Artificial Intelligence
Explore Amazon SageMaker Data Wrangler capabilities with sample datasets
Data preparation is the process of collecting, cleaning, and transforming raw data to make it suitable for insight extraction through machine learning (ML) and analytics. Data preparation is crucial for ML and analytics pipelines. Your model and insights will only be as reliable as the data you use for training them. Flawed data will produce poor results regardless of the sophistication of your algorithms and analytical tools.
Amazon SageMaker Data Wrangler is a service to help data scientists and data engineers simplify and accelerate tabular and time series data preparation and feature engineering through a visual interface. You can import data from multiple data sources, such as Amazon Simple Storage Service (Amazon S3), Amazon Athena, Amazon Redshift, Snowflake, and DataBricks, and process your data with over 300 built-in data transformations and a library of code snippets, so you can quickly normalize, transform, and combine features without writing any code. You can also bring your custom transformations in PySpark, SQL, or Pandas.
Previously, customers wanting to explore Data Wrangler needed to bring their own datasets; we’ve changed that. Starting today, you can begin experimenting with Data Wrangler’s features even faster by using a sample dataset and following suggested actions to easily navigate the product for the first time. In this post, we walk you through this process.
Solution overview
Data Wrangler offers a pre-loaded version of the well-known Titanic dataset, which is widely used to teach and experiment with ML. Data Wrangler’s suggested actions help first-time customers discover features such as Data Wrangler’s Data Quality and Insights Report, a feature that verifies data quality and helps detect abnormalities in your data.
In this post, we create a sample flow with the pre-loaded sample Titanic dataset to show how you can start experimenting with Data Wrangler’s features faster. We then use the processed Titanic dataset to create a classification model to tell us whether a passenger will survive or not, using the training functionality, which allows you to launch an Amazon SageMaker Autopilot experiment within any of the steps in a Data Wrangler flow. Along the way, we can explore Data Wrangler features through the product suggestions that surface in Data Wrangler. These suggestions can help you accelerate your learning curve with Data Wrangler by recommending actions and next steps.
Prerequisites
In order to get all the features described in this post, you need to be running the latest kernel version of Data Wrangler. For any new flow created, the kernel will always be the latest one; nevertheless, for existing flows, you need to update the Data Wrangler application first.
Import the Titanic dataset
The Titanic dataset is a public dataset widely used to teach and experiment with ML. You can use it to create an ML model that predicts which passengers will survive the Titanic shipwreck. Data Wrangler now incorporates this dataset as a sample dataset that you can use to get started with Data Wrangler more quickly. In this post, we perform some data transformations using this dataset.
Let’s create a new Data Wrangler flow and call it Titanic. Data Wrangler shows you two options: you can either import your own dataset or you can use the sample dataset (the Titanic dataset).

You’re presented with a loading bar that indicates the progress of the dataset being imported into Data Wrangler. Click through the carousel to learn more about how Data Wrangler helps you import, prepare, and process datasets for ML. Wait until the bar is fully loaded; this indicates that your dataset is imported and ready for use.

The Titanic dataset is now loaded into our flow. For a description of the dataset, refer to Titanic – Machine Learning from Disaster.
Explore Data Wrangler features
As a first-time Data Wrangler user, you now see suggested actions to help you navigate the product and discover interesting features. Let’s follow the suggested advice.
- Choose the plus sign to get a list of options to modify the dataset.

