Artificial Intelligence
The fastest driver in Formula 1
This blog post was co-authored, and includes an introduction, by Rob Smedley, Director of Data Systems at Formula 1
Formula 1 (F1) racing is the most complex sport in the world. It is the blended perfection of human and machine that create the winning formula. It is this blend that makes F1 racing, or more pertinently, the driver talent, so difficult to understand. How many races or Championships would Michael Schumacher really have won without the power of Benetton and later, Ferrari, and the collective technical genius that were behind those teams? Could we really have seen Lewis Hamilton win six World Championships if his career had taken a different turn and he was confined to back-of-the-grid machinery? Maybe these aren’t the best examples because they are two of the best drivers the world has ever seen. There are many examples, however, of drivers whose real talent has remained fairly well hidden throughout their career. Those that never got that “right place, right time” break into a winning car and, therefore, those that will be forever remembered as a midfield driver.
The latest F1 Insight powered by AWS is designed to build mathematical models and algorithms that can help us answer the perennial question: who is the fastest driver of all time? F1 and AWS scientists have spent almost a year building these models and algorithms to bring us that very insight. The output focuses solely on one element of a driver’s vast armory—the pure speed that is most evident on a Saturday afternoon during the qualifying hour. It doesn’t focus on racecraft or the ability to win races or drive at 200 mph while still having the bandwidth to understand everything going on around you (displayed so well by the likes of Michael Schumacher or Fernando Alonso). This ability, which transgresses speed alone, allowed them both, on many an occasion, to operate as master tacticians. For someone like myself, who has had the honor of watching those very skills in action from the pitwall, I cannot emphasize enough how important those skills are—they are the difference between the good and the great. It is important to point out that these skills are not included in this insight. This is about raw speed only and the ability to push the car to its very limits over one lap.
The output and the list of the fastest drivers of all time (based on the F1 Historic Data Repository information spanning from 1983 to present day) offers some great names indeed. Of course, there are the obvious ones that rank highly—Ayrton Senna, Michael Schumacher, Lewis Hamilton, all of whom emerge as the top five fastest drivers. However, there are some names that many may not think of as top 20 drivers on first glance. A great example I would cite is Heikki Kovalainen. Is that the Kovalainen that finished his career circling round at the back of the Grand Prix field in Caterham, I hear you ask? Yes in fact, it’s the very same. For those of us who watched Kovalainen throughout his F1 career, it comes as little surprise that he is so high up the list when we consider pure speed. Look at his years on the McLaren team against Lewis Hamilton. The qualifying speaks volumes, with the median difference of just 0.1 seconds per lap. Ask Kovalainen himself and he’ll tell you that he didn’t perform at the same level as Hamilton in the races for many reasons (this is a tough business, believe me). But in qualifying, his statistics speak for themselves—the model has ranked him so highly because of his consistent qualifying performances throughout his career. I, for one, am extremely happy to see Kovalainen get the data-driven recognition that he deserves for that raw talent that was always on display during qualifying. There are others in the list, too, and hopefully some of these are your favorites—drivers that you have been banging the drum about for the last 10, 20, 40 years; the ones that might never have gotten every break, but you were able to see just how talented they were.
— Rob Smedley

Fastest Driver
As part of F1’s 70th anniversary celebrations and to help fans better understand who are the fastest drivers in the sport’s history, F1 and the Amazon Machine Learning Solutions Lab teamed up to develop Fastest Driver, the latest F1 Insight powered by AWS.
Fastest Driver uses AWS machine learning (ML) to rank drivers using their qualifying sessions lap times from F1’s Historic Data Repository going back to 1983. In this post, we demonstrate how by using Amazon SageMaker, a fully managed service to build, train, and deploy ML models, the Fastest Driver insight can objectively determine the fastest drivers in F1.
Quantifying driver pace using qualifying data
We define pace as a driver’s lap time during qualifying sessions. Driver race performance depends on a large number of factors, such as weather conditions, car setup (such as tires), and race track. F1 qualifying sessions are split into three sessions: the first session eliminates cars that set a lap time in 16th position or lower, the second eliminates positions 11–15, and the final part determines the grid position of 1st (pole position) to 10th. We use all qualification data from the driver qualifying sessions to construct Fastest Driver.
