AWS Cloud Operations Blog
Setting up secure, well-governed machine learning environments on AWS
When customers begin their machine learning (ML) journey, it’s common for individual teams in a line of business (LoB) to set up their own ML environments. This provides teams with flexibility in their tooling choices, so they can move fast to meet business objectives. However, a key difference between ML projects and other IT projects is that ML teams might need to use production data to train high-quality ML models. This is the case during exploratory, operational, and production phases of an ML project. Often, IT and ML teams struggle to build and organize secure and well-governed machine learning environments to enable production dataset workflows.
As the number of ML projects grows, the need to effectively isolate and manage these ML environments becomes more pressing. Generally, this responsibility falls under the central infrastructure and IT teams. Centralizing ML projects under a common operational model, with well-defined guardrails, allows organizations to quickly provision ML environments.
In this post, we’ll describe how you can organize, standardize, and expedite the provisioning of governed ML environments using recommended multi-account patterns on AWS.
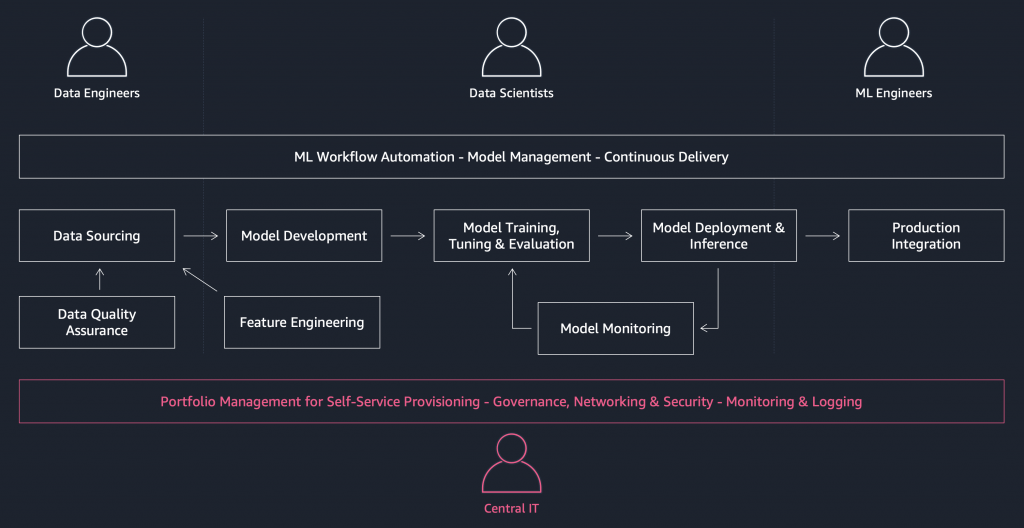
Figure 1: Example ML workflow with the associated personas
Overview
In this post, we’ll show you how to do the following:
- Structure organizational units (OUs) for your ML workloads.
- Using AWS Control Tower, apply guardrails in each OU for ongoing governance.
- Using AWS Organizations, limit permissions with service control policies (SCPs).
- Authenticate users in their ML environments.
- Provision ML environments on demand for your projects.
Structuring OUs for your ML workloads
An OU is a construct in AWS Organizations that allows customers to simplify the management of their accounts by grouping related accounts and administering them as a single unit. AWS Organizations enables you to programmatically create accounts and organize your account structure with a common set of policies or SCPs. An SCP applied at the OU level is inherited by all accounts under the OU. For more information, see the Best Practices for Organizational Units blog post.
In our example, we use AWS Control Tower to set up our multi-account environment with AWS Organizations. With just a few clicks in the AWS Control Tower console, you can set up and govern a secure multi-account environment.
Figure 2 shows a high-level OU structure that you can create to manage ML and data science environments.

Figure 2: Organizational unit structure
AWS recommends that you create a set of foundational OUs for security and infrastructure that serve the entire organization.
OU: Infrastructure
This OU hosts shared infrastructure services, such as networking and IT services, and is typically managed by your infrastructure teams. For example, networking and shared services accounts will be under this OU. Centralized package repositories, container repositories, and AWS Service Catalog portfolios for setting up ML environments can be placed in a shared services account.
OU: Security
This OU hosts security-related access and services and is managed by your security team. Access to data and security enforcement can be managed in this OU. Under this OU, you have a log archive account to centrally store logs from all accounts, including your ML accounts, and a set of security accounts, including a security read-only account, a security breakglass account, and security tooling accounts.
