Artificial Intelligence
Building secure machine learning environments with Amazon SageMaker
As businesses and IT leaders look to accelerate the adoption of machine learning (ML) and artificial intelligence (AI), there is a growing need to understand how to build secure and compliant ML environments that meet enterprise requirements. One major challenge you may face is integrating ML workflows into existing IT and business work streams. A second challenge is bringing together stakeholders from business leadership, data science, engineering, risk and compliance, and cybersecurity to define the requirements and guardrails for the organization. Third, because building secure ML environments in the cloud is a relatively new topic, understanding recommended practices is also helpful.
In this post, we introduce a series of hands-on workshops and associated code artifacts to help you build secure ML environments on top of Amazon SageMaker, a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy ML models quickly. The objective of these workshops is to address the aforementioned challenges by helping bring together different IT stakeholders and data scientists and provide best practices to build and operate secure ML environments. These workshops are a summary of recommended practices from large enterprises and small and medium businesses. You can access these workshops on Building Secure Environments, and you can find the associated code on GitHub. We believe that these workshops are valuable for the following primary teams:
- Cloud engineering – This team is responsible for creating and maintaining a set of enterprise-wide guardrails for operating in the cloud. Key requirements for these teams include isolation from public internet, restriction of data traffic flows, use of strict AWS Identity and Access Management (IAM) controls to allow only authorized and authenticated users the ability to access project resources, and the use of defense-in-depth methodologies to detect and mitigate potential threats. This team can use tools like AWS Service Catalog to build repeatable patterns using infrastructure as code (IaC) practices via AWS CloudFormation.
- ML platform: This team is responsible for building and maintaining the infrastructure for supporting ML services, such as provisioning notebooks for data scientists to use, creating secure buckets for storing data, managing costs for ML from various lines of business (LOBs), and more.
- Data science COE: Data scientists within an AI Center of Excellence (COE) or embedded within the LOBs are responsible for building, training, and deploying models. In regulated industries, data scientists need to adhere to the organization’s security boundaries, such as using encrypted buckets for data access, use of private networking for accessing APIs, committing code to source control, ensuring all their experiments and trials are properly logged, enforcing encryption of data in transit, and monitoring deployed models.
The following diagram is the architecture for the secure environment developed in this workshop.

In the Building Secure Environments workshop aimed at the cloud engineering and ML platform teams, we cover how this architecture can be set up in Labs 1–2. Specifically, we use AWS Service Catalog to provision a Shared Services Amazon Virtual Private Cloud (Amazon VPC), which hosts a private PyPI package repository to pull packages from an Amazon Simple Storage Service (Amazon S3) bucket via a secure VPC endpoint.
After the environment is provisioned, the following architecture diagram illustrates the typical data scientist workflow within the project VPC, which is covered in detail in the workshop Using Secure Environments aimed at data scientists.

This workshop quickly sets up the secure environment (Steps 1–3) and then focuses on using SageMaker notebook instances to securely explore and process data (Steps 4–5). Following that, we train a model (Steps 6–7) and deploy and monitor the model and model metadata (8–9) while enforcing version control (Step 4).
The workshops and associated code let you implement recommended practices and patterns and help you to quickly get started building secure environments, and improve productivity with the ability to securely build, train, deploy and monitor ML models. Although the workshop is built using SageMaker notebook instances, in this post we highlight how you can adapt this to Amazon SageMaker Studio. Although the workshop is built using SageMaker notebook instances, in this post we highlight how you can adapt this to Amazon SageMaker Studio, the first integrated development environment for machine learning on AWS.
Workshop features
The workshop is a collection of feature implementations grouped together to provide a coherent starting point for customers looking to build secure data science environments. The features implemented are broadly categorized across seven areas:
- Enforce your existing IT policies in your AWS account and data science environment to mitigate risks
- Create environments with least privilege access to sensitive data in the interest of reducing the blast radius of a compromised or malicious actor
- Protect sensitive data against data exfiltration using a number of controls designed to mitigate the data exfiltration risk
- Encrypt sensitive data and intellectual property at rest and in transit as part of a defense-in-depth strategy
- Audit and trace activity in your environment
- Reproduce results in your environment by tracking the lineage of ML artifacts throughout the lifecycle and using source and version control tools such as AWS CodeCommit
- Manage costs and allow teams to self service using a combination of tagging and the AWS Service Catalog to automate building secure environments
In the following sections, we cover in more depth how these different features have been implemented.
