Artificial Intelligence
Category: Intermediate (200)

Bi-directional streaming for real-time agent interactions now available in Amazon Bedrock AgentCore Runtime
In this post, you will learn about bi-directional streaming on AgentCore Runtime and the prerequisites to create a WebSocket implementation. You will also learn how to use Strands Agents to implement a bi-directional streaming solution for voice agents.

Track machine learning experiments with MLflow on Amazon SageMaker using Snowflake integration
In this post, we demonstrate how to integrate Amazon SageMaker managed MLflow as a central repository to log these experiments and provide a unified system for monitoring their progress.
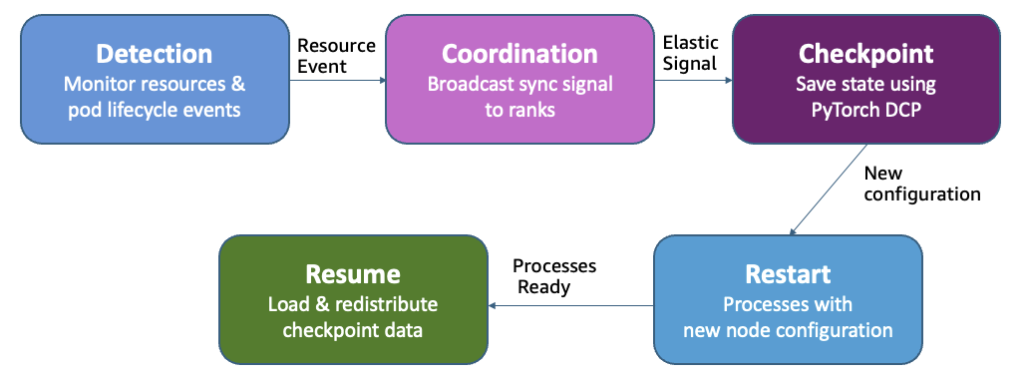
Adaptive infrastructure for foundation model training with elastic training on SageMaker HyperPod
Amazon SageMaker HyperPod now supports elastic training, enabling your machine learning (ML) workloads to automatically scale based on resource availability. In this post, we demonstrate how elastic training helps you maximize GPU utilization, reduce costs, and accelerate model development through dynamic resource adaptation, while maintain training quality and minimizing manual intervention.

Customize agent workflows with advanced orchestration techniques using Strands Agents
In this post, we explore two powerful orchestration patterns implemented with Strands Agents. Using a common set of travel planning tools, we demonstrate how different orchestration strategies can solve the same problem through distinct reasoning approaches,

Operationalize generative AI workloads and scale to hundreds of use cases with Amazon Bedrock – Part 1: GenAIOps
In this first part of our two-part series, you’ll learn how to evolve your existing DevOps architecture for generative AI workloads and implement GenAIOps practices. We’ll showcase practical implementation strategies for different generative AI adoption levels, focusing on consuming foundation models.

How Harmonic Security improved their data-leakage detection system with low-latency fine-tuned models using Amazon SageMaker, Amazon Bedrock, and Amazon Nova Pro
This post walks through how Harmonic Security used Amazon SageMaker AI, Amazon Bedrock, and Amazon Nova Pro to fine-tune a ModernBERT model, achieving low-latency, accurate, and scalable data leakage detection.

Real-world reasoning: How Amazon Nova 2 Lite handles complex customer support scenarios
This post evaluates the reasoning capabilities of our latest offering in the Nova family, Amazon Nova 2 Lite, using practical scenarios that test these critical dimensions. We compare its performance against other models in the Nova family—Lite 1.0, Micro, Pro 1.0, and Premier—to elucidate how the latest version advances reasoning quality and consistency.

Create AI-powered chat assistants for your enterprise with Amazon Quick Suite
In this post, we show how to build chat agents in Amazon Quick Suite. We walk through a three-layer framework—identity, instructions, and knowledge—that transforms Quick Suite chat agents into intelligent enterprise AI assistants. In our example, we demonstrate how our chat agent guides feature discovery, use enterprise data to inform recommendations, and tailors solutions based on potential to impact and your team’s adoption readiness.
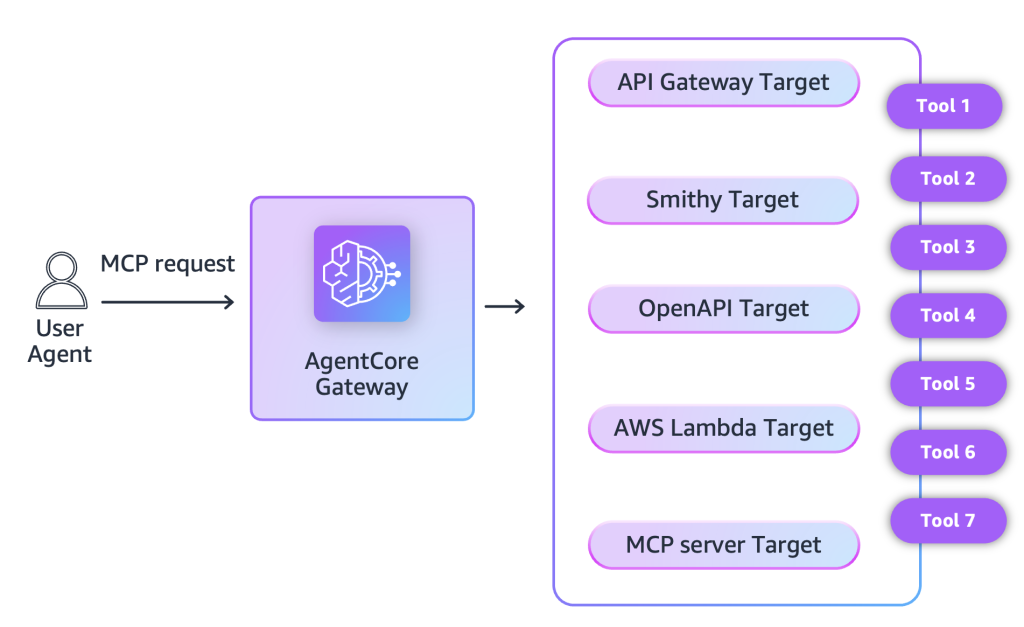
Streamline AI agent tool interactions: Connect API Gateway to AgentCore Gateway with MCP
AgentCore Gateway now supports API Gateway. As organizations explore the possibilities of agentic applications, they continue to navigate challenges of using enterprise data as context in invocation requests to large language models (LLMs) in a manner that is secure and aligned with enterprise policies. This post covers these new capabilities and shows how to implement them.

Create an intelligent insurance underwriter agent powered by Amazon Nova 2 Lite and Amazon Quick Suite
In this post, we demonstrate how to build an intelligent insurance underwriting agent that addresses three critical challenges: unifying siloed data across CRM systems and databases, providing explainable and auditable AI decisions for regulatory compliance, and enabling automated fraud detection with consistent underwriting rules. The solution combines Amazon Nova 2 Lite for transparent risk assessment, Amazon Bedrock AgentCore for managed MCP server infrastructure, and Amazon Quick Suite for natural language interactions—delivering a production-ready system that underwriters can deploy in under 30 minutes .