For more information about the foundational OUs, see the Organizing Your AWS Environment Using Multiple Accounts whitepaper.
The following OUs allow you to manage accounts related to your ML development lifecycle.
OU: Sandbox
This OU is for AWS accounts used by ML teams to learn and experiment with AWS services. Sandbox accounts can have less constrained security boundaries than production or managed development environments, to allow your teams to experiment. We recommend that accounts in this OU are detached from your internal networks and do not have access to corporate data.
OU: Workloads
When an LoB has a new ML workload, you can provision accounts in this OU. Following standard software development lifecycle practices, each project can have dev, preproduction, and production stages. Because each stage is expected to have a different policy grouping, we recommend that the accounts live in their respective OUs (for example, Workloads_Prod, Workloads_Dev). This allows you to apply environment-specific guardrails to the OUs hosting these accounts. You can use AWS Organizations if you need to place these OUs in a nested structure.
You can also create a team shared services account to manage AWS Service Catalog portfolios for ML, code repositories, and Amazon ECR container registries that are specific to the team or business unit. This account can also contain a central model registry of approved models or models to be approved for promotion to production.
The Workloads OU also consists of a data lake account for your ML platform. The data lake can be used to catalog, tag, and version your data (structured and unstructured) and manage fine-grained user access and permissions to different data sources. You can use AWS Lake Formation to manage this data lake. If you set up a central store for ML features, such as the Amazon SageMaker Feature Store, in this account, you can store, version, and share data features across ML projects. If you’re running workloads and hosting datasets that need to meet rigorous compliance and regulatory requirements (for example, HIPAA and PCI), you can create a separate OU.
OU: Deployments
This OU hosts CI/CD pipelines and is structured so that developers who use the pipelines cannot configure them. This ensures that a developer cannot circumvent security tooling configured in the pipeline (for example, to perform security checks on candidate code or models that the developer has pushed into the pipeline, or which the pipeline has pulled from a developer’s repo). For each ML project in the Workloads OU, you can create an account in the Deployments OU, to host CI/CD pipelines that can deploy project outputs to different destination accounts. We recommend that you have separate PreProd and Prod OUs in the Deployments OU, as described in Deployments OU in the whitepaper.
For simplicity, Figure 3 only shows the Deployments_Prod OU. It shows an example Infrastructure, Workloads, and Sandbox OU structure that you can implement to manage your ML and data science-related accounts:

Figure 3: OU structure for operating ML environments
Using AWS Control Tower to apply guardrails in each OU for ongoing governance
In this section, we show how you can limit permissions and establish controls in the OUs you have set up. A guardrail is a high-level rule that provides ongoing governance for your overall AWS environment. Through guardrails, AWS Control Tower implements preventive controls and detect-and-respond mechanisms that help you govern your resources and monitor compliance across groups of AWS accounts.
Data protection is an important consideration for ML workloads, especially when a project uses sensitive datasets from your organization or its clients. As an example, you can enable the detective Disallow public read access to S3 buckets guardrail on your Workloads OUs. This guardrail will detect whether a user has attempted to modify the bucket policy, bucket settings, or access control list to allow public read access for any accounts under the OU.
We set data security guardrails to set up detective controls on the following actions:
- Disallow public access to S3 buckets.
- Disallow S3 buckets that are not encrypted.
- Disallow S3 buckets that don’t have versioning enabled.

Figure 4: Three guardrails
To set up guardrails, in the left navigation pane of the AWS Control Tower console, choose Guardrails. Choose a guardrail, choose Enable Guardrail on OU, and then choose the OU.
In addition to these guardrails, you might need to implement other guardrails for standards compliance. We recommend that you consult your security, compliance, and legal teams to determine the full list of guardrails to implement for your machine learning workloads. For more information, see the How to Detect and Mitigate Guardrail Violation with AWS Control Tower blog post.
Using SCPs to limit permissions
Control Tower guardrails provide you with a starting point to prevent and detect compliance issues, but you might want to add custom guardrails or other SCPs and AWS Config rules. SCPs, which are managed by AWS Organizations, offer central control over the maximum available permissions for all accounts in your organization. An SCP sets limits on the actions that the account’s root user can use or delegate to the IAM users and roles in the account, or accounts in the OUs the SCP is applied to.
