the input path in Amazon S3, the training image URI, and more. For a complete list of parameters required to create a training job, refer to CreateTrainingJob.
Lambda for the core logic
We use three container-based Lambda functions to orchestrate the job workflow:
- Submit Job – This function is invoked by scientists when they need to launch new jobs. It acts as an API for simplicity. You can also front it with Amazon API Gateway, if needed. This function registers the jobs in the DynamoDB table.
- Launch Jobs – This function periodically retrieves
Newjobs from the DynamoDB table and launches them using the SageMaker CreateTrainingJob command. It retries on transient failures, such asResourceLimitExceededandCapacityError, to instrument resiliency into the system. It then updates the job status asLaunchedorFaileddepending on success. - Monitor Jobs – This function periodically keeps track of job progress using the DescribeTrainingJob command, and updates the DynamoDB table accordingly. It polls
Failedjobs from the metadata and assesses whether they should be resubmitted or marked as terminally failed. It also publishes notification messages to the scientists when their jobs reach a terminal state.
EventBridge for scheduling
We use EventBridge to run the Launch Jobs and Monitor Jobs Lambda functions on a schedule. For more information, refer to Tutorial: Schedule AWS Lambda functions using EventBridge.
Alternatively, you can use Amazon DynamoDB Streams for the triggers. For more information, see DynamoDB Streams and AWS Lambda triggers.
Notifications with Amazon SNS
Our scientists are notified by email using Amazon SNS when their jobs reach a terminal state (Failed after a maximum number of retries), Completed, or Stopped.
Conclusion
In this post, we shared how Amazon Search adds resiliency to ML model training workloads by scheduling them, and retrying them on capacity shortages or algorithm errors. We used Lambda functions in conjunction with a DynamoDB table as a central metadata store to orchestrate the entire workflow.
Such a scheduling system allows scientists to submit their jobs and forget about them. This saves time and allows them to focus on writing better models.
To go further in your learnings, you can visit Awesome SageMaker and find in a single place, all the relevant and up-to-date resources needed for working with SageMaker.
About the Authors
 Luochao Wang is a Software Engineer at Amazon Search. He focuses on scalable distributed systems and automation tooling on the cloud to accelerate the pace of scientific innovation for Machine Learning applications.
Luochao Wang is a Software Engineer at Amazon Search. He focuses on scalable distributed systems and automation tooling on the cloud to accelerate the pace of scientific innovation for Machine Learning applications.
 Ishan Bhatt is a Software Engineer in Amazon Prime Video team. He primarily works in the MLOps space and has experience building MLOps products for the past 4 years using Amazon SageMaker.
Ishan Bhatt is a Software Engineer in Amazon Prime Video team. He primarily works in the MLOps space and has experience building MLOps products for the past 4 years using Amazon SageMaker.
 Abhinandan Patni is a Senior Software Engineer at Amazon Search. He focuses on building systems and tooling for scalable distributed deep learning training and real time inference.
Abhinandan Patni is a Senior Software Engineer at Amazon Search. He focuses on building systems and tooling for scalable distributed deep learning training and real time inference.
 Eiman Elnahrawy is a Principal Software Engineer at Amazon Search leading the efforts on Machine Learning acceleration, scaling, and automation. Her expertise spans multiple areas, including Machine Learning, Distributed Systems, and Personalization.
Eiman Elnahrawy is a Principal Software Engineer at Amazon Search leading the efforts on Machine Learning acceleration, scaling, and automation. Her expertise spans multiple areas, including Machine Learning, Distributed Systems, and Personalization.
 Sofian Hamiti is an AI/ML specialist Solutions Architect at AWS. He helps customers across industries accelerate their AI/ML journey by helping them build and operationalize end-to-end machine learning solutions.
Sofian Hamiti is an AI/ML specialist Solutions Architect at AWS. He helps customers across industries accelerate their AI/ML journey by helping them build and operationalize end-to-end machine learning solutions.
 Dr. Romi Datta is a Senior Manager of Product Management in the Amazon SageMaker team responsible for training, processing and feature store. He has been in AWS for over 4 years, holding several product management leadership roles in SageMaker, S3 and IoT. Prior to AWS he worked in various product management, engineering and operational leadership roles at IBM, Texas Instruments and Nvidia. He has an M.S. and Ph.D. in Electrical and Computer Engineering from the University of Texas at Austin, and an MBA from the University of Chicago Booth School of Business.
Dr. Romi Datta is a Senior Manager of Product Management in the Amazon SageMaker team responsible for training, processing and feature store. He has been in AWS for over 4 years, holding several product management leadership roles in SageMaker, S3 and IoT. Prior to AWS he worked in various product management, engineering and operational leadership roles at IBM, Texas Instruments and Nvidia. He has an M.S. and Ph.D. in Electrical and Computer Engineering from the University of Texas at Austin, and an MBA from the University of Chicago Booth School of Business.
 RJ is an engineer in Search M5 team leading the efforts for building large scale deep learning systems for training and inference. Outside of work he explores different cuisines of food and plays racquet sports.
RJ is an engineer in Search M5 team leading the efforts for building large scale deep learning systems for training and inference. Outside of work he explores different cuisines of food and plays racquet sports.