Amazon Web Services ブログ
Category: Amazon Quick Sight
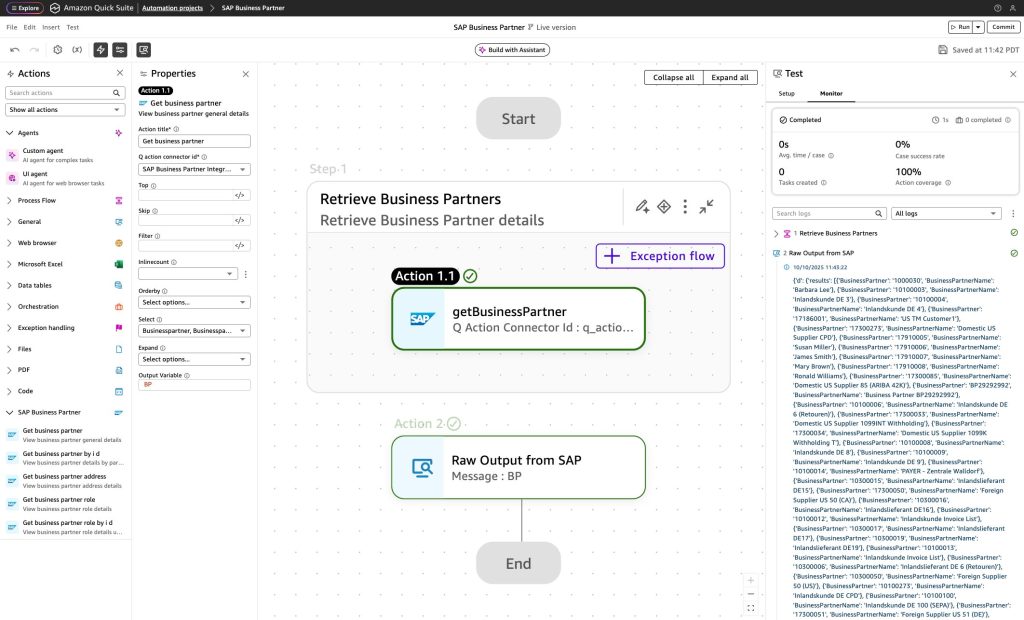
Amazon Quick AutomateでAI駆動のSAP自動化をシームレスに構築
このブログでは、Quick Suite内で利用可能なSAP用の組み込みコネクタと、お客様がAmazon Quick Automateを使用してこれらのコネクタを活用し、ビジネスオペレーションを合理化する強力な自動化を構築する方法について説明します。Quick Automateは、企業が大規模で回復力のある自動化を構築、展開、維持できるようにするQuick Suiteの機能です。AWS Action Connectors for SAPは、お客様がライブSAPデータに対してリアルタイムの読み取り操作を実行できるようにし、Quick AutomateがSAP S/4HANAなどのSAP ERPシステムとシームレスに対話できるようにします。

re:Invent 2025 クラウド財務管理セッション完全ガイド:参加前に押さえておきたいポイント
本投稿は、2025年 10 月 6 日に公開、11 月 3 日に更新された Your Ultimate Guide to Cloud Financial Management sessions at re:Invent 2025: Know Before You Go を翻訳したものです。
Cloud Financial Management (CFM) の学習とネットワーキングの時間を re:Invent 2025 で最大限に活用する準備はできていますか?例年通り、今年の CFM セッションを最大限に活用し、スケジュールを計画するための包括的なガイドを作成しました。今年のカタログには、ブレイクアウト、チョークトーク、ワークショップ、ビルダーズセッション、コードトークなど、さまざまな形式のコンテンツがエキサイティングに組み合わされています。
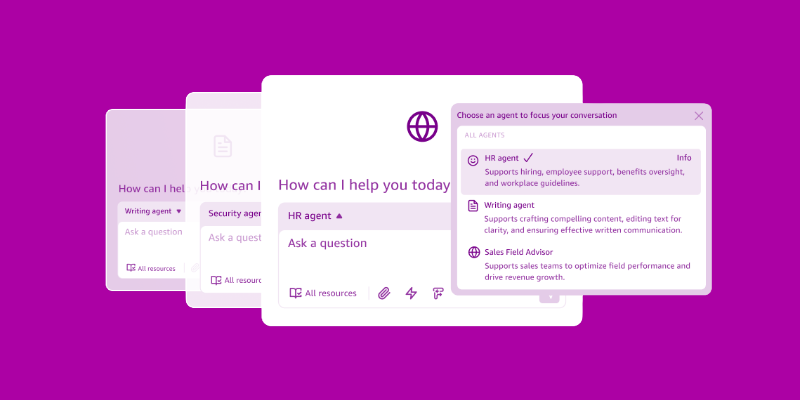
質問への回答とアクションを実行するエージェント型チームメイト Amazon Quick Suite の発表
Amazon Quick Suiteを発表しました。これは、仕事における質問への回答やアクションの実行を支援する新しいAIベースのツールスイートです。
このツールスイートにより、ユーザーは複数のアプリケーションを行き来することなく、単一のワークスペースでAIサポートによるリサーチ、ビジネスインテリジェンス、自動化機能を活用できるようになります。