An example ML workload pattern might consist of prohibiting the deployment of SageMaker-hosted endpoints in sandbox or dev environments, which are intended primarily for model development and testing.
In the following example, we use the console to implement the SCP. In the real world, you might want to automate SCP management using the AWS CLI create-policy command or create_policy API action and associated CLI and SDK mechanisms for attaching SCPs to OUs or accounts. In the AWS Organizations console, choose Policies, choose Service Control Policies, and then choose Create policy. Enter a name and description for the policy. In Statement, choose SageMaker and then choose the APIs shown in Figure 5 to create the policy.

Figure 5: Example service control policy
Assessing SCP effectiveness
To illustrate the SCP setup, you can run the following SageMaker example notebook. The notebook will walk you through a text classification use case using a SageMaker built-in algorithm called BlazingText. After the model is trained, we try to deploy it to a SageMaker endpoint with the following command.
text_classifier = bt_model.deploy(initial_instance_count = 1,instance_type = 'ml.m4.xlarge')
When executing the command, we get the following error:

Figure 6: AccessDeniedException
Other ML-specific SCPs can include:
- Enforcing that all machine learning jobs (training, processing, model creation, and hosting) are encrypted using specific customer master keys (CMKs).
- Enforcing encryption in transit.
- Enforcing tagging on resources (notebooks, training or processing instances, hosted endpoints) for cost allocation.
- Restricting the underlying compute instances to certain types as a cost control or security mechanism (for example, requiring AWS Nitro instances).
You can use IAM condition keys to add more conditions to this policy. For example, you can add a condition to deny the creation of endpoints unless the request comes from your customer VPC.
For example, the following SCP will prevent users from launching any notebooks, training, or processing jobs unless a VPC is specified. For more examples, see the Millennium Management: Secure machine learning using Amazon SageMaker blog post.
When you use SCPs, be aware of these caveats and limitations. Consult your compliance and security stakeholders when you build SCPs.
Authenticating users in their ML environments
Now that you have established the guardrails, the next step is to authenticate users (data scientists, ML engineers) onto the platform. There are two primary ways to authenticate users into your ML environments:
Figure 7 shows the authentication flow for users signing into SageMaker Studio using IAM. The admin can create an AWS Service Catalog product to create SageMaker Studio domains in the Team Shared Services account in the Workloads OUs. This product can then be shared with the Project_Dev account, which inherits the constraints and tags from the centralized product and adds any local project-specific values. This product can now be used to provision Sagemaker Studio domains and user profiles in the Project_Dev account. Users can access their AWS environments through IAM federation by assuming temporary credentials. They can then launch Studio notebooks using the AWS Service Catalog console. If you want to further restrict users from having console access in development environments, you can automate the provisioning of secure access URLs (known as presigned URLs). For more information, see the Building secure Amazon SageMaker access URLs with AWS Service Catalog blog post. For SageMaker Studio, you have the option to further restrict the time-to-live (TTL) on this URL to reduce the risk of tampering or data exfiltration. You can also use attribute-based access controls (ABAC) to ensure that users only access their own notebook environments. For more information, see the Configuring Amazon SageMaker Studio for teams and groups with complete resource isolation blog post.