Lap times from qualifying sessions are normalized to adjust for differences in race tracks, which enables us to pool lap times across different tracks. This normalization process equalizes driver lap time differences, helping us compare drivers across race tracks and eliminating the need to construct track-specific models to account for track alterations over time. Another important technique is that we compare qualifying data for drivers on the same race team (such as Aston Martin Red Bull Racing), where teammates have competed against each other in a minimum of five qualifying sessions. By holding the team constant, we get a direct performance comparison under the same race conditions while controlling for car effects.
Differences in race conditions (such as wet weather) and rule changes (such as rule impacts) leads to significant variations in driver performances. We identify and remove anomalous lap time outliers by using deviations from median lap times between teammates with a 2-second threshold. For example, let’s compare Daniel Ricciardo with Sebastian Vettel when they raced together for Red Bull in 2014. During that season, Ricciardo was, on average, 0.2 seconds faster than Vettel. However, the average lap time difference between Ricciardo and VetteI falls to 0.1 seconds if we exclude the 2014 US Grand Prix (GP), where Ricciardo was more than 2 seconds faster than Vettel on account of Vettel being penalized to comply with the 107% rule (which forced him to start from the pit lane).
Constructing Fastest Driver
Building a performant ML model starts with good data. Following the driver qualification data aggregation process, we construct a network of teammate comparisons over the years, with the goal of comparing drivers across all teams, seasons, and circuits. For example, Sebastian Vettel and Max Verstappen have never been on the same team, so we compare them through their respective connections with Daniel Ricciardo at Red Bull. Ricciardo was, on average, 0.18 seconds slower than Verstappen during the 2016–2018 seasons while they were at Red Bull. We remove outlier sessions, such as the 2018 GPs in Bahrain, where Ricciardo was quicker than Verstappen by large margins because Verstappen didn’t get past Q1 due to a crash. If each qualifying session is assumed to be equally important, a subset of our driver network including only Ricciardo, Vettel, and Verstappen yields Verstappen as the fastest driver: Verstappen was 0.18 seconds faster than Ricciardo, and Ricciardo 0.1 seconds faster than Vettel.
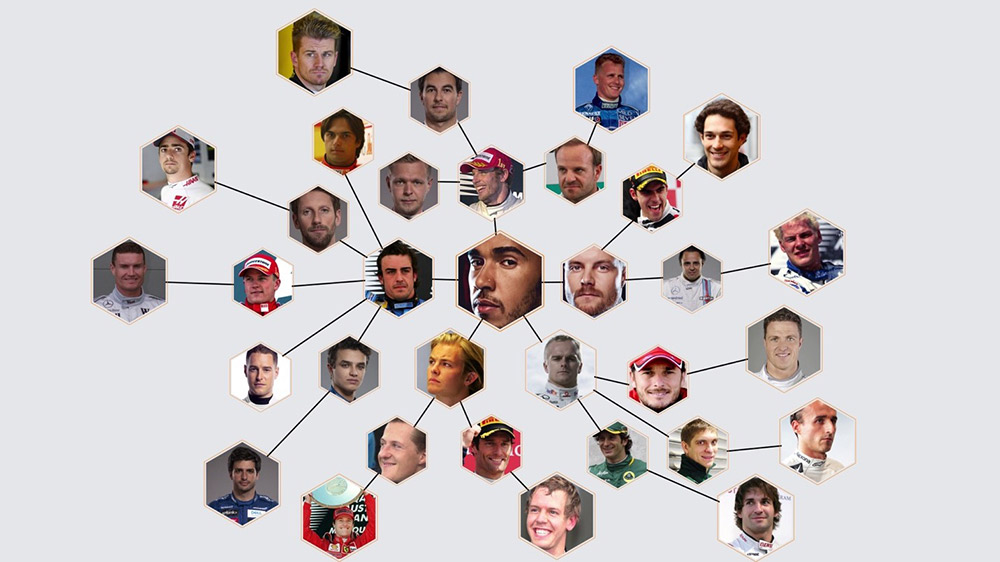
Using the full driver network, we can compare all driver pairings to determine the faster racers. Going back to Heikki Kovalainen, let’s look at his years in the McLaren team against Lewis Hamilton. The qualifying speaks volumes with the median difference of just 0.1 seconds per lap. Kovalainen doesn’t have the same number of World Championships as Hamilton, but his qualifying statistics speak for themselves—the model has ranked him high because of his consistent qualifying performance throughout his career.