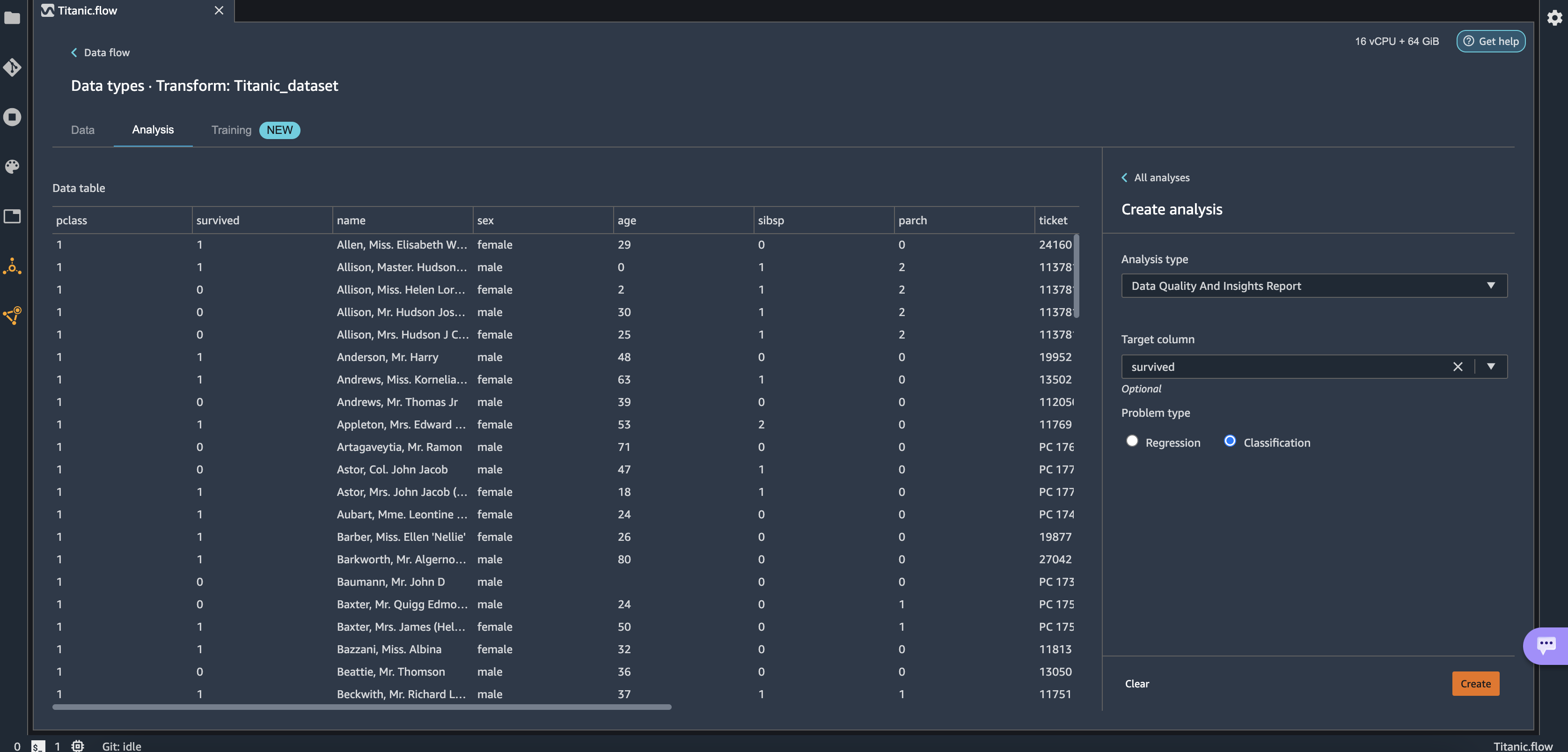
- Choose Get data insights.

This opens the Analysis tab on the data, in which you can create a Data Quality and Insights Report. When you create this report, Data Wrangler gives you the option to select a target column. A target column is a column that you’re trying to predict. When you choose a target column, Data Wrangler automatically creates a target column analysis. It also ranks the features in the order of their predictive power. When you select a target column, you must specify whether you’re trying to solve a regression or a classification problem. - Choose the column survived as the target column because that’s the value we want to predict.
- For Problem type¸ select Classification¸ because we want to know whether a passenger belongs to the survived or not survived classes.
- Choose Create.
This creates an analysis on your dataset that contains relevant points like a summary of the dataset, duplicate rows, anomalous samples, feature details, and more. To learn more about the Data Quality and Insights Report, refer to Accelerate data preparation with data quality and insights in Amazon SageMaker Data Wrangler and Get Insights On Data and Data Quality.
Let’s get a quick look at the dataset itself. - Choose the Data tab to visualize the data as a table.
 Let’s now generate some example data visualizations.
Let’s now generate some example data visualizations. - Choose the Analysis tab to start visualizing your data. You can generate three histograms: the first two visualize the number of people that survived based on the sex and class columns, as shown in the following screenshots.

