Amazon Web Services ブログ
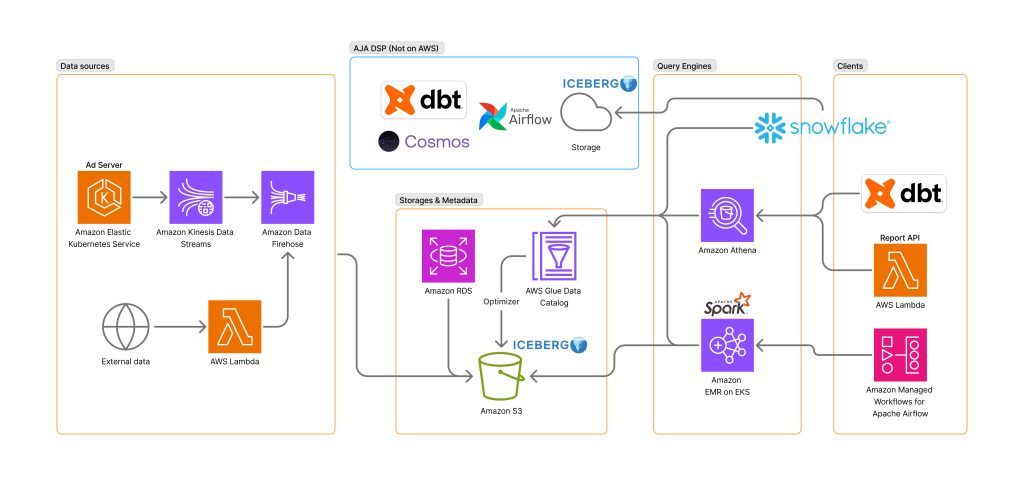
AJA SSP が Apache Iceberg と AWS Glue Data Catalog でペタバイトスケールのデータ基盤の柔軟なクエリエンジンの選択とクエリの高速化を実現
※ この記事はお客様に寄稿いただき、AWS が加筆・修正したものとなっています。 株式会社 AJA は、株式会 […]

AWS Weekly Roundup: OpenAI モデル、自動推論チェック、Amazon EVS など (2025 年 8 月 11 日)
北半球の AWS Summit はほぼ終了しましたが、地球のそれ以外の地域にいる私たちにとって、楽しみと学習は […]

Amazon EKS Auto Mode ワークショップの紹介
効率化された運用による Kubernetes アプリケーションのデプロイと管理の実践的な経験を積みましょう。Auto Mode の有効化、最小限の設定でのアプリケーションデプロイ、組み込み機能の探索、クラスターアップグレードの簡素化、既存ワークロードの移行について学習します。
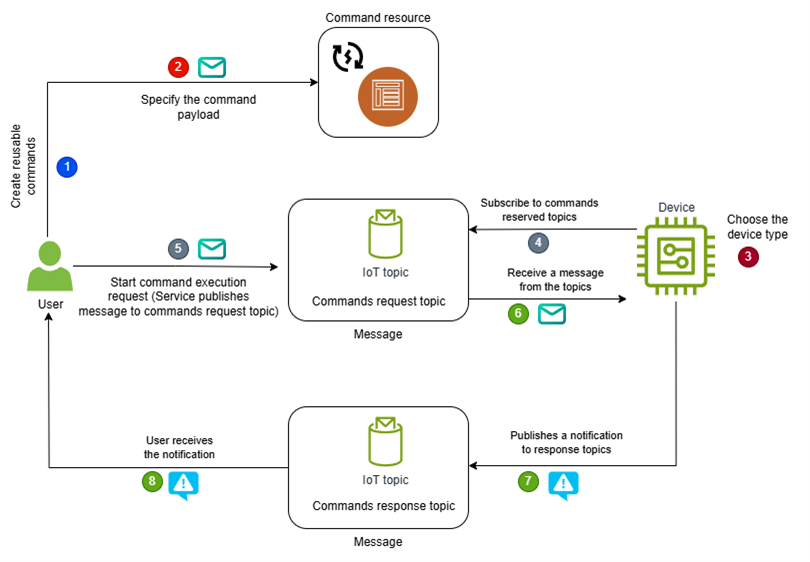
AWS IoT Device Management のコマンド機能を使用して IoT Device のリモートアクションを簡単化する
はじめに 高度に接続された現代社会では、モノのインターネット(IoT)機器が、家庭やオフィス、産業との関わり方 […]