An algorithm called the Massey’s method (a form of linear regression) is one of the core models behind the Insight. Fastest Driver uses Massey’s method to rank drivers by solving for a set of linear equations, where each driver’s rating is calculated as their average lap time difference against teammates. Additionally, when comparing ratings of teammates, the model uses features like driver strength of schedule normalized by the number of interactions with the driver. Overall, the model places high rankings to drivers who perform extraordinarily well against their teammates or perform well against strong opponents.
Our goal is to assign each driver a numeric rating to infer that a driver’s competitive advantage relative to other drivers assuming the expected margin of lap time difference in any race is proportional to the difference in a driver’s true intrinsic rating. For the more mathematically inclined reader: let xj represent each of all drivers and rj represent the true intrinsic driver ratings. For every race, we can predict the margin of the lap time advantage or disadvantage (yi) between any pair of two drivers as:
![]()
In this equation, xj is +1 for the winner and -1 for the loser, and ei is the error term due to unexplained variations. For a given set of m game observations and n drivers, we can formulate an (m * n) system of linear equations:
![]()
Driver ratings (r) is a solution to the normal equation via linear regression:
![]()
The following example code of Massey’s method and calculating driver rankings using Amazon SageMaker demonstrates the training process:
The kings of the asphalt
Topping our list of rankings of fastest drivers are the esteemed Ayrton Senna, Michael Schumacher, Lewis Hamilton, Max Verstappen, and Fernando Alonso. This is delivered through the Fastest Driver insight, which produces a dataset ranking based on speed (or qualifying times) of all drivers from the present day back to 1983, by simply ranking drivers in descending order of Driver, Rank (integer), Gap to Best (milliseconds).
It’s important to note that to quantify a driver’s ability, we need to observe a minimum number of interactions. To factor this in, we only include teammates who have competed against each other in at least five qualifying sessions. A number of parameters and considerations have been put in place as an effective means of identifying various conditions with unfair comparisons, such as crashes, failures, age, career breaks, or weather conditions changing over qualifying sessions.
Furthermore, we noticed that if a driver re-joined F1 following a break of three years or more (such as Michael Schumacher in 2010, Pedro de la Rosa in 2010, Narain Karthikeyan in 2011, and Robert Kubica in 2019), this adds a 0.1 second advantage to driver relative pace. This is exemplified when drivers have a large age gap with their teammates, such as Mark Webber vs. Sebastian Vettel in 2013, Felipe Massa vs. Lance Stroll in 2017, and Kimi Räikkönen vs. Antonio Giovinazzi in 2019. From 1983–2019, we observe that competing against a teammate who is significantly older gives a 0.06-second advantage.