re:Invent 2025 で学ぶ AI を活用した運用管理の構築方法
組織がクラウド環境を拡大し進化させ続ける中、効果的な運用管理はこれまで以上に重要になっています。AWS re:Invent 2025 の Cloud Operations トラックにおける運用管理セッションは、AWS 環境全体で回復力があり、セキュアで効率的な運用プラクティスを構築するのに役立つ包括的なラインナップを提供します。複雑なマルチクラウド環境の管理、AI を活用した自動化の実装、災害復旧戦略の強化など、このトラックはあらゆる方々にコンテンツを提供します。
このブログでは、運用管理における主要テーマを紹介し、クラウド運用戦略を変革するのに役立つセッションを紹介します。

D2L が Amazon Quick Sight のビジュアルデータ準備を使用して教育分析を変革した方法
本ブログでは、D2L が Amazon Quick Sight の新しいデータ準備機能を活用し、Performance+ パッケージの Brightspace Analytics 機能を強化した事例をご紹介します。この取り組みにより、教育機関全体でデータインサイトが民主化され、技術的な専門知識を必要とせず、シンプルなクリック操作だけで教育者や管理者が生データを実用的なインサイトに変換できるようになりました。QuickSight の新しいデータ準備エクスペリエンスは、データ変換のための視覚的でローコードなインターフェースを提供することで、技術的な障壁を取り除き、あらゆるスキルレベルのユーザーがデータを直接扱えるようにし、D2L の教育分析アプローチに革命をもたらしました。

Amazon Quick Sight を使用して SQL なしでデータ準備フローを構築する
本ブログでは、中堅小売企業である AnyCompany が、新しい Quick Sight データ準備エクスペリエンスを使用して、ビジネスアナリストが SQL を一行も書くことなく複雑なデータを変換する方法をご紹介します。ステップバイステップのビジュアルインターフェースは、組織がデータを扱う方法を変革し、追加、結合、ピボット解除、集計などの機能を提供することで、技術的な専門知識を持たないユーザーでもデータ変換を利用できるようにする直感的なポイント&クリックインターフェースを通じて、実際のデータ課題を解決します。

Amazon Quick Sight の軸とデータラベルのフォントカスタマイズによるダッシュボードデザインの拡張
本ブログでは、Amazon Quick Sight ビジュアルの軸とデータラベルに対する新しいフォントカスタマイズ機能について、読みやすくブランドに一貫性のあるダッシュボードを作成するための手順とベストプラクティスを含めて説明します。これらの機能強化により、フォントサイズ、フォントファミリーの選択、テキストスタイルオプション、カスタムカラーをピクセルレベルで制御でき、ダッシュボードのビジュアルデザインを微調整し、エンドユーザーの可読性を向上させることができます。

カスタムパーミッションを使用した Amazon Quick Suite 機能のガバナンス自動化
本ブログでは、Amazon Quick Suiteのカスタム権限を使用してアカウントレベルで機能レベルの制限をプログラムで実装する方法を実証し、組織がエンタープライズグレードのセキュリティとコンプライアンスを維持しながら生成AIの最新イノベーションを採用できるよう支援します。CloudTrail、EventBridge、Lambda、CloudFormationなどのAWSサービスを使用して、新規および既存のQuick Suiteアカウントサブスクリプションの両方でアカウントレベルのAIベース機能をオフにするためにカスタム権限を適用する方法を説明します。
株式会社マキタ様の AWS 生成 AI 事例「AWS 上の閉鎖型 AI 環境で労働災害報告書作成支援と経営ダッシュボードを内製開発。システム開発経験の少ないエンジニアが短期間でリリースを実現」のご紹介
本ブログは 株式会社 マキタ様 と Amazon Web Services Japan 合同会社 が共同で執筆 […]

Amazon Connect Cost Insight Dashboard によるコストの可視化と最適化
コンタクトセンターのリーダーは常にコストの可視化を求めています。この記事ではコンタクトセンターのコスト情報を可視化する Amazon Connect Cost Insight Dashboard について紹介しています。このダッシュボードは月次コストトレンドの追跡、サービスコンポーネント別のコスト分析、通話料の分析などの機能を提供し、コンタクトセンターマネージャーが情報に基づいた適切な意思決定を行い、運用を最適化するためのデータを提供します。