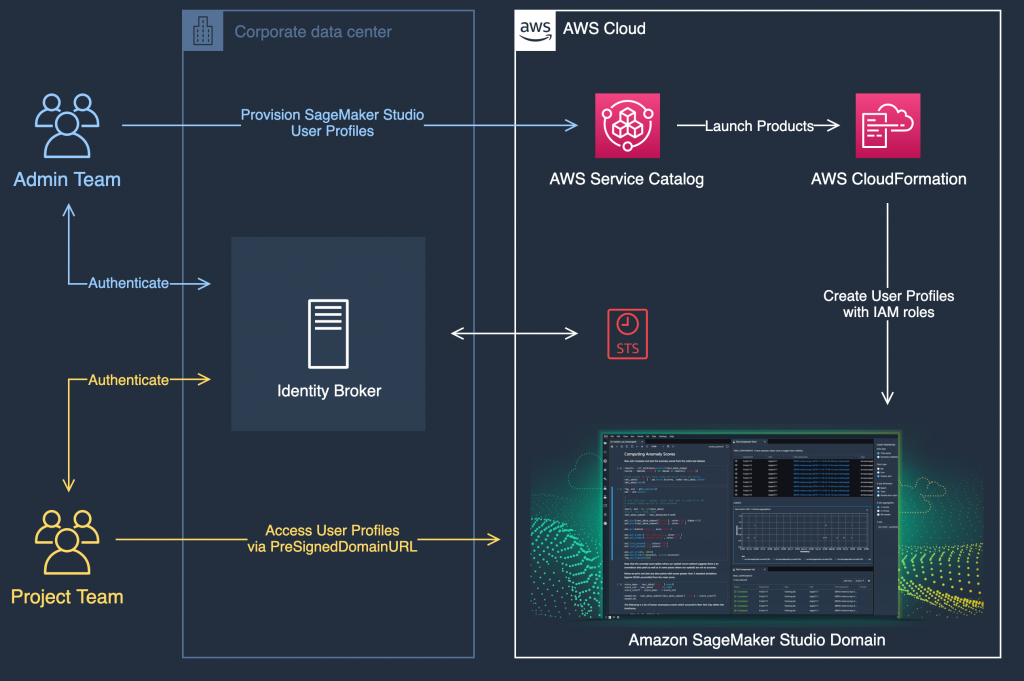
Figure 7: Authentication flow for users signing into SageMaker Studio using IAM
Provisioning ML environments on demand for your projects
In this section, we share example scenarios and corresponding account patterns you can adopt to enable ML projects.
Pattern 1: Experimenting on a sandbox account disconnected from the corporate network
Machine learning is a very iterative process. Project teams don’t always know the best approaches, libraries, and services to adopt before a project starts. In these cases, consider using a Project_Sandbox account disconnected from internal networks, with less constrained security boundaries. In this account, the project team can experiment with open-source libraries, AWS services, and publicly available datasets. They can start identifying approaches to apply to the corporate datasets later on. You can also set fixed spending limits for these accounts that can be monitored to prevent excessive use. Central IT teams can also share AWS Service Catalog portfolios from the Shared Services account, to help project teams quickly launch packaged solutions and experiment.
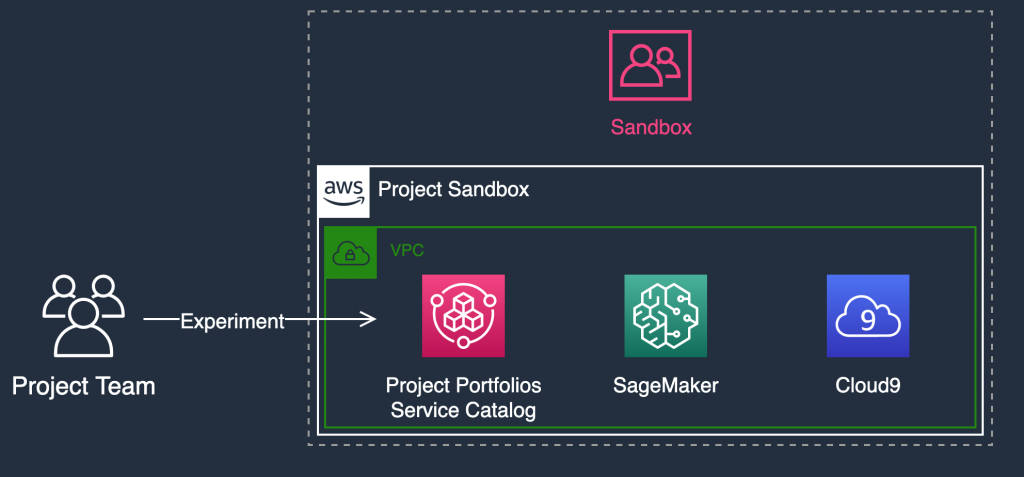
Figure 8: Sandbox OU implementation
Pattern 2: Experimenting in a project using corporate data
ML teams might need to work on exploratory projects that require access to corporate data. This is typically the case for proof-of-concept (PoC) and scientific research projects. For these projects, you can create Project_Dev accounts in the Workloads_Dev OU. Accounts in this OU have guardrails and security controls that allow them to connect to the corporate network in a governed manner. In those accounts, you can also allow project teams to deploy only standardized and approved solutions in a self-service manner using AWS Service Catalog. For more information about sharing and deploying ML products with AWS Service Catalog, see the Enabling self-service provisioning of AWS resources with AWS Control Tower and Building secure machine learning environments with Amazon SageMaker blog posts.
