AWS Database Blog
Scale applications using multi-Region Amazon EKS and Amazon Aurora Global Database: Part 2
This is the second in a two-part series about scaling applications globally using multi-Region Amazon Elastic Kubernetes Service (Amazon EKS) and Amazon Aurora Global Database. In Part 1, you learned the architecture patterns and foundational pillars of a multi-Region application design. In this post, we use the read local and write global design pattern to scale, build resiliency and automatic failover of your multi-region applications using Amazon EKS, AWS Global Accelerator, and Aurora Global Database. This solution can benefit many industry verticals including retail and financial institutions such as banking, capital markets, fintech, insurance and payments, that are expanding globally. This post provides a template for how organizations can modernize and scale their applications into multiple Regions while providing a resiliency and disaster recovery strategy.
Overview of solution
The following architecture diagram shows the components used for this solution.
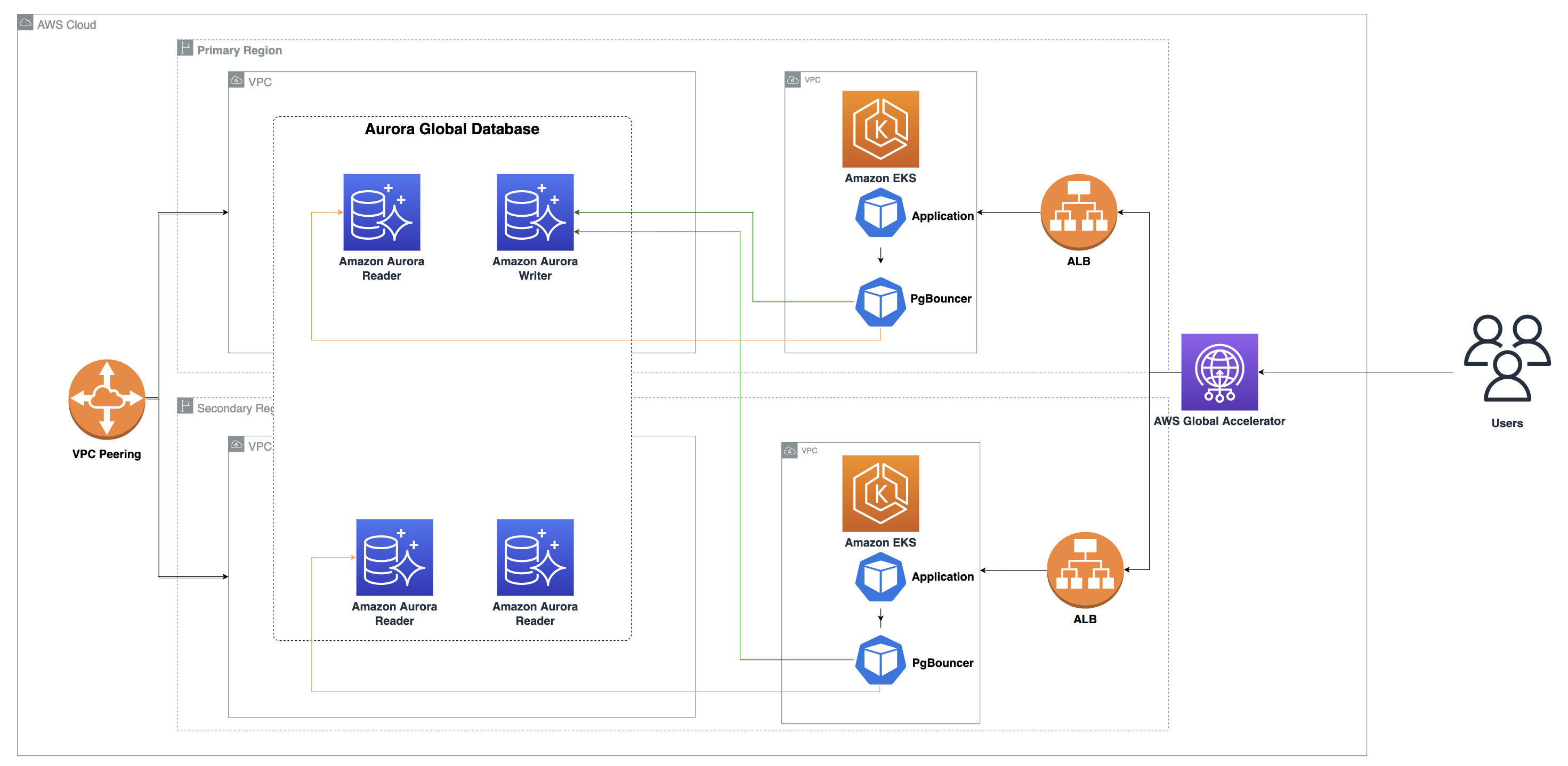
We configure both Regions using the local read and global write design pattern. We start by creating an Amazon EKS cluster and Amazon Aurora global database with PostgreSQL compatibility in Regions us-east-2 and us-west-2. We use PgBouncer, an open-source connection pooler, for both database connection pooling and handling planned Amazon Aurora global database failover. We then deploy the application stack, which includes stateless containerized applications, on EKS clusters in both Regions. We then expose the application endpoint using an Application Load Balancer in the respective Regions. Finally, we configure Global Accelerator for the load balancers as endpoints.
