Amazon Web Services ブログ
Category: AWS Glue

アプリケーションを変更せずに Amazon SageMaker Catalog でデータメッシュパターンを実装する
Amazon SageMaker Catalog を使用してデータメッシュパターンを実装する方法を説明します。既存のアプリケーションやデータリポジトリを変更せずに、Amazon SageMaker Unified Studio でデータをオンボード、公開、サブスクライブする手順を紹介します。

AWS で DER アグリゲーター向けのスケーラブルな DERMS ソリューションを構築する
エネルギー環境が分散型モデルへと進化する中、分散型エネルギーリソース (DER) は、エネルギー市場のさまざまなプレーヤー (電力会社、立法機関、アグリゲーター、消費者、サービスプロバイダー) に課題と機会の両方をもたらしています。
さまざまな関係者が Amazon Web Services (AWS) を活用して DER を最大限に活用する方法について、一連のブログを計画しています。最初のブログでは、アグリゲーターが事業の成長に合わせて拡張できる堅牢な分散型エネルギーリソース管理システム (DERMS) を構築するために、AWS サービスがどのように役立つかを探ります。

AWS Glue 5.0 の Apache Spark におけるオープンテーブルフォーマット機能の活用
この記事では、AWS Glue 5.0 における Apache Iceberg、Delta Lake、Apache Hudi のオープンテーブルフォーマットライブラリの主要なアップデートについて解説します。ブランチとタグによるライフサイクル管理、変更ログビュー、ストレージパーティション結合などの新機能を紹介します。

AWS Glue Data Catalog のテーブル統計自動収集機能の紹介 – Amazon Redshift と Amazon Athena のクエリパフォーマンス向上
AWS Glue Data Catalog で、新しいテーブルの統計情報を自動的に生成できるようになりました。この機能により、Amazon Redshift Spectrum と Amazon Athena のコストベースオプティマイザー (CBO) がクエリを最適化し、パフォーマンス向上とコスト削減を実現します。
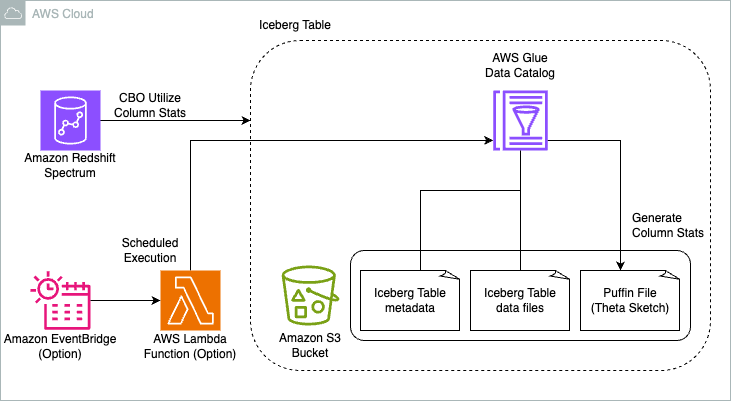
AWS Glue Data Catalog で Apache Iceberg 統計情報を収集してクエリパフォーマンスを高速化する
AWS Glue Data Catalog で Apache Iceberg テーブルのカラムレベル統計情報を生成し、Redshift Spectrum と Amazon Athena のクエリパフォーマンスを最大 83% 向上させる方法を紹介します。

AWS Glue Data Catalog での Apache Iceberg マテリアライズドビューのご紹介
AWS は AWS Glue Data Catalog の Apache Iceberg テーブル向けの新しいマテリアライズドビュー機能を発表しました。この機能により、データパイプラインを簡素化し、事前計算結果を保存してクエリパフォーマンスを向上させることができます。Amazon Athena、Amazon EMR、AWS Glue の Spark エンジンがこの新機能をサポートしています。

