Artificial Intelligence
Category: Intermediate (200)

Simplify automotive damage processing with Amazon Bedrock and vector databases
This post explores a solution that uses the power of AWS generative AI capabilities like Amazon Bedrock and OpenSearch vector search to perform damage appraisals for insurers, repair shops, and fleet managers.

Improve governance of models with Amazon SageMaker unified Model Cards and Model Registry
You can now register machine learning (ML) models in Amazon SageMaker Model Registry with Amazon SageMaker Model Cards, making it straightforward to manage governance information for specific model versions directly in SageMaker Model Registry in just a few clicks. In this post, we discuss a new feature that supports the integration of model cards with the model registry. We discuss the solution architecture and best practices for managing model cards with a registered model version, and walk through how to set up, operationalize, and govern your models using the integration in the model registry.
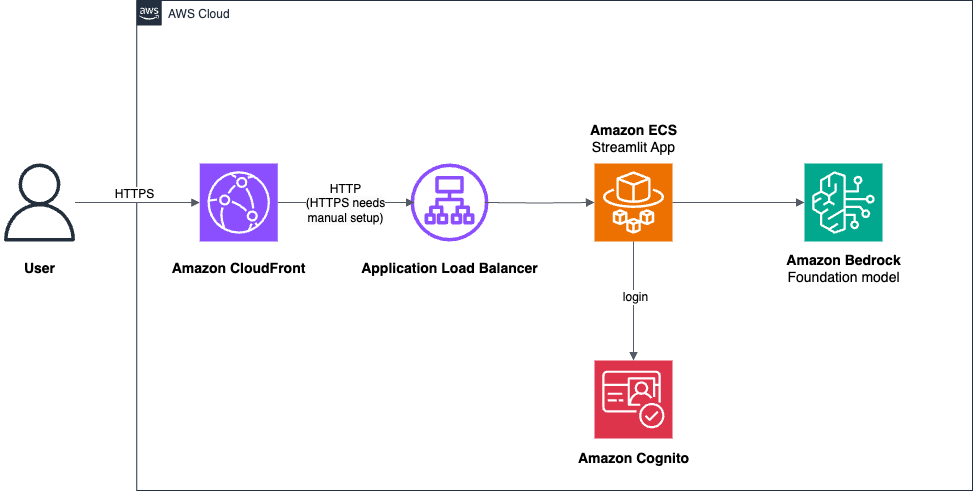
Build and deploy a UI for your generative AI applications with AWS and Python
AWS provides a powerful set of tools and services that simplify the process of building and deploying generative AI applications, even for those with limited experience in frontend and backend development. In this post, we explore a practical solution that uses Streamlit, a Python library for building interactive data applications, and AWS services like Amazon Elastic Container Service (Amazon ECS), Amazon Cognito, and the AWS Cloud Development Kit (AWS CDK) to create a user-friendly generative AI application with authentication and deployment.

Unearth insights from audio transcripts generated by Amazon Transcribe using Amazon Bedrock
In this post, we examine how to create business value through speech analytics with some examples focused on the following: 1) automatically summarizing, categorizing, and analyzing marketing content such as podcasts, recorded interviews, or videos, and creating new marketing materials based on those assets, 2) automatically extracting key points, summaries, and sentiment from a recorded meeting (such as an earnings call), and 3) transcribing and analyzing contact center calls to improve customer experience.

Best practices and lessons for fine-tuning Anthropic’s Claude 3 Haiku on Amazon Bedrock
In this post, we explore the best practices and lessons learned for fine-tuning Anthropic’s Claude 3 Haiku on Amazon Bedrock. We discuss the important components of fine-tuning, including use case definition, data preparation, model customization, and performance evaluation.

Use Amazon Q to find answers on Google Drive in an enterprise
This post covers the steps to configure the Amazon Q Business Google Drive connector, including authentication setup and verifying the secure indexing of your Google Drive content.

Unlock organizational wisdom using voice-driven knowledge capture with Amazon Transcribe and Amazon Bedrock
This post introduces an innovative voice-based application workflow that harnesses the power of Amazon Bedrock, Amazon Transcribe, and React to systematically capture and document institutional knowledge through voice recordings from experienced staff members. Our solution uses Amazon Transcribe for real-time speech-to-text conversion, enabling accurate and immediate documentation of spoken knowledge. We then use generative AI, powered by Amazon Bedrock, to analyze and summarize the transcribed content, extracting key insights and generating comprehensive documentation.

Achieve multi-Region resiliency for your conversational AI chatbots with Amazon Lex
Global Resiliency is a new Amazon Lex capability that enables near real-time replication of your Amazon Lex V2 bots in a second AWS Region. When you activate this feature, all resources, versions, and aliases associated after activation will be synchronized across the chosen Regions. With Global Resiliency, the replicated bot resources and aliases in the […]
Create and fine-tune sentence transformers for enhanced classification accuracy
In this post, we showcase how to fine-tune a sentence transformer specifically for classifying an Amazon product into its product category (such as toys or sporting goods). We showcase two different sentence transformers, paraphrase-MiniLM-L6-v2 and a proprietary Amazon large language model (LLM) called M5_ASIN_SMALL_V2.0, and compare their results.

Empower your generative AI application with a comprehensive custom observability solution
In this post, we set up the custom solution for observability and evaluation of Amazon Bedrock applications. Through code examples and step-by-step guidance, we demonstrate how you can seamlessly integrate this solution into your Amazon Bedrock application, unlocking a new level of visibility, control, and continual improvement for your generative AI applications.