Prerequisites
To follow along with this tutorial, you should have the following prerequisites:
- An AWS account
- Git
- AWS Command Line Interface (CLI) version 2.9 or later installed and configured on your workstation
- Permission to create AWS resources (e.g., IAM Roles, IAM policies, Amazon EC2 instances, AWS Cloud9, Amazon Aurora DB clusters, and Amazon EKS clusters)
Deploy the solution
To deploy the solution, complete the following steps:
- First, we launch AWS CloudFormation stacks to setup the following resources in the
us-east-2andus-west-2Regions using AWS CloudShell:- An Amazon Aurora database cluster with a writer node in
us-east-2. - An Amazon Aurora global database with the secondary Region in
us-west-2. - VPC peering between
us-east-2andus-west-2to help our applications securely connect to the Amazon Aurora PostgreSQL-Compatible Edition database across Regions. You can also connect applications over private network using AWS Transit Gateway for intra-Region VPC peering. Please review Building a global network using AWS Transit Gateway Inter-Region peering for additional details. We use VPC peering for keeping this solution simple.Run the following from AWS CloudShell inus-east-2Region to set AWS access credentials, clone the git repository and launch AWS CloudFormation stacks. This step may take approximately 30 minutes.
- An Amazon Aurora database cluster with a writer node in
- Next, run the following to get the AWS Cloud9 URL information from the CloudFormation templates from both Regions
us-east-2andus-west-2: - Connect to the AWS Cloud9 terminal through a web browser for each Region using the preceding URL from Step 2.
- Choose Settings, AWS Settings, and disable AWS managed temporary credentials.

- Run the following code from both AWS Cloud9 terminals in both Regions, one at a time, to deploy the following resources:
- Amazon EKS clusters in both Regions
- Cluster Autoscaler, Horizontal Pod Autoscaler and AWS Load Balancer Controller on Amazon EKS on both Regions.
- Next, we deploy a PgBouncer database connection pooler and ClusterIP service for PgBouncer on Amazon EKS, and create a sample database schema on the Amazon Aurora PostgreSQL cluster. It also provisions retail application microservices to EKS clusters in
us-east-2andus-west-2. These micro services in both Regions use readers from local regional Aurora database clusters for reads for better performance.- Set up the PgBouncer database connection pooler deployment on Amazon EKS in both Regions.
- Set up retail application deployments on Amazon EKS in both Regions.
- Set up
ClusterIPservice for PgBouncer on Amazon EKS in both Regions. - Set up
Ingressfor retail application Pods on Amazon EKS in both Regions. - Set up an AWS Lambda function
AuroraGDBPgbouncerUpdateon both Regions to synchronize PgBouncer configuration with the respective Aurora writer endpoint and reader endpoints. - Set up an Amazon EventBridge event rule
AuroraGDBPgBouncerUpdateon the event busdefaulton both Regions on the event categoryglobal-failover(event IDRDS-EVENT-0185). The event rule uses the target as the Lambda functionAuroraGDBPgbouncerUpdateto synchronize the PgBouncer configuration when the Amazon Aurora global database is failed over across Regions. Please review Building an event-driven application with Amazon EventBridge post on how to scale applications using event driven architecture.Run the following from both AWS Cloud9 terminals on Regionsus-east-2andus-west-2, one at a time:The retail application deployment manifest consists of various microservices such as
webapp,product,order,user, andkart. It deploys Kubernetes servicesClusterIPfor internal microservices and aNodePortandIngressfor the external website-facing microservice. TheIngresscreates internet facing Application Load Balancer for our retail website application using an AWS Load Balancer controller.
