AWS Public Sector Blog
Automated Earth observation using AWS Ground Station Amazon S3 data delivery
June 2023: This walkthrough was updated to move the technical implementation guide to a new code repository. The solution has been updated to use Ubuntu 20.04 to support IPOPP v5.0 from NASA DRL.
With AWS Ground Station, you can now deliver data directly into Amazon Simple Storage Service (Amazon S3) buckets. This simplifies downlinking because you no longer need to run an Amazon Elastic Compute Cloud (Amazon EC2) receiver instance. It also saves you cost and simplifies the creation of automated processing pipelines like the one we are going to show in this blog.
This blog post describes a solution that creates an automated earth observation (EO) pipeline using the AWS Ground Station Amazon S3 data delivery solution and NASA Direct Readout Laboratory (DRL) software. This walkthrough also links to a code repository which contains detailed implementation instructions.
About the NOAA-20 satellite
The solution presented creates an automated EO pipeline that receives and processes data from the NOAA-20 (JPSS-1) satellite. NOAA-20 was launched in 2017 and is part of the United States National Oceanic and Atmospheric Administration’s (NOAA) latest generation of US polar-orbiting, non-geosynchronous, environmental satellites called the Joint Polar Satellite System (JPSS). It orbits the Earth in a Sun-synchronous near-polar orbit at an altitude of 825km, which makes it a low Earth orbit (LEO) satellite. NOAA-20 has five active sensing instruments. These are a substantial upgrade over the previous generation of instruments on board the Aqua and Terra spacecraft. Using these new instruments, the craft can provide greater-detailed observations that can make better predictions and highlight climate behavior in cases like El Niño and La Niña.
Solution overview: Automated Earth observation using AWS Ground Station Amazon S3 data delivery
In this solution, we analyze data from the Visible Infrared Imaging Radiometer Suite (VIIRS) onboard NOAA-20. NOAA-20 broadcasts Consultative Committee for Space Data Systems (CCSDS)-compliant Channel Access Data Unit (CADU) data frames. These are downlinked, demodulated, decoded, and stored in VITA 49 format in your Amazon S3 bucket by the new Amazon S3 data delivery feature of AWS Ground Station. The payload is then extracted from the .pcap files and stored as raw data in your Amazon S3 bucket. The CADUs are processed into Level 0 data products using NASA’s Real-Time Software Telemetry Processing System (RT-STPS). Level 0 data is then pushed to Amazon S3. International Planetary Observation Processing Package (IPOPP), also provided by NASA, is used to process Level 0 data into higher-level products. For example, Level 1 Hierarchical Data Format (HDF) files and Level 2 HDF files and Tag Image File Format (TIFF) images. IPOPP is installed and configured on the processor Amazon EC2 instance, which then pushes the Level 1 and Level 2 data products to Amazon S3. Once in Amazon S3, data products can be published to data subscribers or retrieved by other AWS services, such as Amazon SageMaker or Amazon Rekognition, for near real-time processing.
By using an automated EO pipeline, you can reduce the operating burden of your staff, as after scheduling a contact, everything is handled automatically and you’ll get a notification when the processed data is available.