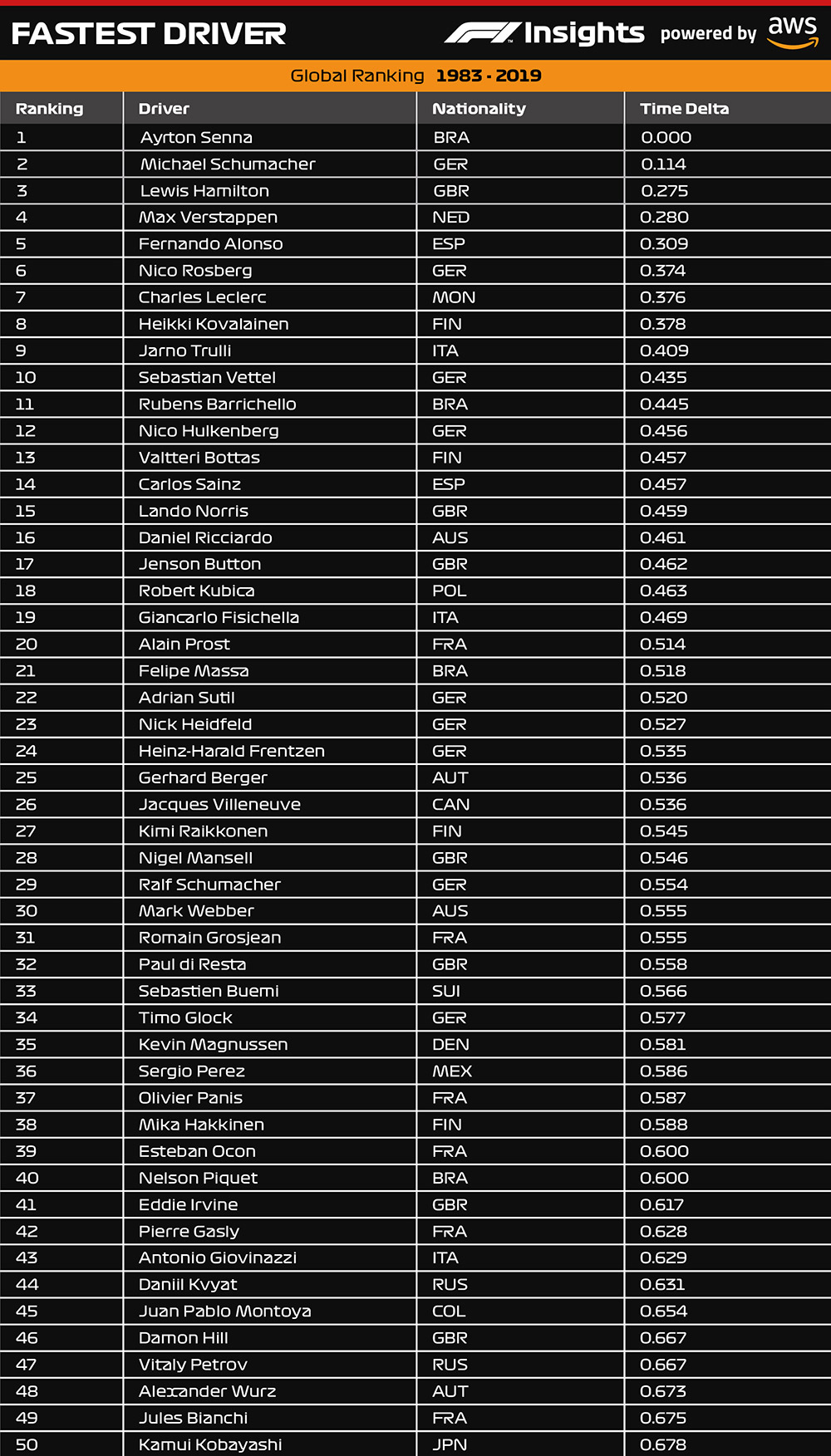
These rankings aren’t proposed as definitive, and there will no doubt be disagreement among fans. In fact, we encourage a healthy debate! Fastest Driver presents a scientific approach to driver ranking aimed at objectively assessing a driver’s performance controlling for car difference.
Lightweight and flexible deployment with Amazon SageMaker
To deliver the insights from Fastest Driver, we implemented Massey’s method on a Python web server. One complication was that the qualifying data consumed by the model is updated with fresh lap times after every race weekend. To handle this, in addition to the standard request to the web server for the rankings, we implemented a refresh request that instructs the server to download new qualifying data from Amazon Simple Storage Service (Amazon S3).
We deployed our model web server to an Amazon SageMaker model endpoint. This makes sure that our endpoint is highly available, because multi-instance Amazon SageMaker model endpoints are distributed across multiple Availability Zones by default, and have automatic scaling capabilities built in. As an additional benefit, the endpoints integrate with other Amazon SageMaker features, such as Amazon SageMaker Model Monitor, which automatically monitors model drift in an endpoint. Using a fully-managed service like Amazon SageMaker means our final architecture is very lightweight. To complete the deployment, we added an API layer around our endpoint using Amazon API Gateway and AWS Lambda. The following diagram shows this architecture in action.