- Next, run the following code from both AWS Cloud9 terminals on Regions
us-east-2andus-west-2: - Run the following on both Regions
us-east-2andus-west-2to verify the API health check using the/healthcheckcall:
Configure AWS Global Accelerator
Now that our retail application service works in both Regions, we need to direct Internet traffic to the application. Using DNS is one way to do this, but DNS can be problematic during failover events due to propagation times and client-side caching. For this solution, we chose to use AWS Global Accelerator, which can switch traffic routes without requiring DNS changes.
AWS Global Accelerator is a networking service that sends application traffic through AWS’s global network infrastructure, improving network performance by up to 60%. It also makes it easier to operate multi-regional deployments by providing two static IPs that are anycast from AWS’s globally distributed edge locations, giving you a single entry point to your application regardless of how many Regions it is deployed in.
- Run the following script on your AWS Cloud9 terminal on region
us-west-2. The script configures AWS Global Accelerator and return DNS name of your accelerator: - Next, you run the following API call
apiproducton AWS Cloud9 terminal on both Regionsus-east-2andus-west-2using AWS Global Accelerator DNS name from the previous step (Step 1). The API call returns the IP address of the Aurora writer node, reader node, and the application locality. The call is routed to our retail applicationwebappmicroservice to the closest region. The application uses the PgBouncer database connection pooler for database connection scaling. PgBouncer is configured with two databases: one for connecting to the writer node, which is an Aurora cluster endpoint in the primary regionus-east-2, and another one for the reader that connects to the Aurora reader endpoint in the local region that is local to the application.Run the following API call on your AWS Cloud9 terminal onus-east-2. The call is routed to the retail applicationwebappmicroservice onus-east-2: - Run the following API call on the AWS Cloud9 terminal on region
us-west-2. The call is routed to the retail application webapp microservice onus-west-2:In this example, the API call returns the application region and Amazon Aurora database writer and local reader endpoints. You should see a response originating from the region closest to you. AWS Global Accelerator sends traffic to the Amazon EKS cluster in the nearest AWS Region.
- Run the following API call on the AWS Cloud9 terminal on
us-east-2andus-west-2to ensure that application works fine and is able to retrieve product information and create new orders: - Use a web browser such as Chrome and open the retail application interface using the AWS Global Accelerator DNS name (from Step 1).
 The retail application has been deployed to both Regions and is fully functional. We now perform scalability and disaster recovery tests.
The retail application has been deployed to both Regions and is fully functional. We now perform scalability and disaster recovery tests.
Application scalability test
Kubernetes autoscaling mechanism offers node-based scaling using Cluster Autoscaler and pod-based scaling using Horizontal Pod Autoscaler (HPA). This example focuses on pod-based scaling using HPA.
To test for application scalability, we set up Horizontal Pod Autoscaler (HPA) for the retail application microservice deployment webapp on Amazon EKS and perform a synthetic load on the retail application using the Apache HTTP server benchmarking (ab) utility. The benchmark test uses 100 requests with 50 concurrent clients and runs for 300 seconds on our retail application website in us-east-2. This intense CPU stress test cause HPA to scale out application when its CPU threshold reach 50%.
- Run the following on your AWS Cloud9 terminal on both
us-east-2andus-west-2to create an auto scaler for theReplicaSetwebapp, with target CPU utilization set to 50% and the number of replicas between 2–20: - Next, run the following on an AWS Cloud9 terminal on
us-east-2to perform a stress test. Use two terminal windows on your AWS Cloud9 terminal onus-east-2: one to watch HPA and another to initiate a stress test. The HPA scales out webapp pods when its CPU threshold reaches 50% as per the configuration. It automatically scales back pods when the load subsides.In this example, the auto scaler (HPA) scaled out
webapppods from 2 to 13 as load increased on the retail application. It automatically scaled back pods to two when the load subsided. To automatically scale your database for high load scenarios, you can also use Aurora features such as Amazon Aurora Serverless v2 for on-demand and automatic vertical scaling, and Auto Scaling with Amazon Aurora replicas to scale out Amazon Aurora reader nodes, as the application increases load on the database.
Database cluster cross Region failover test
Next, we perform a managed planned failover for the Amazon Aurora global database to fail over the database cluster from us-east-2 to us-west-2 region. Following the failover, the application should continue to work fine and able to create and retrieve new orders.