 The third visualizes the ages of the people that boarded the Titanic.
The third visualizes the ages of the people that boarded the Titanic. Let’s perform some transformations on the data,
Let’s perform some transformations on the data, - First, drop the columns ticket, cabin, and name.
- Next, perform one-hot encoding on the categorical columns embarked and sex, and home.dest.
- Finally, fill in missing values for the columns boat and body with a 0 value.
Your dataset now looks something like the following screenshot.
- Now split the dataset into three sets: a training set with 70% of the data, a validation set with 20% of the data, and a test set with 10% of the data.
 The splits done here use the stratified split approach using the survived variable and are just for the sake of the demonstration.
The splits done here use the stratified split approach using the survived variable and are just for the sake of the demonstration. Now let’s configure the destination of our data.
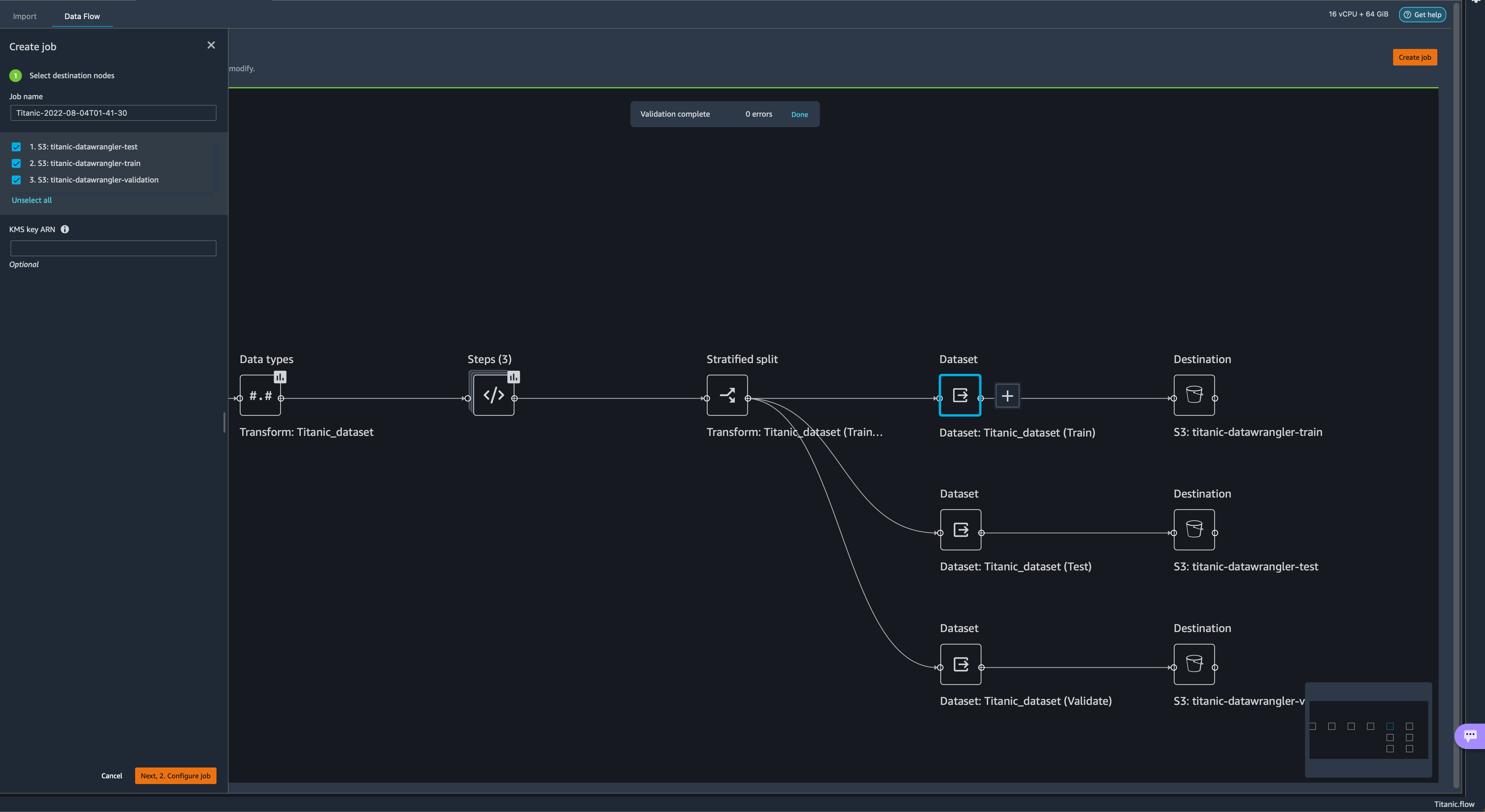
Now let’s configure the destination of our data. - Choose the plus sign on each Dataset node, choose Add destination, and choose S3 to add an Amazon S3 destination for the transformed datasets.
- In the Add a destination pane, you can configure the Amazon S3 details to store your processed datasets.
 Our Titanic flow should now look like the following screenshot.
Our Titanic flow should now look like the following screenshot. You can now transform all the data using SageMaker processing jobs.
You can now transform all the data using SageMaker processing jobs. - Choose Create job.
- Keep the default values and choose Next.