Depending on the use case, training and testing might require access to production data in the Project_Dev account, to ensure ML models reflect real-world behavior. This presents the unusual requirement for production data to be made available outside Prod accounts, which can raise additional requirements. If data in Prod is considered sensitive as part of a compliance requirement, copying unmodified data into the Project_Dev account might bring the Project_Dev environment into compliance scope. Minimizing compliance scope is frequently desirable.
The most intensive aspects of data science are data preparation and feature engineering. Early in the ML process, it will become apparent which fields in a dataset are significant in informing model behavior. However, it make take some effort to identify the transformations that are most useful in a feature engineering process to enhance differences between fields. This means that the dataset the ML team needs to train and test models might not need to be a copy of the full dataset from Prod. If some data elements in the Prod dataset are considered sensitive, you can redact fields irrelevant to the ML process from the dataset copy destined for the Project_Dev account in the Prod environment, before the redacted copy is exported into the relevant Project_Dev account. You can perform this redaction on the production side using Lambda functions with Amazon Macie to identify and redact personally identifiable information (PII) before the data is copied to the Project_Dev environment. You can also use Amazon AppFlow to perform simple redaction or combination of columnar data, which may serve as a further data anonymisation mechanism or initial element of feature engineering. These suggestions might help contain compliance scopes to your Prod accounts, subject to discussion with your auditors.
If redaction would transform the data to an extent that it becomes unusable for training or testing, and if model accuracy is not the first priority, you can use differential privacy techniques to copy the data in the production environment. These techniques are known to result in degraded model accuracy. For information, see Privacy Amplification by Subsampling: Tight Analyses via Couplings and Divergences. Your ML team should work with prod maintainers to provide a production-side mechanism for performing pragmatic elements of data cleaning and feature engineering, to minimize the sensitivity of the dataset in the Project_Dev environment.
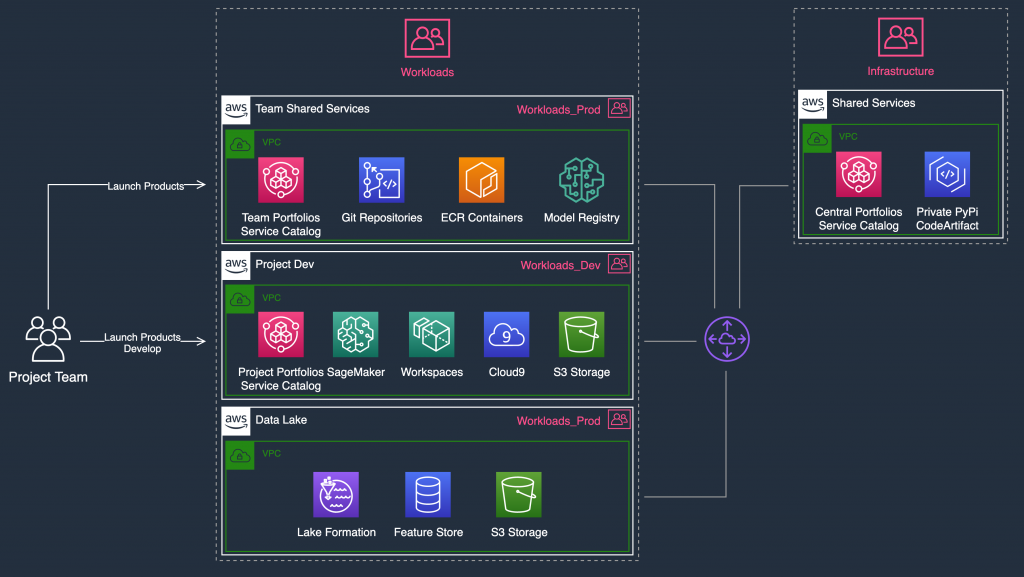
Figure 9: Example account implementation
You can set up the following in this architecture:
- With AWS Cloud9 and Amazon SageMaker, you can deploy managed development environments secured in the cloud and remotely accessed by your ML teams to work on their project.
- You can set a read-only access policy when accessing data from the Data Lake account, and allow project teams to self-provision local S3 buckets in the Project_Dev account. This allows the team to work locally on data stages based on their ML workflow. You could allow the team to push data back to the data lake after approval, for reuse.
- You can set a central features store in the Data Lake account for reuse and allow teams to have their local feature store for development. For more information, see the Enable feature reuse across accounts and teams using Amazon SageMaker Feature Store blog post.