Amazon FSx for NetApp ONTAP が Amazon S3 と統合され、シームレスなデータアクセスが可能になりました
2025 年 12 月 2 日、Amazon Simple Storage Service (Amazon S […]
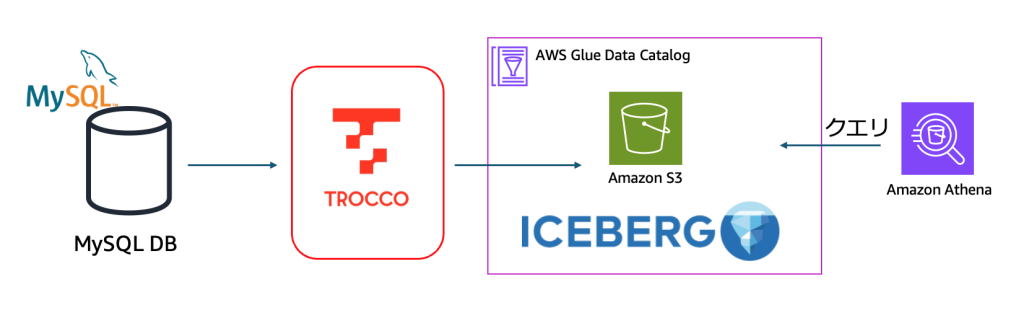
TROCCO の CDC 機能をつかった RDB と Apache Iceberg on AWS の連携
データベースの変更をリアルタイムに分析基盤へ反映したいというニーズに高まりを感じています。実際に多くのお客様から相談をいただいております。またデータベースの差分をもとに連携することが望まれる場面も多くあります。そういう場合の選択肢の一つが CDC(Change Data Capture)と呼ばれる MySQL の binlogなどの変更履歴をもとにデータを連携する手法になります。しかし、CDC での実装は、データ取得・キャッシュレイヤー・コンシューマーの実装とコンポーネントが多くなる場合も多く技術的なハードルが高く、ソースデータベースのスキーマの変更をターゲットの分析基盤に滞りなく連携する必要があるなど運用負荷も大きいワークロードになります。
CDC のターゲットの選択肢の1つとして、Iceberg を利用することで多様なエンジンから利用することができ、ソーススキーマの変更にも柔軟に対応ができるコスト効率の良い、DB のデータをソースにしたデータレイクハウスを構築することができます。
本記事では、AWS パートナーである primeNumber 社が提供するデータ統合プラットフォーム「TROCCO」の CDC 機能を使って、MySQL から AWS 上の Apache Iceberg テーブルへのリアルタイムレプリケーションを実現する方法をご紹介します。実際に検証した内容をもとに、セットアップから運用まで詳しく解説していきます。
AWS Glue zero-ETLによるSAPデータの取り込みとレプリケーション
AWS Glue zero-ETLは、SAP BW、ABAP、CDSビューなどのODP対応・非対応データソースからのデータ取り込みとレプリケーションを実現するサービスです。抽出されたデータはAmazon Redshift、Amazon SageMaker lakehouseアーキテクチャ、Amazon S3 Tablesに書き込まれ、Amazon QやAmazon Quick Suiteと組み合わせることで、自然言語クエリによるSAPデータ分析、AIエージェントの自動化、企業データ全体にわたるコンテキストインサイトの生成が可能になります。

AWS Glue Data Catalog での Apache Iceberg テーブルのカタログフェデレーションの紹介
Apache Iceberg は、大規模で堅牢かつ信頼性の高い分析を求める組織にとって、オープンテーブルフォーマットの標準的な選択肢となっています。しかし、企業は異なるカタログシステムを持つ複雑なマルチベンダー環境をますます多く扱うようになっています。マルチベンダー環境で運用する組織にとって、これらのシステム間でデータを管理することは大きな課題となっています。この断片化は、特にアクセス制御とガバナンスに関して、運用上の複雑さを大幅に増加させます。Amazon Redshift、Amazon EMR、Amazon Athena、Amazon SageMaker、AWS Glue などの AWS 分析サービスを使用して AWS Glue Data Catalog 内の Iceberg テーブルを分析しているお客様は、リモートカタログのワークロードでも同じ価格性能を得たいと考えています。これらのリモートカタログを単純に移行または置き換えることは現実的ではなく、チームはシステム間でメタデータを継続的に複製する同期プロセスを実装・維持する必要があり、運用上のオーバーヘッド、コストの増加、データの不整合のリスクが生じます。