マルチクラウド戦略を成功させるための実証済みのプラクティス
マルチクラウドアプローチを成功させるには、既存のツールや将来の選択肢と シームレスに 連携するクラウドプラットフォームが必要です。他のクラウドサービスプロバイダの機能を追加する際に、すべてを再構築する必要はありません。また、すべてのプラットフォームのエキスパートになる必要もありません。
本記事ではお客様との経験に基づき、マルチクラウド戦略を成功させるための実証済みのプラクティスをご紹介します。
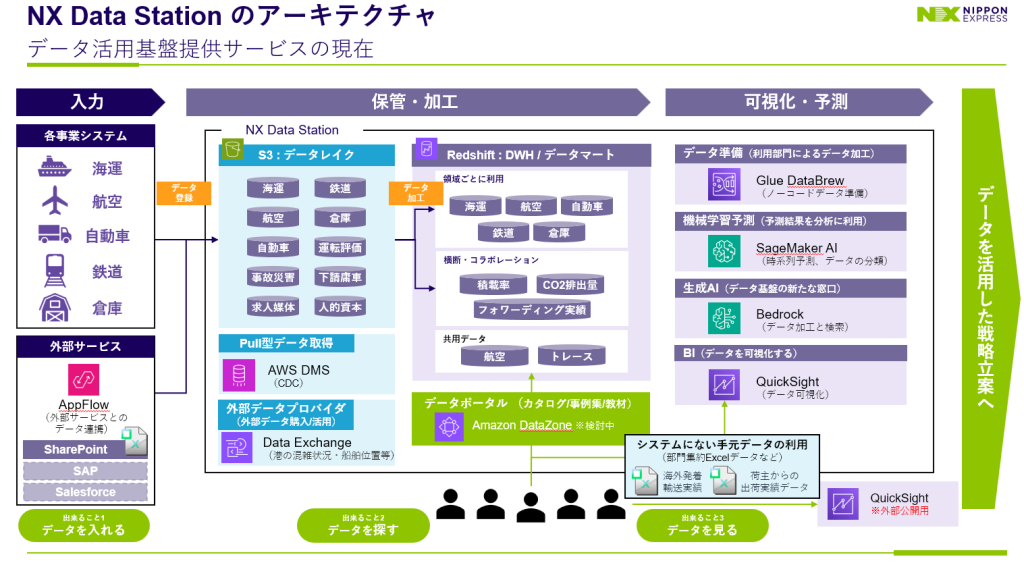
物流業界のチャレンジを支えるデータ活用 – Nippon Express の事例から
物流業界において、特にデータを活用した改善は、物流DXとして総合物流施策大綱でも長年にわたり強く推奨されてきました。このような状況を受けて多くの物流企業がデータ活用を経営戦略の重要項目として位置付けているものの、実態としては有効な施策が打ち出せずにいるケースが多く見受けられます。
本記事ではそういった課題に悩まれる物流事業担当者向けに、データ活用の成功モデルとして日本通運株式会社(以下Nippon Express)のデータ分析基盤「NX Data Station」を解説します。同社は既存リソースを最大限に活用しながら、コスト効果の高いデータ分析基盤を構築し、データを基に業務効率化と意思決定の質向上を実現しています。
記事は2025年7月15日に開催された Amazon SageMaker Roadshow でのNX情報システム および キヤノンITソリューションズ のセッション内容をもとに記載しています。

週刊AWS – 2025/8/4週
Amazon ECRの1リポジトリあたりのイメージ上限が10万個に拡大、Amazon SQSの最大メッセージサイズが1MiBに拡大、Amazon EVSが一般提供開始、OpenAIのオープンウェイトモデルがBedrock/JumpStartで利用可能に、Amazon EKSでクラスター削除保護機能追加 他

2025 年 6 月 と 7 月の AWS Black Belt オンラインセミナー資料及び動画公開のご案内
2025 年 6月から 7 月に公開された AWS Black Belt オンラインセミナーの資料及び動画についてご案内させて頂きます。
動画はオンデマンドでご視聴いただけます。

業界タスク特化型⼤規模⾔語モデルの開発 〜 野村総合研究所様へのインタビュー 〜
みなさん、こんにちは。アマゾン ウェブ サービス (AWS) ジャパン合同会社 AI / ML 事業開発チーム […]

経済産業省 GENIAC 基盤モデル開発支援事業 (第3期) における採択事業者への支援を開始
2025年7月4日、経済産業省と国立研究開発法人新エネルギー・産業技術総合開発機構 (NEDO) が実施する […]