The architecture includes the following steps:
- The user makes a request to API Gateway.
- API Gateway passes the request to a Lambda function.
- The Lambda function makes a request to the Amazon SageMaker model endpoint. If the request is for rankings, the endpoint computes the UDC rankings using the currently available qualifying data and returns the result. If the request is to refresh, the endpoint downloads the new qualifying data from Amazon S3.
Summary
In this post, we described how F1 and the Amazon ML Solutions Lab scientists collaborated to create Fastest Driver, the first objective and data-driven model to determine who might be the fastest driver ever. This collaborative work between F1 and AWS has provided a unique view of one of the sport’s most enduring questions by looking back at its history on its 70th anniversary. Although F1 is the first to employ ML in this way, you can apply the technology to answer complex questions in sports, or even settle age-old disputes with fans of rival teams. This F1 season, fans will have many opportunities to see Fastest Driver in action and launch into their own debates about the sport’s all-time fastest drivers.
Sports leagues around the world are using AWS machine learning technology to transform the fan experience. The Guinness Six Nations Rugby Championship competition and Germany’s Bundesliga use AWS to bring fans closer to the action of the game and deliver deeper insights. In America, the NFL uses AWS to bring advanced stats to fans, players, and the league to improve player health and safety initiatives using AI and ML.
If you’d like help accelerating your use of ML in your products and processes, please contact the Amazon ML Solutions Lab program.
About the Authors
 Rob Smedley has over 20 years of experience in the world of motorsport, having spent time at multiple F1 teams including Jordan, as a Race Engineer at Ferrari and most recently as Head of Vehicle Performance at Williams. He is now Director of Data systems at Formula 1, and oversees the F1 Insights program from a technical data side.
Rob Smedley has over 20 years of experience in the world of motorsport, having spent time at multiple F1 teams including Jordan, as a Race Engineer at Ferrari and most recently as Head of Vehicle Performance at Williams. He is now Director of Data systems at Formula 1, and oversees the F1 Insights program from a technical data side.
 Colby Wise is a Data Scientist and manager at the Amazon ML Solutions Lab, where he helps AWS customers across numerous industries accelerate their AI and cloud adoption.
Colby Wise is a Data Scientist and manager at the Amazon ML Solutions Lab, where he helps AWS customers across numerous industries accelerate their AI and cloud adoption.
 Delger Enkhbayar is a data scientist in the Amazon ML Solutions Lab. She has worked on a wide range of deep learning use cases in sports analytics, public sector and healthcare. Her background is in mechanism design and econometrics.
Delger Enkhbayar is a data scientist in the Amazon ML Solutions Lab. She has worked on a wide range of deep learning use cases in sports analytics, public sector and healthcare. Her background is in mechanism design and econometrics.
 Guang Yang is a data scientist at the Amazon ML Solutions Lab where he works with customers across various verticals and applies creative problem solving to generate value for customers with state-of-the-art ML/AI solutions.
Guang Yang is a data scientist at the Amazon ML Solutions Lab where he works with customers across various verticals and applies creative problem solving to generate value for customers with state-of-the-art ML/AI solutions.
 Ryan Cheng is a Deep Learning Architect in the Amazon ML Solutions Lab. He has worked on a wide range of ML use cases from sports analytics to optical character recognition. In his spare time, Ryan enjoys cooking.
Ryan Cheng is a Deep Learning Architect in the Amazon ML Solutions Lab. He has worked on a wide range of ML use cases from sports analytics to optical character recognition. In his spare time, Ryan enjoys cooking.
 George Price is a Deep Learning Architect at the Amazon ML Solutions Lab where he helps build models and architectures for AWS customers. Previously, he was a software engineer working on Amazon Alexa.
George Price is a Deep Learning Architect at the Amazon ML Solutions Lab where he helps build models and architectures for AWS customers. Previously, he was a software engineer working on Amazon Alexa.