High-level solution architecture
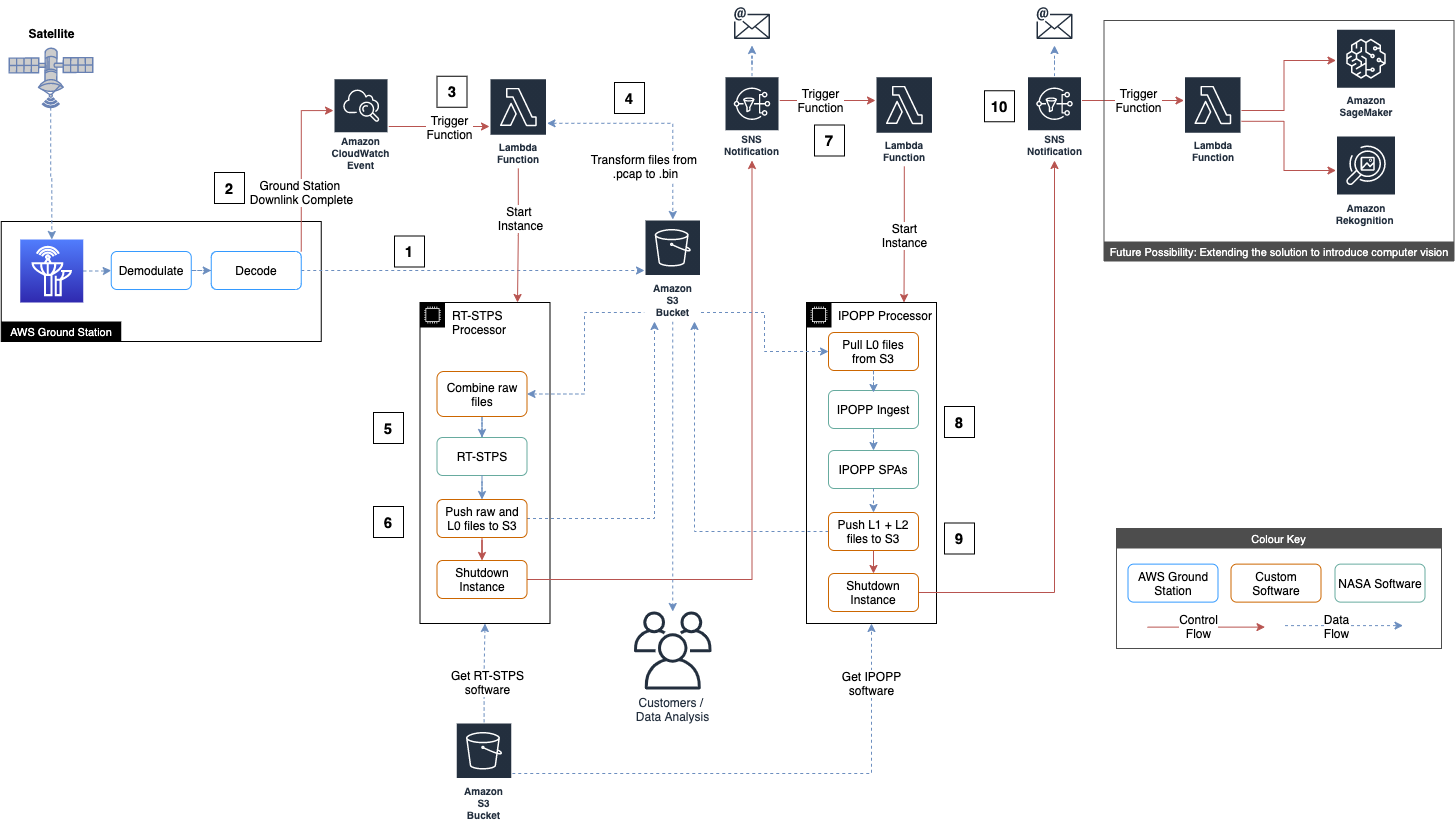
How the solution operates:
- During a satellite contact, the AWS Ground Station Amazon S3 data delivery services deposit the downlink data as VITA 49 in .pcap files in an Amazon S3 bucket.
- When all .pcap files have been written an Amazon CloudWatch event is generated.
- The CloudWatch event triggers an AWS Lambda function.
- The Lambda function strips out the payload data from the .pcap files into .bin raw data files, then starts the RT-STPS processor Amazon EC2 instance.
- The RT-STPS Amazon EC2 instance combines the raw data into a single file, which it then processes into Level 0 data using RT-STPS.
- The RT-STPS EC2 instance pushes the data to Amazon S3, sends an Amazon Simple Notification Service (Amazon SNS) notification, then shuts down.