- Run the following on your AWS Cloud9 terminal on
us-east-2to perform an Amazon Aurora global database failover:Next, make sure that the global database failover is completed successfully by checking the status.
- Run the following on your AWS Cloud9 terminal on
us-east-2to check the database events: - Next, ensure that the PgBouncer configuration in Amazon EKS on both Regions has been synchronized using the event rule and Lambda function. You should see Amazon Aurora cluster endpoint from
us-west-2region as host entry forgdbdemodatabase inpgbouncer.ini.Run the following on your AWS Cloud9 terminal onus-east-2to get the current cluster endpoint (writer node): - Run the following on your AWS Cloud9 terminal on both
us-east-2andus-west-2to check PgBouncer configuration (Use Global Accelerator DNS name from Step 1 for/apiproductAPI call): - Run the following on your AWS Cloud9 terminal on both Regions to ensure that the application works fine and is able to retrieve product information and create new orders, and confirm that the application works following the role transition:
In this example, the PgBouncer configuration has been automatically synchronized with new Amazon Aurora primary cluster endpoint following the Aurora global database failover. The database cluster role transition was transparent to our application and all the API calls to retail application works fine after the failover.
Cleanup
To clean up your resources, run the following on your AWS Cloud9 terminal in us-east-2 and us-west-2Regions:
Run the following from AWS CloudShell in us-west-2 Region:
Conclusion
In Part 1 of this series, you learned the architecture patterns and foundational pillars of a multi-Region application design. In this post, you learned how to do the following:
- Run and scale your applications in multiple Regions using Amazon EKS clusters and Aurora Global Database
- Improve multi-Region application resiliency using AWS Global Accelerator’s health checks to route the traffic to a Region in close proximity to end-users and also to detect failures and route traffic to a failover Region automatically
- Implement automatic configuration synchronization of a PgBouncer database connection pooler using Amazon EventBridge and event rules for Amazon Aurora global database failover events
- Ensure your application can transparently and automatically handle a managed planned Aurora global database cross-Region failover
We welcome your feedback; leave your comments or questions in the comments section.
We have adapted the concepts from this post into a deployable solution, now available as Guidance for Multi-Region Application Scaling Using Amazon Aurora in the AWS Solutions Library. To get started, review the architecture diagrams and the corresponding AWS Well-Architected framework, then deploy the sample code to implement the Guidance into your workloads.
Further reading
For more information, refer to the following:
- Creating a Multi-Region Application with AWS Services (Part 1, Part 2, and Part 3)
- Automated endpoint management for Amazon Aurora Global Database
- Deploying multi-region applications in AWS using AWS Global Accelerator
- Run an active-active multi-region Kubernetes application with AppMesh and EKS
About the Authors
 Krishna Sarabu is a Senior Database Specialist Solutions Architect with Amazon Web Services. He works with the Amazon RDS team, focusing on open-source database engines Amazon RDS for PostgreSQL and Amazon Aurora PostgreSQL. He has over 20 years of experience in managing commercial and open-source database solutions in the financial industry. He enjoys working with customers to help design, deploy, and optimize relational database workloads on AWS.
Krishna Sarabu is a Senior Database Specialist Solutions Architect with Amazon Web Services. He works with the Amazon RDS team, focusing on open-source database engines Amazon RDS for PostgreSQL and Amazon Aurora PostgreSQL. He has over 20 years of experience in managing commercial and open-source database solutions in the financial industry. He enjoys working with customers to help design, deploy, and optimize relational database workloads on AWS.
 Chirag Dave is a Senior Database Specialist Solutions Architect with Amazon Web Services, focusing on managed PostgreSQL. He maintains technical relationships with customers, making recommendations on security, cost, performance, reliability, operational efficiency, and best practice architectures.
Chirag Dave is a Senior Database Specialist Solutions Architect with Amazon Web Services, focusing on managed PostgreSQL. He maintains technical relationships with customers, making recommendations on security, cost, performance, reliability, operational efficiency, and best practice architectures.
 Raj Jayakrishnan is a Senior Database Specialist Solutions Architect with Amazon Web Services helping customers reinvent their business through the use of purpose-built database cloud solutions. Over 20 years of experience in architecting commercial & open-source database solutions in financial and logistics industry.
Raj Jayakrishnan is a Senior Database Specialist Solutions Architect with Amazon Web Services helping customers reinvent their business through the use of purpose-built database cloud solutions. Over 20 years of experience in architecting commercial & open-source database solutions in financial and logistics industry.