Enforcing existing IT policies
When entrusting sensitive data to AWS services, you need confidence that you can govern your data to the same degree with the managed service as if you were running the service yourself. A typical starting point to govern your data in an AWS environment is to create a VPC that is tailored and configured to your standards in terms of information security, firewall rules, and routing. This becomes a starting point for your data science environment and the services that projects use to deliver on their objectives. SageMaker, and many other AWS services, can be deployed into your VPC. This allows you to use network-level controls to manage the Amazon Elastic Compute Cloud (Amazon EC2)-based resources that reside within the network. To learn about how to set up SageMaker Studio in a private VPC, see Securing Amazon SageMaker Studio connectivity using a private VPC.
The network-level controls deployed as a part of this workshop include the following:
- Security groups to manage which resources and services, such as SageMaker, can communicate with other resources in the VPC
- VPC endpoints to grant explicit access to specific AWS services from within the VPC, like Amazon S3 or Amazon CloudWatch
- VPC endpoints to grant explicit access to customer-managed shared services such as a PyPi repository server
The shared service PyPi repository demonstrates how you can create managed artifact repositories that can then be shared across project environments. Because the environments don’t have access to the open internet, access to common package and library repositories is restricted to your repositories that hold your packages. This limits any potential threats from unapproved packages entering your secure environment.
With the launch of AWS CodeArtifact, you can now use CodeArtifact as your private PyPi repository. CodeArtifact provides VPC endpoints to maintain private networking. To learn more about how to integrate CodeArtifact with SageMaker notebook instances and Studio notebooks, see Private package installation in Amazon SageMaker running in internet-free mode.
In addition to configuring a secure network environment, this workshop also uses IAM policies to create a preventive control that requires that all SageMaker resources be provisioned within a customer VPC. An AWS Lambda function is also deployed as a corrective control to stop any SageMaker resources that are provisioned without a VPC attachment.
One of the unique elements of SageMaker notebooks is that they are managed EC2 instances in which you can tailor the operating system. This workshop uses SageMaker lifecycle configuration policies to configure the Linux operating system of the SageMaker notebook to be inline with IT policy, such as disabling root access for data scientists. For SageMaker Studio, you can enforce your IT policies of using security approved containers and packages for running notebooks by bringing your own custom image. SageMaker handles versioning of the images, and provides data scientists with a user-friendly drop-down to select the custom image of their choice.
Labs 1–3 in the Building Secure Environments and Labs 1–2 in the Using Secure Environments workshops focus on how you can enforce IT policies on your ML environments.
Least privilege access to sensitive data
In the interest of least privileged access to sensitive data, it’s simpler to provide isolated environments to any individual project. These isolated environments provide a method of restricting access to customer-managed assets, datasets, and AWS services on a project-by-project basis, with a lower risk of cross-project data movement. The following discusses some of the key mechanisms used in the workshops to provide isolated, project-specific environments. The workshop hosts multiple projects in a single AWS account, but given sufficient maturity of automation, you could provide the same level of isolation using project-specific AWS accounts. Although you can have multiple SageMaker notebook instances within a single account, you can only have one Studio domain per Region in an account. You can therefore use a domain to create isolated project-specific environments in separate accounts.
To host multiple projects in a single AWS account, the workshop dedicates a private, single-tenant VPC to each project. This creates a project-specific network boundary that grants access to specific AWS resources and services using VPC endpoints and endpoint policies. This combination creates logically isolated single-tenant project environments that are dedicated to a project team.
In addition to a dedicated network environment, the workshop creates AWS resources that are dedicated to individual projects. S3 buckets, for instance, are created per project and bound to the VPC for the project. An S3 bucket policy restricts the objects in the bucket to only be accessed from within the VPC. Equally, the endpoint policy associated with the Amazon S3 VPC endpoint within the VPC only allows principals in the VPC to communicate with those specific S3 buckets. This could be expanded as needed in order to support accessing other buckets, perhaps in conjunction with an Amazon S3-based data lake.
Other AWS resources that are created on behalf of an individual project include IAM roles that govern who can access the project environment and what permissions they have within the environment. This prevents other project teams from accessing resources in the AWS account that aren’t dedicated to that other project.
To manage intellectual property developed by the project, a CodeCommit repository is created to provide the project with a dedicated Git repository to manage and version control their source code. We use CodeCommit to commit any code developed in notebooks by data scientists in Labs 3–4 in the Using Secure Environments workshop.