- The Amazon SNS notification triggers a Lambda function, which starts up the IPOPP processor Amazon EC2 instance.
- The IPOPP Amazon EC2 instance pulls the data from Amazon S3, then processes it using IPOPP. This step takes about 80 minutes.
- The IPOPP Amazon EC2 instance pushes the Level 1A, Level 1B, and Level 2 data it produces to Amazon S3.
- The IPOPP Amazon EC2 instance sends an Amazon SNS notification then shuts down.
Visit the code repository to find a detailed step-by-step breakdown of the above solution architecture.
To summarize the architecture, by scheduling a satellite contact in AWS GroundStation, all of the steps are automatically completed, which results in the data being made available in the Amazon S3 bucket. If you subscribe to the Amazon SNS notifications, you will also receive emails with the output of the processing jobs.
Earth observation science data levels
Earth observation data products are most commonly described using Levels 0-4 provided by NASA. Find more detailed descriptions of the following levels on NASA’s website.
- Level 0: Raw data from sensors with communications artifacts removed
- Level 1: Georeferenced and adjusted for known sources of error or interference
- Level 2: Specific data-rich products such as sea surface temperature data or visible light data
- Level 3: Data mapped onto uniform space-time grid scales
- Level 4: Model output or results from deeper analysis of lower-level data, often using data from multiple measurements
This GitHub repository walks you through downlinking Level 0 data from JPSS-1, and then generating Level 1 and Level 2 data products during the processing steps. All data will be automatically delivered to Amazon S3.
Implementation
Follow the instructions in this code repository to implement this sample workflow in your own AWS account.
Processing outputs
The IPOPP package from NASA will produce several Level 2 data products. Here are two examples:

Cropped Active Fire (AF) locations image showing the south of France and Iberian Peninsula, produced using IPOPP’s VIIRS-AF SPA. The red circles indicate active fire areas of high confidence.
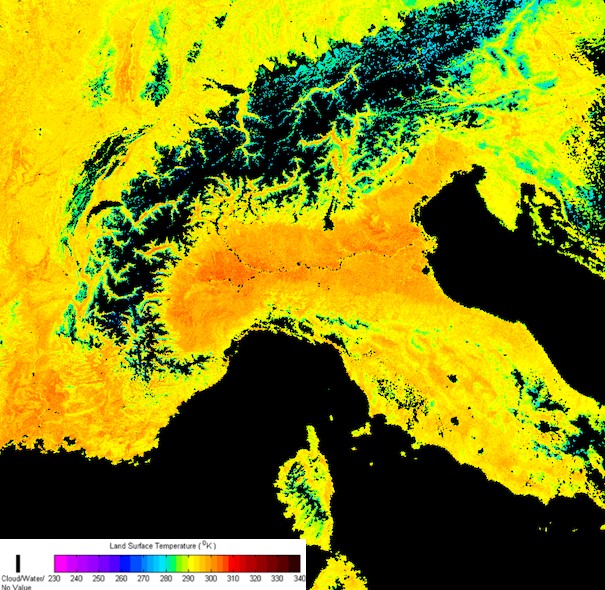
Cropped Land Surface Temperature (LST) image showing the north of Italy and the Alps, produced using IPOPP’s LST SPA. The warmer colors indicate higher absolute temperature in Kelvin on a March day.
Summary
This blog post presents an automated solution to schedule a satellite contact and have the resultant data asynchronously downlinked to an Amazon S3 bucket without spinning up a receiver Amazon EC2 instance. This solution downlinks data from the JPSS-1 craft and automatically processes it using NASA’s RT-STPS and IPOPP software. This automated pipeline architecture can be applied to data from any spacecraft.
Get started with Earth observation data and AWS Ground Station. Check out how you can process satellite imagery using a fully server-less architecture on AWS. And learn more about AWS Professional Services.