Amazon Web Services ブログ

AWS Systems Manager Incident Manager からのインシデントレポートを自動化
システムの信頼性を維持し、予期せぬインシデントに迅速に対応するためには、効果的なインシデント管理が重要です。インシデントライフサイクルの一環として、組織がインシデントの過去データを収集し、振り返って事後分析を行う必要があります。このブログでは、スケジュールに従って Incident Manager のレポートを生成し、Amazon Simple Storage Service (Amazon S3) に保存する方法を説明します。

寄稿:レンゴーが実践するDX人材育成 – Amazon 流の考え方とパートナー活用 –
レンゴー株式会社について レンゴーは、たゆまぬ意識改革とイノベーションを通じて、あらゆる産業のすべての包装ニー […]
Amazon FSx for Lustre のスケーラブルなメタデータパフォーマンスでファイルシステムワークロードのより高いパフォーマンスを実現
映画スタジオのように、膨大な量のビデオファイル、スクリプト、アニメーションアセットを扱う会社を想像してみてくだ […]

Amazon Q のコスト最適化
AWS の生成 AI コスト最適化に関する全 5 回構成シリーズ の 4 回目のブログでは、前回までの議論を踏 […]

Amazon Connect の運用に役立つ机上演習とは
コンタクトセンター運用において、予期せぬサービス中断は深刻な影響を及ぼす可能性があります。この記事ではコンタクトセンター環境で発生する可能性のある問題に対処する、Amazon Connect の 11 種類の机上演習シナリオを紹介します。各シナリオの手順を通じて、運用管理者や技術者が実践的なトラブルシューティングスキルを習得し、より効果的な Amazon Connect の運用管理を実現できます。

Amazon DynamoDB グローバルテーブルのマルチリージョン強整合性を活用することで、最高水準の耐障害性を備えたアプリケーションを安心して構築いただけます
数万人の顧客が Amazon DynamoDB のグローバルテーブルを最終的整合性で正常に使用していますが、さ […]

最大 600 Gbps のネットワーク帯域幅を提供する AWS Graviton4 搭載の新しい Amazon EC2 C8gn インスタンス
6 月 30 日、AWS Graviton4 プロセッサと最新の第 6 世代 AWS Nitro Card を […]
ユーザックシステム株式会社様:非定型の受注業務の自動化にAmazon Bedrockを活用し「Knowfa 受注AIエージェント」を開発。受注業務の80%自動化に成功
本ブログはユーザックシステム株式会社様と Amazon Web Services Japan 合同会社が共同で […]
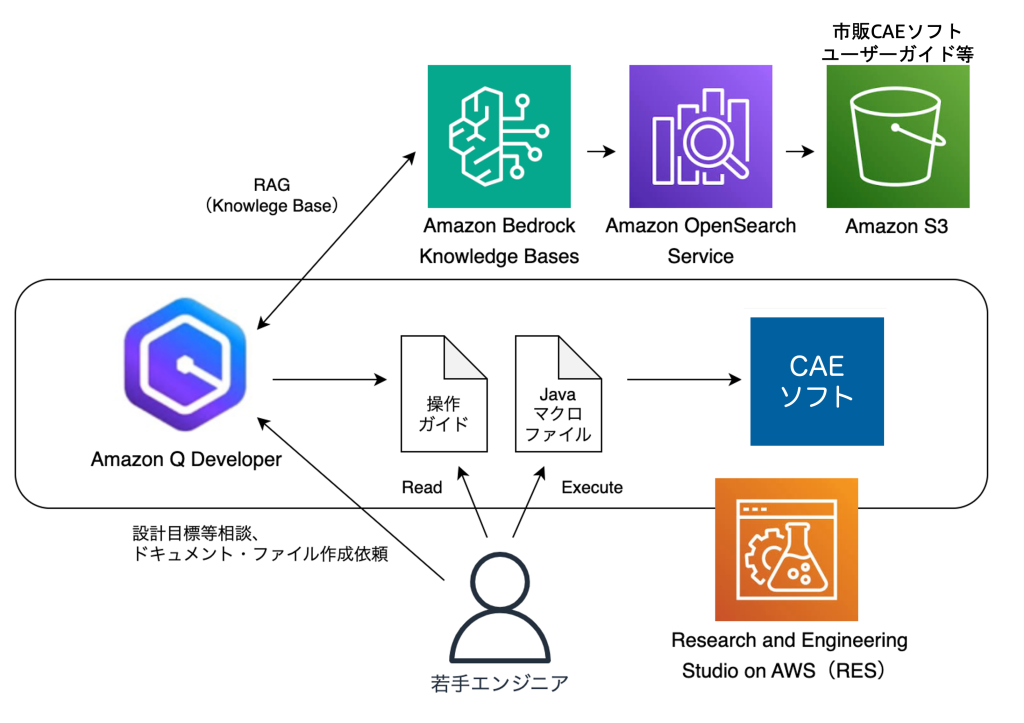
Research and Engineering Studio on AWS (RES) による CAD / CAE 環境の最適化
みなさん、こんにちは!製造業のお客様を中心に技術支援を行っているソリューションアーキテクトの山田です。 AWS […]

AWS Weekly Roundup: Project Rainier、Amazon CloudWatch 調査、AWS MCP サーバーなど (2025 年 6 月 30 日)
私がシアトルを訪れるたびに空港で最初に出迎えてくれるのは、レーニア山です。Amazon Web Service […]