Protecting against data exfiltration
As described earlier, project teams have access to AWS services and resources like Amazon S3 and objects in Amazon S3 through the VPC endpoints in the project’s VPC. The isolated VPC environment gives you full control over the ingress and egress of data flowing across the network boundary. The workshop uses security groups to govern which AWS resources can communicate with specific AWS services. The workshop also uses VPC endpoint policies to limit the AWS resources that can be accessed using the VPC endpoints.
When data is in Amazon S3, the bucket policy applied to the bucket doesn’t allow resources from outside the VPC to read data from the bucket, ensuring that it’s bound, as a backing store, to the VPC.
Data protection
The application of ML technologies is often done using sensitive customer data. This data may contain commercially sensitive, personal identifiable, or proprietary information that must be protected over the data’s lifetime. SageMaker and associated services such as Amazon Elastic Container Registry (Amazon ECR), Amazon S3, and CodeCommit all support end-to-end encryption both at rest and in transit.
Encryption at rest
SageMaker prefers to source information from Amazon S3, which supports multiple methods of encrypting data. For the purposes of this workshop, the S3 buckets are configured to automatically encrypt objects with a specified customer master key (CMK) that is stored in AWS Key Management Service (AWS KMS). A preventive control is also configured to require that data put into Amazon S3 is encrypted using a KMS key. These two mechanisms ensure that data stored in Amazon S3 is encrypted using a key that is managed and controlled by the customer.
Similar to Amazon S3, Amazon ECR is also used to store customer-built Docker containers that are likely to contain intellectual property. Amazon ECR supports the encryption of images at rest using a CMK. This enables you to support PCI-DSS compliance requirements for separate authentication of the storage and cryptography. With this feature enabled, Amazon ECR automatically encrypts images when pushed, and decrypts them when pulled.
As data is moving into SageMaker-managed resources from Amazon S3, it’s important to ensure that the encryption at rest of the data persists. SageMaker supports this by allowing the specification of KMS CMKs for encrypting the EBS volumes that hold the data retrieved from Amazon S3. Encryption keys can be specified to encrypt the volumes of all Amazon EC2-based SageMaker resources, such as processing jobs, notebooks, training jobs, and model endpoints. A preventive control is deployed in this workshop, which allows the provisioning of SageMaker resources only if a KMS key has been specified to encrypt the volumes.
Encryption in transit
AWS makes extensive use of HTTPS communication for its APIs. The services mentioned earlier are no exception. In addition to passing all API calls through a TLS encrypted channel, AWS APIs also require that requests are signed using the Signature version 4 signing process. This process uses client access keys to sign every API request, adding authentication information as well as preventing tampering of the request in flight.
As services like SageMaker, Amazon S3, and Amazon ECR interact with one another, they must also communicate using Signature V4 signed packets over encrypted HTTPS channels. This ensures that communication between AWS services is encrypted to a known standard, protecting customer data as it moves between services.
When communicating with SageMaker resources such as notebooks or hosted models, the communication is also performed over authenticated and signed HTTPS requests as with other AWS services.
Intra-node encryption
SageMaker provides added benefit to secure your data when training using distributed clusters. Some ML frameworks when performing distributed training pass coefficients between the different instances of the algorithm in plain text. This shared state is not your training data, but is the information that the algorithms require to stay synchronized with one another. You can instruct SageMaker to automatically encrypt inter-node communication for your training job. The data passed between nodes is then passed over an encrypted tunnel without your algorithm having to take on responsibility for encrypting and decrypting the data. To enable inter-node encryption, ensure that your security groups are configured to permit UDP traffic over port 500 and that you have set EnableInterContainerTrafficEncryption to True. For more detailed instructions, see Protect Communications Between ML Compute Instances in a Distributed Training Job.
Ensuring encryption at rest and in transit during the ML workflow is covered in detail in Labs 3–4 of the Using Secure Environments workshop.
Traceability, reproducibility, and auditability
A common pain point that you may face is a lack of recommended practices around code and ML lifecycle traceability. Often, this can arise from data scientists not being trained in MLOps (ML and DevOps) best practices, and the inherent experimental nature of the ML process. In regulated industries such as financial services, regulatory bodies such as the Office of the Comptroller of the Currency (OCC) and Federal Reserve Board (FRB) have documented guidelines on managing the risk of analytical models.
Lack of best practices around documenting the end-to-end ML lifecycle can lead to lost cycles in trying to trace the source code, model hyperparameters, and training data. The following figure shows the different steps in the lineage of a model that may be tracked for traceability and reproducibility reasons.