- In the Infrastructure OU, you can use AWS CodeArtifact in the Shared Services account to host private, approved Python packages for data scientists to use in their project.
- You can set up Amazon Workspaces for additional security in the Project_Dev environment. When you use Amazon Workspaces, no access credentials, data, or code associated with the models are stored on the ML team’s local devices. The PCoIP client configuration used in Amazon Workspaces instances can be configured to prevent clipboard forwarding, making it impossible to copy or paste data between an ML team member’s own device and their environment. This helps mitigate the risk of data or code exfiltration.
Pattern 3: Operationalizing an ML project (MLOps) using cross-account deployments
The team might want to adopt MLOps practices to bring the solution into production. By creating Project_PreProd and Project_Prod accounts in the Workloads OUs, you can provide a high level of resource and security isolation between the operational stages of your deployments. You can set up cross-account CI/CD pipelines in the Deployments OU under an Automation account. Central IT teams enforce governance on the CI/CD pipelines so ML solutions are safely deployed into Project_Prod.
For more information, see the Building a Secure Cross-Account Continuous Delivery Pipeline blog post and Build a Secure Enterprise Machine Learning Platform on AWS whitepaper.
Figure 10 shows an account layout you can use to operationalize an ML project.
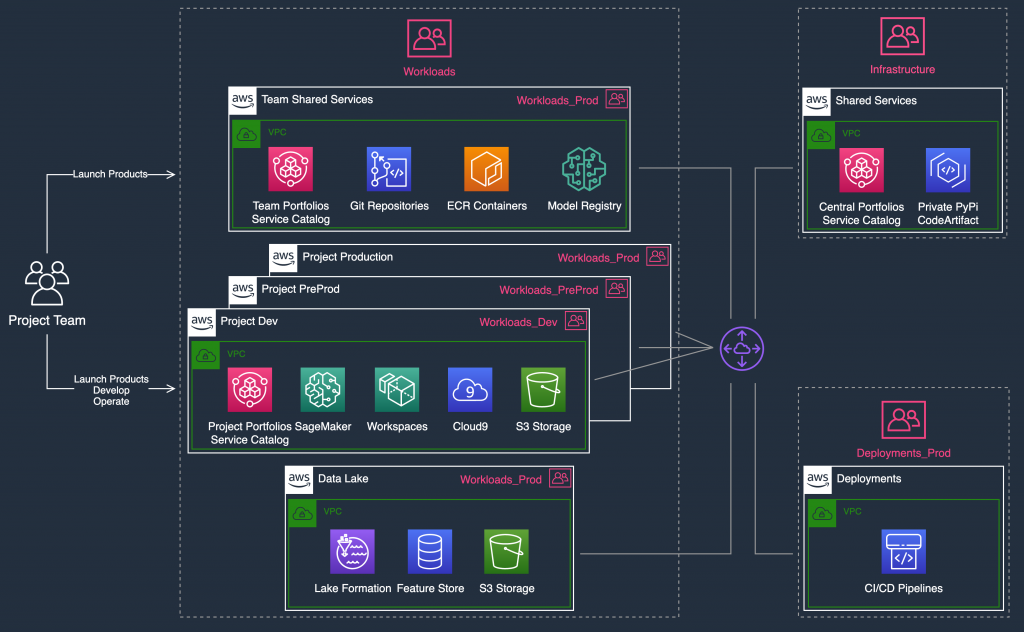
Figure 10: Example MLOps implementation
Although these account patterns apply to many ML projects, some cases might require special attention:
- When dealing with data classified as sensitive.
- When using the ML platform as a software as a service (SaaS) offering on AWS for internal or external customers who might belong to different organizations with their own requirements.
For these cases, you might adopt different OU structures and account layouts as appropriate for your governance needs.
Conclusion
A well-architected multi-account strategy helps ML teams innovate faster on AWS, while ensuring that they meet enterprise security and governance requirements. In this post, we have showed how you can structure OUs for ML workloads based on AWS-recommended multi-account practices. We showed how to apply guardrails and limit permissions using SCPs in each OU and authenticate users into their ML environments. Finally, we shared example scenarios and account patterns you can adopt for ML projects.
Learn how customers like AstraZeneca use a single-tenant multi-account approach and preapproved application stack elements in AWS Service Catalog, to streamline pharmaceutical drug discovery, clinical trials, and patient safety for hundreds of scientists.