- Choose Run.
 A new SageMaker processing job is now created. You can see the job’s details and track its progress on the SageMaker console under Processing jobs.
A new SageMaker processing job is now created. You can see the job’s details and track its progress on the SageMaker console under Processing jobs. When the processing job is complete, you can navigate to any of the S3 locations specified for storing the datasets and query the data just to confirm that the processing was successful. You can now use this data to feed your ML projects.
When the processing job is complete, you can navigate to any of the S3 locations specified for storing the datasets and query the data just to confirm that the processing was successful. You can now use this data to feed your ML projects.













Launch an Autopilot experiment to create a classifier
You can now launch Autopilot experiments directly from Data Wrangler and use the data at any of the steps in the flow to automatically train a model on the data.
- Choose the Dataset node called Titanic_dataset (train) and navigate to the Train tab.
Before training, you need to first export your data to Amazon S3. - Follow the instructions to export your data to an S3 location of your choice.
You can specify to export the data in CSV or Parquet format for increased efficiency. Additionally, you can specify an AWS Key Management Service (AWS KMS) key to encrypt your data.
On the next page, you configure your Autopilot experiment. - Unless your data is split into several parts, leave the default value under Connect your data.
- For this demonstration, leave the default values for Experiment name and Output data location.
- Under Advanced settings, expand Machine learning problem type.
- Choose Binary classification as the problem type and Accuracy as the objective metric.You specify these two values manually even though Autopilot is capable of inferring them from the data.
- Leave the rest of the fields with the default values and choose Create Experiment.
 Wait for a couple of minutes until the Autopilot experiment is complete, and you will see a leaderboard like the following with each of the models obtained by Autopilot.
Wait for a couple of minutes until the Autopilot experiment is complete, and you will see a leaderboard like the following with each of the models obtained by Autopilot.


You can now choose to deploy any of the models in the leaderboard for inference.
Clean up
When you’re not using Data Wrangler, it’s important to shut down the instance on which it runs to avoid incurring additional fees.
To avoid losing work, save your data flow before shutting Data Wrangler down.
- To save your data flow in Amazon SageMaker Studio, choose File, then choose Save Data Wrangler Flow.
Data Wrangler automatically saves your data flow every 60 seconds. - To shut down the Data Wrangler instance, in Studio, choose Running Instances and Kernels.
- Under RUNNING APPS, choose the shutdown icon next to the sagemaker-data-wrangler-1.0 app.

- Choose Shut down all to confirm.
 Data Wrangler runs on an ml.m5.4xlarge instance. This instance disappears from RUNNING INSTANCES when you shut down the Data Wrangler app.
Data Wrangler runs on an ml.m5.4xlarge instance. This instance disappears from RUNNING INSTANCES when you shut down the Data Wrangler app.


After you shut down the Data Wrangler app, it has to restart the next time you open a Data Wrangler flow file. This can take a few minutes.
Conclusion
In this post, we demonstrated how you can use the new sample dataset on Data Wrangler to explore Data Wrangler’s features without needing to bring your own data. We also presented two additional features: the loading page to let you visually track the progress of the data being imported into Data Wrangler, and product suggestions that provide useful tips to get started with Data Wrangler. We went further to show how you can create SageMaker processing jobs and launch Autopilot experiments directly from the Data Wrangler user interface.
To learn more about using data flows with Data Wrangler, refer to Create and Use a Data Wrangler Flow and Amazon SageMaker Pricing. To get started with Data Wrangler, see Prepare ML Data with Amazon SageMaker Data Wrangler. To learn more about Autopilot and AutoML on SageMaker, visit Automate model development with Amazon SageMaker Autopilot.
About the authors
 David Laredo is a Prototyping Architect at AWS Envision Engineering in LATAM, where he has helped develop multiple machine learning prototypes. Previously, he worked as a Machine Learning Engineer and has been doing machine learning for over 5 years. His areas of interest are NLP, time series, and end-to-end ML.
David Laredo is a Prototyping Architect at AWS Envision Engineering in LATAM, where he has helped develop multiple machine learning prototypes. Previously, he worked as a Machine Learning Engineer and has been doing machine learning for over 5 years. His areas of interest are NLP, time series, and end-to-end ML.
 Parth Patel is a Solutions Architect at AWS in the San Francisco Bay Area. Parth guides customers to accelerate their journey to the cloud and helps them adopt the AWS Cloud successfully. He focuses on ML and application modernization.
Parth Patel is a Solutions Architect at AWS in the San Francisco Bay Area. Parth guides customers to accelerate their journey to the cloud and helps them adopt the AWS Cloud successfully. He focuses on ML and application modernization.