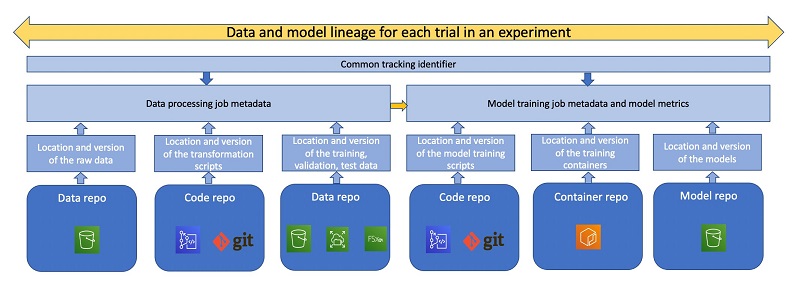
Traceability refers to the ability to map outputs from one step in the ML cycle to the inputs of another, thereby having a record of the entire lineage of a model. Enforcing data scientists to use source and version control tools such as Git or BitBucket to regularly check in code, and not approve or promote models until code has been checked in, can help mitigate this issue. In this workshop, we provision a private CodeCommit repository for use by data scientists, along with their notebook instance. Admins can tag these repositories to the users, to identify the users responsible for the commits, and ensure code is being frequently checked into source control. One way to do this is to use project-specific branches, and ensure that the branch has been merged with the primary branch in the shared services environment prior to being promoted to pre-production or test. Data scientists should not be allowed to directly promote code from dev to production without this intermediate step.
In addition to versioning code, versioning data used for training models is important as well. All the buckets created in this workshop have versioning automatically enabled to enforce version control on any data stored there, such as training data, processed data, and training, validation and test data. SageMaker Experiments automatically keeps track of the pointer to the specific version of the training data used during model training.
Data scientists often tend to explore data in notebooks, and use notebooks to engineer features as well. In this workshop, we demonstrate how to use SageMaker Processing to not only offload the feature engineering code from the notebook instance onto separate compute instances to run at scale, but also to subsequently track parameters used for engineering features in SageMaker Experiments for reproducibility reasons. SageMaker recently launched SageMaker Clarify, which allows you to detect bias in your data as well as extract feature importances. You can run these jobs as you would run SageMaker Processing jobs using the Clarify SDK.
Versioning and tagging experiments, hyperparameter tuning jobs, and data processing jobs allow data scientists to collaborate faster. SageMaker Experiments automatically tracks and logs metadata from SageMaker training, processing, and batch transform jobs, and surfaces relevant information such as model hyperparameters, model artifact location, model container metadata in a searchable way. For more information, see Amazon SageMaker Experiments – Organize, Track And Compare Your Machine Learning Trainings.
Additionally, it keeps track of model metrics that allow data scientists to compare different trained models and identify the ones that meet their business objectives. You can also use SageMaker Experiments to track which user launched a training job and use IAM condition keys to enforce resource tags on the Experiment APIs.
Additionally, in SageMaker Studio, SageMaker Experiments tracks the user profile of the user launching jobs, providing additional auditability. We demonstrate the use of SageMaker Experiments and how you can use Experiments to search for specific trials and extract the model metadata in Labs 3–4 of the Using Secure Environments workshop.
Although accurately capturing the lineage of ML models can certainly help reproduce the model outputs, depending on the model’s risk level, you may also be required to document feature importance from your models. In this workshop, we demonstrate one methodology for doing so, using Shapley values. We note however that this approach is by no means exhaustive and you should work with your risk, legal, and compliance teams to assess legal, ethical, regulatory, and compliance requirements for, and implications of, building and using ML systems.
Deployed endpoints should be monitored against data drift as a best practice. In these workshops, we demonstrate how SageMaker Model Monitor automatically extracts the statistics from the features as a baseline, captures the input payload and the model predictions, and checks for any data drift against the baseline at regular intervals. The detected drift can be visualized using SageMaker Studio and used to set thresholds and alarms to re-trigger model retraining or alert developers of model drift.
To audit ML environments, admins can monitor instance-level metrics related to training jobs, processing jobs, and hyperparameter tuning jobs using CloudWatch Events. You can use lifecycle configurations to also publish Jupyter logs to CloudWatch. Here we demonstrate the use of detective and preventive controls to prevent data scientists from launching training jobs outside the project VPC. Additional preventive controls using IAM condition keys such as sagemaker:InstanceTypes may be added to prevent data scientists from misusing certain instance types (such as the more expensive GPU instances) or enforcing that data scientists only train models using AWS Nitro System instances, which offer enhanced security. Studio notebook logs are automatically published to CloudWatch.
Self-service
Customers are rapidly adopting IaC best practices using tools such as AWS CloudFormation or HashiCorp Terraform to ensure repeatability across their cloud workflows. However, a consistent pain point for data science and IT teams across enterprises has been the challenge to create repeatable environments that can be easily scaled across the organization.
AWS Service Catalog allows you to build products that abstract the underlying CloudFormation templates. These products can be shared across accounts, and a consistent taxonomy can be enforced using the TagOptions Library. Administrators can design products for the data science teams to run in their accounts that provision all the underlying resources automatically, while allowing data scientists to customize resources such as underlying compute instances (GPU or CPU) required for running notebooks, but disallowing data scientists from creating notebook instances any other way. Similarly, admins can enforce that data scientists enter their user information while creating products to have visibility on who is creating notebooks.
To allow teams to move at speed and to free constrained cloud operations teams from easily automated work, this workshop uses the AWS Service Catalog to automate common activities such as SageMaker notebook creation. AWS Service Catalog provides you with a way to codify your own best practice for deploying logically grouped assets, such as a project team environment, and allow project teams to deploy these assets for themselves.
The AWS Service Catalog allows cloud operations teams to give business users a way to self-service and obtain on-demand assets that are deployed in a manner compliant with internal IT policies. Business users no longer have to submit tickets for common activities and wait for the ticket to be serviced by the cloud operations team. Additionally, AWS Service Catalog provides the cloud operations team with a centralized location to understand who has deployed various assets and manage those deployed assets to ensure that, as IT policy evolves, updates can be provided across provisioned products. This is covered in detail in Labs 1–2 of the Building Secure Environments workshop.
Cost management
It’s important to be able to track expenses during the lifecycle of a project. To demonstrate this capability, the workshop uses cost tags to track all resources associated with any given project. The cost tags used in this workshop tag resources like SageMaker training jobs, VPCs, and S3 buckets with the project name and the environment type (development, testing, production). You can use these tags to identify a project’s costs across services and your environments to ensure that teams are accountable for their consumption. You can also use SageMaker Processing to offload feature engineering tasks and SageMaker Training jobs to train models at scale, and use lightweight notebooks and further save on costs. As we show in this workshop, admins can enforce this directly by allowing data scientists to create notebooks only via AWS Service Catalog using approved instance types only.
Conclusion
In this series of workshops, we have implemented a number of features and best practices that cover the most common pain points that CTO teams face when provisioning and using secure environments for ML. Try them out today! You can access these workshops on Building Secure Environments, and you can find the associated code on GitHub. For a detailed discussion on ML governance as it applies to regulated industries such as financial services, see Machine Learning Best Practices in Financial Services. Additionally, you may want to look at the AWS Well-Architected guidelines as they apply to machine learning and financial services, respectively. Feel free to connect with the authors and don’t hesitate to reach out to your AWS account teams if you wish to run these hands-on labs.
Further reading
About the Authors
 Jason Barto works as a Principal Solutions Architect with AWS. Jason supports customers to accelerate and optimize their business by leveraging cloud services. Jason has 20 years of professional experience developing systems for use in secure, sensitive environments. He has led teams of developers and worked as a systems architect to develop petabyte scale analytics platforms, real-time complex event processing systems, and cyber-defense monitoring systems. Today he is working with financial services customers to implement secure, resilient, and self-healing data and analytics systems using open-source technologies and AWS services
Jason Barto works as a Principal Solutions Architect with AWS. Jason supports customers to accelerate and optimize their business by leveraging cloud services. Jason has 20 years of professional experience developing systems for use in secure, sensitive environments. He has led teams of developers and worked as a systems architect to develop petabyte scale analytics platforms, real-time complex event processing systems, and cyber-defense monitoring systems. Today he is working with financial services customers to implement secure, resilient, and self-healing data and analytics systems using open-source technologies and AWS services
 Stefan Natu is a Sr. AI/ML Specialist Solutions Architect at Amazon Web Services. He is focused on helping financial services customers build end-to-end machine learning solutions on AWS. In his spare time, he enjoys reading machine learning blogs, playing the guitar, and exploring the food scene in New York City.
Stefan Natu is a Sr. AI/ML Specialist Solutions Architect at Amazon Web Services. He is focused on helping financial services customers build end-to-end machine learning solutions on AWS. In his spare time, he enjoys reading machine learning blogs, playing the guitar, and exploring the food scene in New York City.